 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRapid and Robust Automated Macroscopic Wood Identification System using Smartphone with Macro-lens
Sep 24, 2017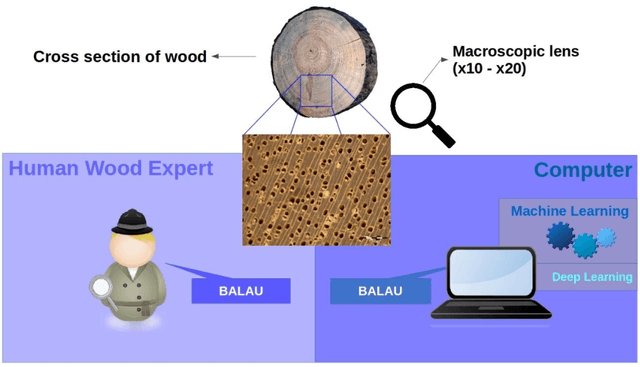

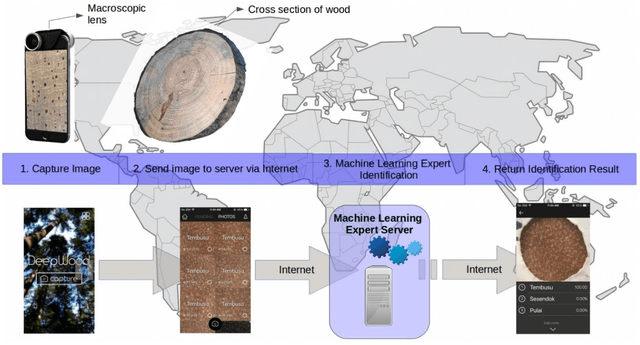
Wood Identification has never been more important to serve the purpose of global forest species protection and timber regulation. Macroscopic level wood identification practiced by wood anatomists can identify wood up to genus level. This is sufficient to serve as a frontline identification to fight against illegal wood logging and timber trade for law enforcement authority. However, frontline enforcement official may lack of the accuracy and confidence of a well trained wood anatomist. Hence, computer assisted method such as machine vision methods are developed to do rapid field identification for law enforcement official. In this paper, we proposed a rapid and robust macroscopic wood identification system using machine vision method with off-the-shelf smartphone and retrofitted macro-lens. Our system is cost effective, easily accessible, fast and scalable at the same time provides human-level accuracy on identification. Camera-enabled smartphone with Internet connectivity coupled with a macro-lens provides a simple and effective digital acquisition of macroscopic wood images which are essential for macroscopic wood identification. The images are immediately streamed to a cloud server via Internet connection for identification which are done within seconds.
Using Convolutional Neural Networks to Count Palm Trees in Satellite Images
Jan 23, 2017



In this paper we propose a supervised learning system for counting and localizing palm trees in high-resolution, panchromatic satellite imagery (40cm/pixel to 1.5m/pixel). A convolutional neural network classifier trained on a set of palm and no-palm images is applied across a satellite image scene in a sliding window fashion. The resultant confidence map is smoothed with a uniform filter. A non-maximal suppression is applied onto the smoothed confidence map to obtain peaks. Trained with a small dataset of 500 images of size 40x40 cropped from satellite images, the system manages to achieve a tree count accuracy of over 99%.
Segmentation-free Vehicle License Plate Recognition using ConvNet-RNN
Jan 23, 2017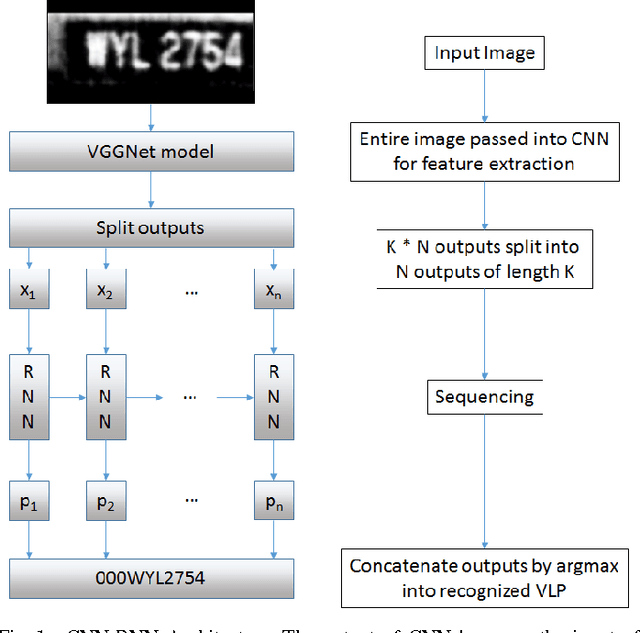

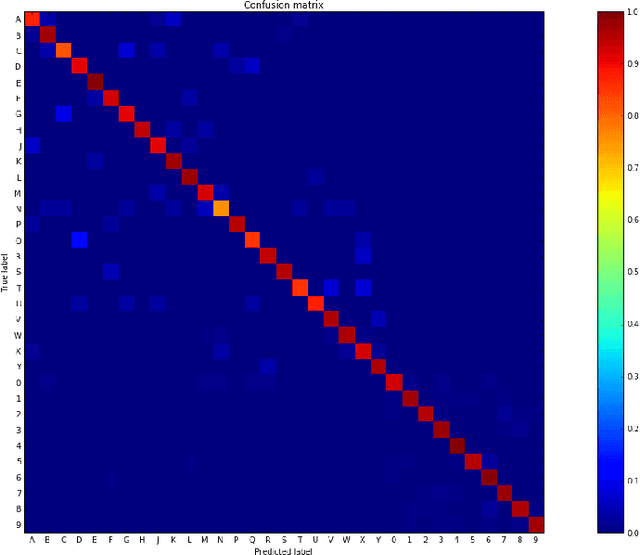
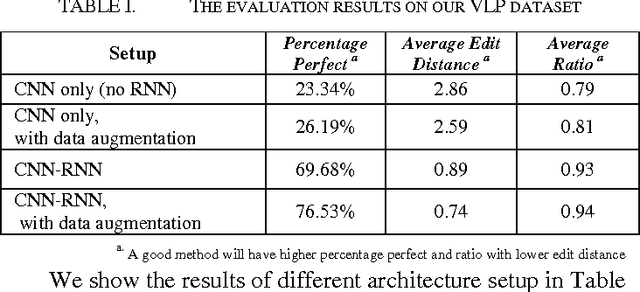
While vehicle license plate recognition (VLPR) is usually done with a sliding window approach, it can have limited performance on datasets with characters that are of variable width. This can be solved by hand-crafting algorithms to prescale the characters. While this approach can work fairly well, the recognizer is only aware of the pixels within each detector window, and fails to account for other contextual information that might be present in other parts of the image. A sliding window approach also requires training data in the form of presegmented characters, which can be more difficult to obtain. In this paper, we propose a unified ConvNet-RNN model to recognize real-world captured license plate photographs. By using a Convolutional Neural Network (ConvNet) to perform feature extraction and using a Recurrent Neural Network (RNN) for sequencing, we address the problem of sliding window approaches being unable to access the context of the entire image by feeding the entire image as input to the ConvNet. This has the added benefit of being able to perform end-to-end training of the entire model on labelled, full license plate images. Experimental results comparing the ConvNet-RNN architecture to a sliding window-based approach shows that the ConvNet-RNN architecture performs significantly better.
Abnormal Event Detection in Videos using Spatiotemporal Autoencoder
Jan 06, 2017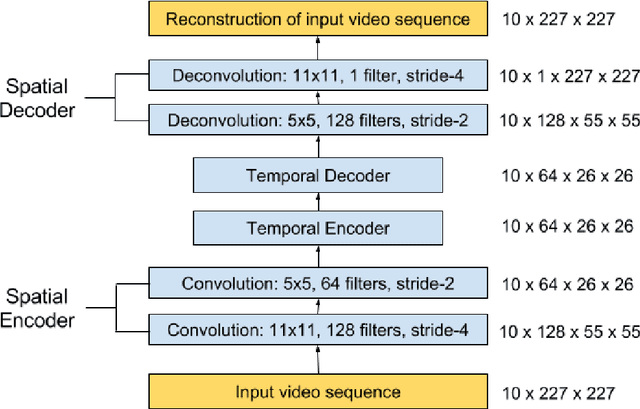
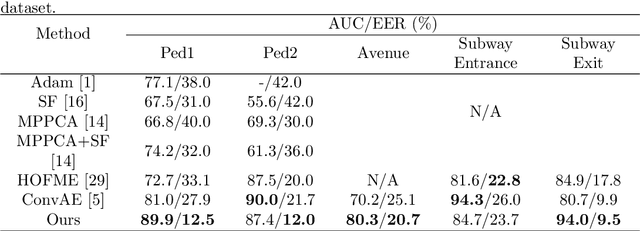
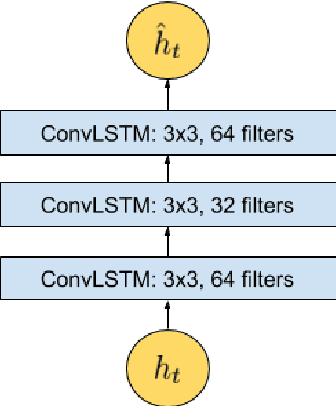
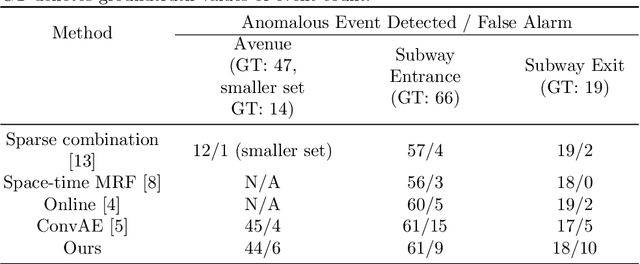
We present an efficient method for detecting anomalies in videos. Recent applications of convolutional neural networks have shown promises of convolutional layers for object detection and recognition, especially in images. However, convolutional neural networks are supervised and require labels as learning signals. We propose a spatiotemporal architecture for anomaly detection in videos including crowded scenes. Our architecture includes two main components, one for spatial feature representation, and one for learning the temporal evolution of the spatial features. Experimental results on Avenue, Subway and UCSD benchmarks confirm that the detection accuracy of our method is comparable to state-of-the-art methods at a considerable speed of up to 140 fps.
Modeling Representation of Videos for Anomaly Detection using Deep Learning: A Review
May 04, 2015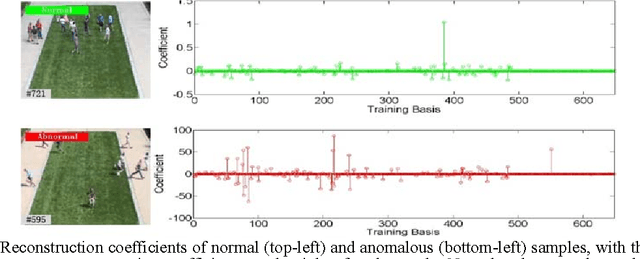
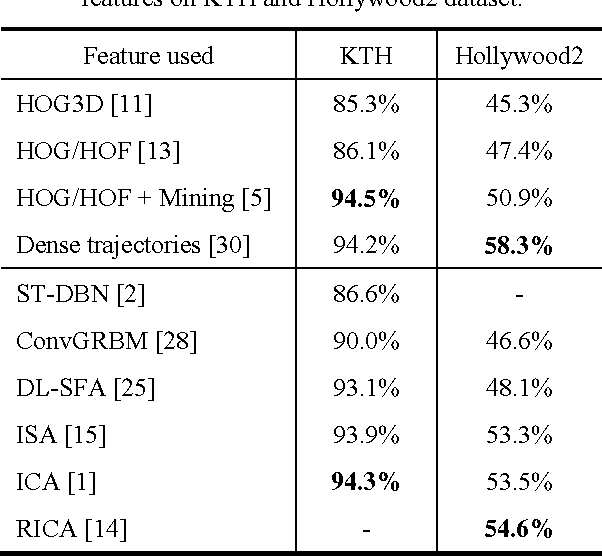
This review article surveys the current progresses made toward video-based anomaly detection. We address the most fundamental aspect for video anomaly detection, that is, video feature representation. Much research works have been done in finding the right representation to perform anomaly detection in video streams accurately with an acceptable false alarm rate. However, this is very challenging due to large variations in environment and human movement, and high space-time complexity due to huge dimensionality of video data. The weakly supervised nature of deep learning algorithms can help in learning representations from the video data itself instead of manually designing the right feature for specific scenes. In this paper, we would like to review the existing methods of modeling video representations using deep learning techniques for the task of anomaly detection and action recognition.
Detection and Recognition of Malaysian Special License Plate Based On SIFT Features
Apr 27, 2015



Automated car license plate recognition systems are developed and applied for purpose of facilitating the surveillance, law enforcement, access control and intelligent transportation monitoring with least human intervention. In this paper, an algorithm based on SIFT feature points clustering and matching is proposed to address the issue of recognizing Malaysian special plates. These special plates do not follow the format of standard car plates as they may contain italic, cursive, connected and small letters. The algorithm is tested with 150 Malaysian special plate images under different environment and the promising experimental results demonstrate that the proposed algorithm is relatively robust.
A HMAX with LLC for visual recognition
Feb 11, 2015



Today's high performance deep artificial neural networks (ANNs) rely heavily on parameter optimization, which is sequential in nature and even with a powerful GPU, would have taken weeks to train them up for solving challenging tasks [22]. HMAX [17] has demonstrated that a simple high performing network could be obtained without heavy optimization. In this paper, we had improved on the existing best HMAX neural network [12] in terms of structural simplicity and performance. Our design replaces the L1 minimization sparse coding (SC) with a locality-constrained linear coding (LLC) [20] which has a lower computational demand. We also put the simple orientation filter bank back into the front layer of the network replacing PCA. Our system's performance has improved over the existing architecture and reached 79.0% on the challenging Caltech-101 [7] dataset, which is state-of-the-art for ANNs (without transfer learning). From our empirical data, the main contributors to our system's performance include an introduction of partial signal whitening, a spot detector, and a spatial pyramid matching (SPM) [14] layer.
On the Adaptability of Neural Network Image Super-Resolution
Dec 21, 2012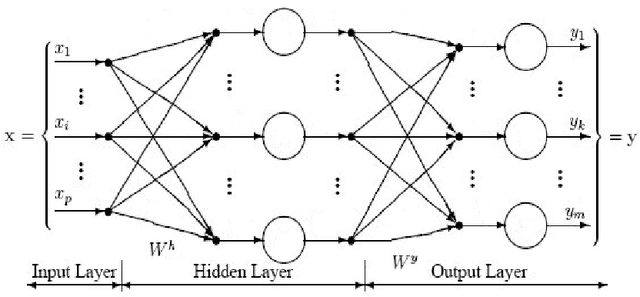

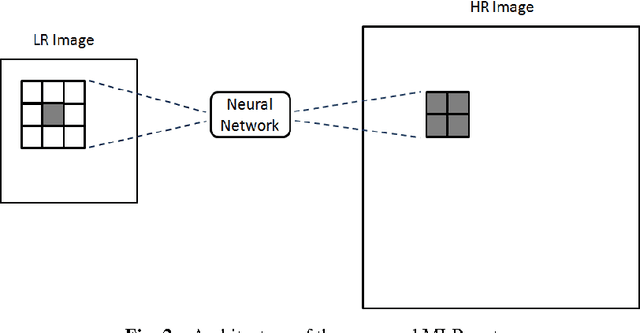

In this paper, we described and developed a framework for Multilayer Perceptron (MLP) to work on low level image processing, where MLP will be used to perform image super-resolution. Meanwhile, MLP are trained with different types of images from various categories, hence analyse the behaviour and performance of the neural network. The tests are carried out using qualitative test, in which Mean Squared Error (MSE), Peak Signal-to-Noise Ratio (PSNR) and Structural Similarity Index (SSIM). The results showed that MLP trained with single image category can perform reasonably well compared to methods proposed by other researchers.
Visual Objects Classification with Sliding Spatial Pyramid Matching
Dec 18, 2012
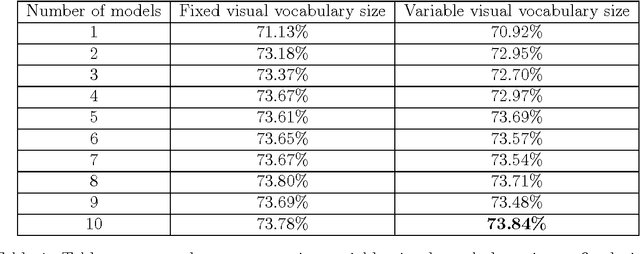

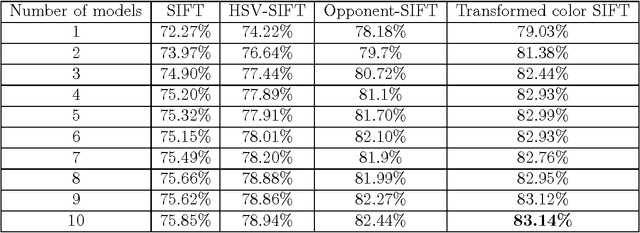
We present a method for visual object classification using only a single feature, transformed color SIFT with a variant of Spatial Pyramid Matching (SPM) that we called Sliding Spatial Pyramid Matching (SSPM), trained with an ensemble of linear regression (provided by LINEAR) to obtained state of the art result on Caltech-101 of 83.46%. SSPM is a special version of SPM where instead of dividing an image into K number of regions, a subwindow of fixed size is slide around the image with a fixed step size. For each subwindow, a histogram of visual words is generated. To obtained the visual vocabulary, instead of performing K-means clustering, we randomly pick N exemplars from the training set and encode them with a soft non-linear mapping method. We then trained 15 models, each with a different visual word size with linear regression. All 15 models are then averaged together to form a single strong model.
Image-based Vehicle Classification System
Apr 10, 2012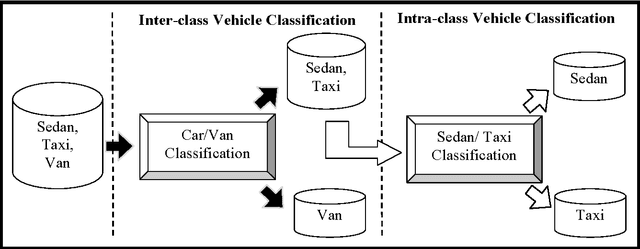
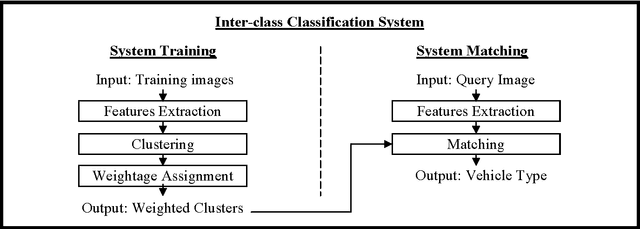
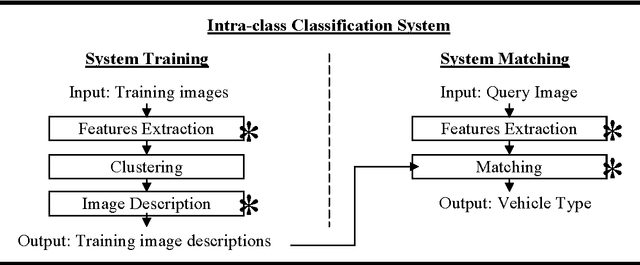
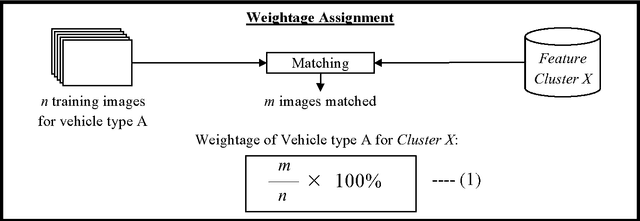
Electronic toll collection (ETC) system has been a common trend used for toll collection on toll road nowadays. The implementation of electronic toll collection allows vehicles to travel at low or full speed during the toll payment, which help to avoid the traffic delay at toll road. One of the major components of an electronic toll collection is the automatic vehicle detection and classification (AVDC) system which is important to classify the vehicle so that the toll is charged according to the vehicle classes. Vision-based vehicle classification system is one type of vehicle classification system which adopt camera as the input sensing device for the system. This type of system has advantage over the rest for it is cost efficient as low cost camera is used. The implementation of vision-based vehicle classification system requires lower initial investment cost and very suitable for the toll collection trend migration in Malaysia from single ETC system to full-scale multi-lane free flow (MLFF). This project includes the development of an image-based vehicle classification system as an effort to seek for a robust vision-based vehicle classification system. The techniques used in the system include scale-invariant feature transform (SIFT) technique, Canny's edge detector, K-means clustering as well as Euclidean distance matching. In this project, a unique way to image description as matching medium is proposed. This distinctiveness of method is analogous to the human DNA concept which is highly unique. The system is evaluated on open datasets and return promising results.