 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCER-HV: A CER-Based Human-in-the-Loop Framework for Cleaning Datasets Applied to Arabic-Script HTR
Jan 23, 2026Handwritten text recognition (HTR) for Arabic-script languages still lags behind Latin-script HTR, despite recent advances in model architectures, datasets, and benchmarks. We show that data quality is a significant limiting factor in many published datasets and propose CER-HV (CER-based Ranking with Human Verification) as a framework to detect and clean label errors. CER-HV combines a CER-based noise detector, built on a carefully configured Convolutional Recurrent Neural Network (CRNN) with early stopping to avoid overfitting noisy samples, and a human-in-the-loop (HITL) step that verifies high-ranking samples. The framework reveals that several existing datasets contain previously underreported problems, including transcription, segmentation, orientation, and non-text content errors. These have been identified with up to 90 percent precision in the Muharaf and 80-86 percent in the PHTI datasets. We also show that our CRNN achieves state-of-the-art performance across five of the six evaluated datasets, reaching 8.45 percent Character Error Rate (CER) on KHATT (Arabic), 8.26 percent on PHTI (Pashto), 10.66 percent on Ajami, and 10.11 percent on Muharaf (Arabic), all without any data cleaning. We establish a new baseline of 11.3 percent CER on the PHTD (Persian) dataset. Applying CER-HV improves the evaluation CER by 0.3-0.6 percent on the cleaner datasets and 1.0-1.8 percent on the noisier ones. Although our experiments focus on documents written in an Arabic-script language, including Arabic, Persian, Urdu, Ajami, and Pashto, the framework is general and can be applied to other text recognition datasets.
Trends and Challenges in Authorship Analysis: A Review of ML, DL, and LLM Approaches
May 21, 2025



Authorship analysis plays an important role in diverse domains, including forensic linguistics, academia, cybersecurity, and digital content authentication. This paper presents a systematic literature review on two key sub-tasks of authorship analysis; Author Attribution and Author Verification. The review explores SOTA methodologies, ranging from traditional ML approaches to DL models and LLMs, highlighting their evolution, strengths, and limitations, based on studies conducted from 2015 to 2024. Key contributions include a comprehensive analysis of methods, techniques, their corresponding feature extraction techniques, datasets used, and emerging challenges in authorship analysis. The study highlights critical research gaps, particularly in low-resource language processing, multilingual adaptation, cross-domain generalization, and AI-generated text detection. This review aims to help researchers by giving an overview of the latest trends and challenges in authorship analysis. It also points out possible areas for future study. The goal is to support the development of better, more reliable, and accurate authorship analysis system in diverse textual domain.
Data Bias According to Bipol: Men are Naturally Right and It is the Role of Women to Follow Their Lead
Apr 07, 2024
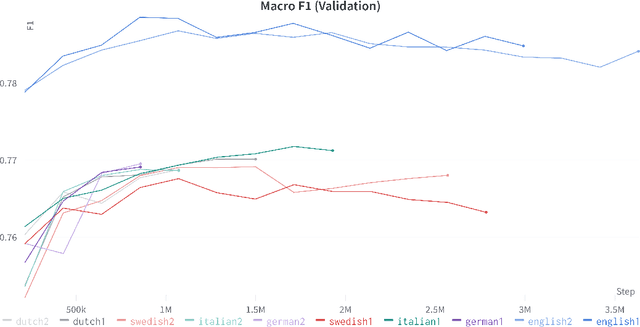
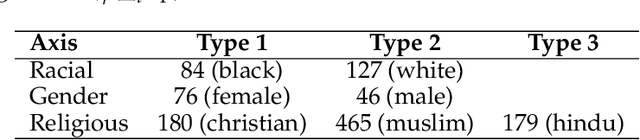
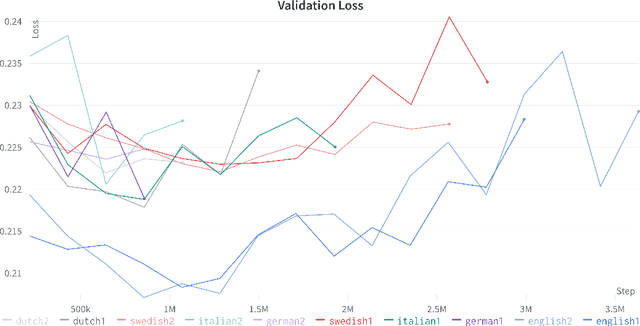
We introduce new large labeled datasets on bias in 3 languages and show in experiments that bias exists in all 10 datasets of 5 languages evaluated, including benchmark datasets on the English GLUE/SuperGLUE leaderboards. The 3 new languages give a total of almost 6 million labeled samples and we benchmark on these datasets using SotA multilingual pretrained models: mT5 and mBERT. The challenge of social bias, based on prejudice, is ubiquitous, as recent events with AI and large language models (LLMs) have shown. Motivated by this challenge, we set out to estimate bias in multiple datasets. We compare some recent bias metrics and use bipol, which has explainability in the metric. We also confirm the unverified assumption that bias exists in toxic comments by randomly sampling 200 samples from a toxic dataset population using the confidence level of 95% and error margin of 7%. Thirty gold samples were randomly distributed in the 200 samples to secure the quality of the annotation. Our findings confirm that many of the datasets have male bias (prejudice against women), besides other types of bias. We publicly release our new datasets, lexica, models, and codes.
On the Limitations of Large Language Models : False Attribution
Apr 06, 2024



In this work, we provide insight into one important limitation of large language models (LLMs), i.e. false attribution, and introduce a new hallucination metric - Simple Hallucination Index (SHI). The task of automatic author attribution for relatively small chunks of text is an important NLP task but can be challenging. We empirically evaluate the power of 3 open SotA LLMs in zero-shot setting (LLaMA-2-13B, Mixtral 8x7B, and Gemma-7B), especially as human annotation can be costly. We collected the top 10 most popular books, according to Project Gutenberg, divided each one into equal chunks of 400 words, and asked each LLM to predict the author. We then randomly sampled 162 chunks for human evaluation from each of the annotated books, based on the error margin of 7% and a confidence level of 95% for the book with the most chunks (Great Expectations by Charles Dickens, having 922 chunks). The average results show that Mixtral 8x7B has the highest prediction accuracy, the lowest SHI, and a Pearson's correlation (r) of 0.737, 0.249, and -0.9996, respectively, followed by LLaMA-2-13B and Gemma-7B. However, Mixtral 8x7B suffers from high hallucinations for 3 books, rising as high as an SHI of 0.87 (in the range 0-1, where 1 is the worst). The strong negative correlation of accuracy and SHI, given by r, demonstrates the fidelity of the new hallucination metric, which is generalizable to other tasks. We publicly release the annotated chunks of data and our codes to aid the reproducibility and evaluation of other models.
Instruction Makes a Difference
Feb 01, 2024We introduce Instruction Document Visual Question Answering (iDocVQA) dataset and Large Language Document (LLaDoc) model, for training Language-Vision (LV) models for document analysis and predictions on document images, respectively. Usually, deep neural networks for the DocVQA task are trained on datasets lacking instructions. We show that using instruction-following datasets improves performance. We compare performance across document-related datasets using the recent state-of-the-art (SotA) Large Language and Vision Assistant (LLaVA)1.5 as the base model. We also evaluate the performance of the derived models for object hallucination using the Polling-based Object Probing Evaluation (POPE) dataset. The results show that instruction-tuning performance ranges from 11X to 32X of zero-shot performance and from 0.1% to 4.2% over non-instruction (traditional task) finetuning. Despite the gains, these still fall short of human performance (94.36%), implying there's much room for improvement.
ProCoT: Stimulating Critical Thinking and Writing of Students through Engagement with Large Language Models (LLMs)
Dec 15, 2023We introduce a novel writing method called Probing Chain of Thought (ProCoT), which prevents students from cheating using a Large Language Model (LLM), such as ChatGPT, while enhancing their active learning through such models. LLMs have disrupted education and many other feilds. For fear of students cheating, many educationists have resorted to banning their use, as their outputs can be human-like and hard to detect in some cases. These LLMs are also known for hallucinations (i.e. fake facts). We conduct studies with ProCoT in two different courses with a combined total of about 66 students. The students in each course were asked to prompt an LLM of their choice with one question from a set of four and required to affirm or refute statements in the LLM output by using peer reviewed references. The results show two things: (1) ProCoT stimulates creative/critical thinking and writing of students through engagement with LLMs when we compare the LLM solely output to ProCoT output and (2) ProCoT can prevent cheating because of clear limitations in existing LLMs when we compare students ProCoT output to LLM ProCoT output. We also discover that most students prefer to give answers in fewer words than LLMs, which are typically verbose. The average word counts for students, ChatGPT (v3.5) and Phind (v8) are 208, 391 and 383, respectively.