 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWordStylist: Styled Verbatim Handwritten Text Generation with Latent Diffusion Models
Mar 29, 2023
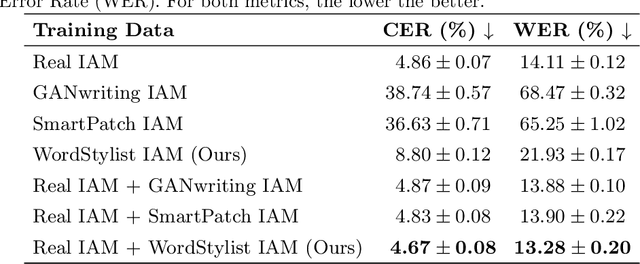
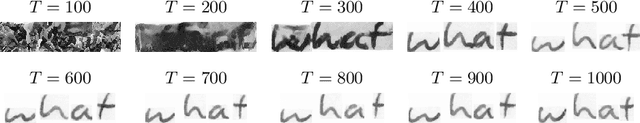

Text-to-Image synthesis is the task of generating an image according to a specific text description. Generative Adversarial Networks have been considered the standard method for image synthesis virtually since their introduction; today, Denoising Diffusion Probabilistic Models are recently setting a new baseline, with remarkable results in Text-to-Image synthesis, among other fields. Aside its usefulness per se, it can also be particularly relevant as a tool for data augmentation to aid training models for other document image processing tasks. In this work, we present a latent diffusion-based method for styled text-to-text-content-image generation on word-level. Our proposed method manages to generate realistic word image samples from different writer styles, by using class index styles and text content prompts without the need of adversarial training, writer recognition, or text recognition. We gauge system performance with Frechet Inception Distance, writer recognition accuracy, and writer retrieval. We show that the proposed model produces samples that are aesthetically pleasing, help boosting text recognition performance, and gets similar writer retrieval score as real data.