 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExperimental End-to-End Optimization of Directly Modulated Laser-based IM/DD Transmission
Aug 27, 2025Directly modulated lasers (DMLs) are an attractive technology for short-reach intensity modulation and direct detection communication systems. However, their complex nonlinear dynamics make the modeling and optimization of DML-based systems challenging. In this paper, we study the end-to-end optimization of DML-based systems based on a data-driven surrogate model trained on experimental data. The end-to-end optimization includes the pulse shaping and equalizer filters, the bias current and the modulation radio-frequency (RF) power applied to the laser. The performance of the end-to-end optimization scheme is tested on the experimental setup and compared to 4 different benchmark schemes based on linear and nonlinear receiver-side equalization. The results show that the proposed end-to-end scheme is able to deliver better performance throughout the studied symbol rates and transmission distances while employing lower modulation RF power, fewer filter taps and utilizing a smaller signal bandwidth.
Experimental Demonstration of End-to-End Optimization for Directly Modulated Laser-based IM/DD Systems
Oct 23, 2024

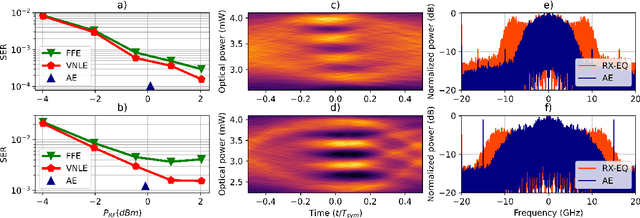
We experimentally demonstrate the joint optimization of transmitter and receiver parameters in directly modulated laser systems, showing superior performance compared to nonlinear receiver-only equalization while using fewer memory taps, less bandwidth, and lower radiofrequency power.
ProCoT: Stimulating Critical Thinking and Writing of Students through Engagement with Large Language Models (LLMs)
Dec 15, 2023We introduce a novel writing method called Probing Chain of Thought (ProCoT), which prevents students from cheating using a Large Language Model (LLM), such as ChatGPT, while enhancing their active learning through such models. LLMs have disrupted education and many other feilds. For fear of students cheating, many educationists have resorted to banning their use, as their outputs can be human-like and hard to detect in some cases. These LLMs are also known for hallucinations (i.e. fake facts). We conduct studies with ProCoT in two different courses with a combined total of about 66 students. The students in each course were asked to prompt an LLM of their choice with one question from a set of four and required to affirm or refute statements in the LLM output by using peer reviewed references. The results show two things: (1) ProCoT stimulates creative/critical thinking and writing of students through engagement with LLMs when we compare the LLM solely output to ProCoT output and (2) ProCoT can prevent cheating because of clear limitations in existing LLMs when we compare students ProCoT output to LLM ProCoT output. We also discover that most students prefer to give answers in fewer words than LLMs, which are typically verbose. The average word counts for students, ChatGPT (v3.5) and Phind (v8) are 208, 391 and 383, respectively.
Differentiable Machine Learning-Based Modeling for Directly-Modulated Lasers
Sep 27, 2023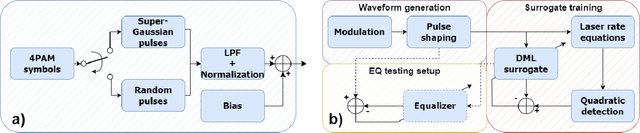
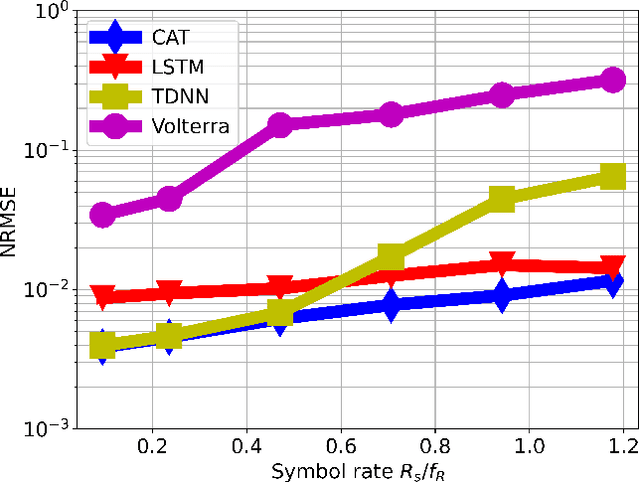
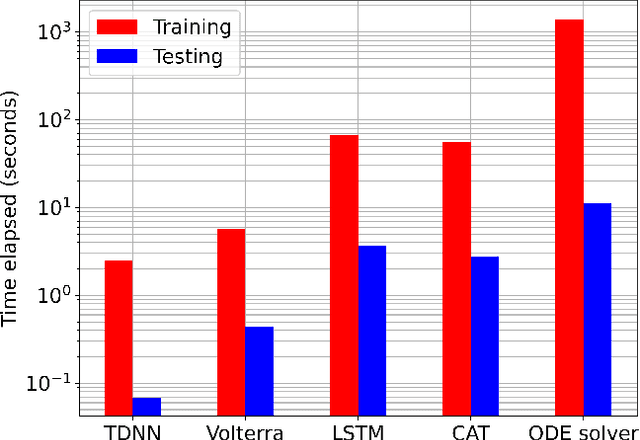

End-to-end learning has become a popular method for joint transmitter and receiver optimization in optical communication systems. Such approach may require a differentiable channel model, thus hindering the optimization of links based on directly modulated lasers (DMLs). This is due to the DML behavior in the large-signal regime, for which no analytical solution is available. In this paper, this problem is addressed by developing and comparing differentiable machine learning-based surrogate models. The models are quantitatively assessed in terms of root mean square error and training/testing time. Once the models are trained, the surrogates are then tested in a numerical equalization setup, resembling a practical end-to-end scenario. Based on the numerical investigation conducted, the convolutional attention transformer is shown to outperform the other models considered.