 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSegmentation-free Vehicle License Plate Recognition using ConvNet-RNN
Jan 23, 2017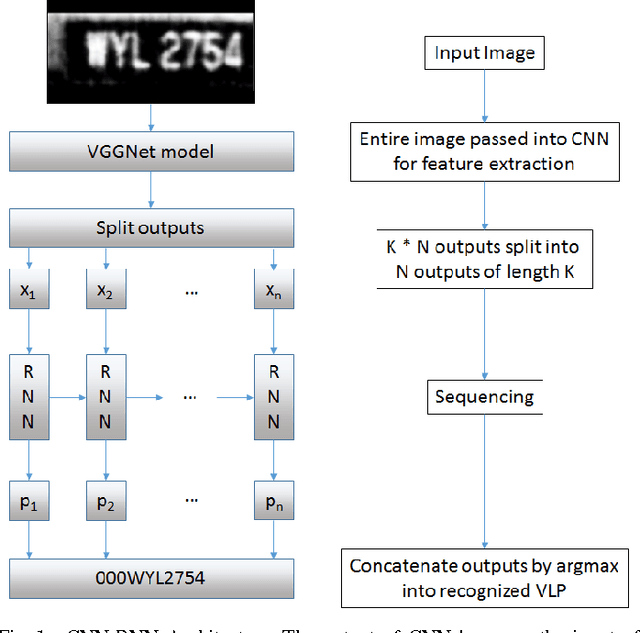

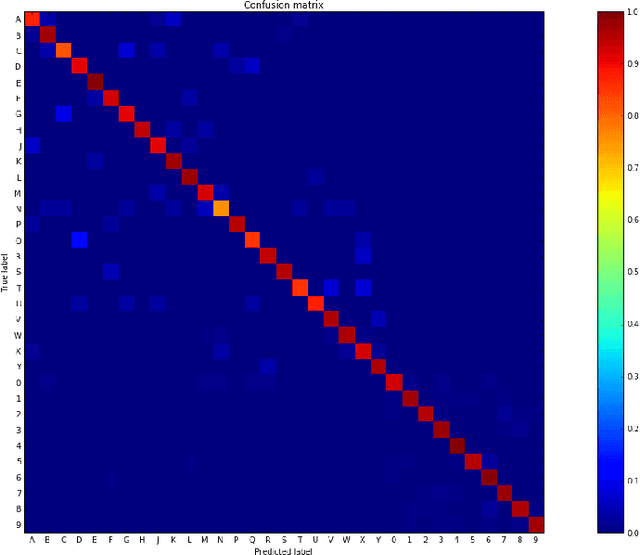
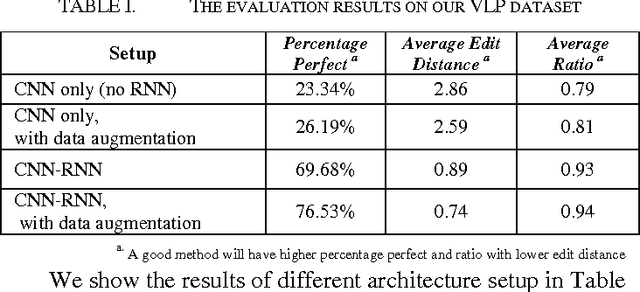
While vehicle license plate recognition (VLPR) is usually done with a sliding window approach, it can have limited performance on datasets with characters that are of variable width. This can be solved by hand-crafting algorithms to prescale the characters. While this approach can work fairly well, the recognizer is only aware of the pixels within each detector window, and fails to account for other contextual information that might be present in other parts of the image. A sliding window approach also requires training data in the form of presegmented characters, which can be more difficult to obtain. In this paper, we propose a unified ConvNet-RNN model to recognize real-world captured license plate photographs. By using a Convolutional Neural Network (ConvNet) to perform feature extraction and using a Recurrent Neural Network (RNN) for sequencing, we address the problem of sliding window approaches being unable to access the context of the entire image by feeding the entire image as input to the ConvNet. This has the added benefit of being able to perform end-to-end training of the entire model on labelled, full license plate images. Experimental results comparing the ConvNet-RNN architecture to a sliding window-based approach shows that the ConvNet-RNN architecture performs significantly better.
Abnormal Event Detection in Videos using Spatiotemporal Autoencoder
Jan 06, 2017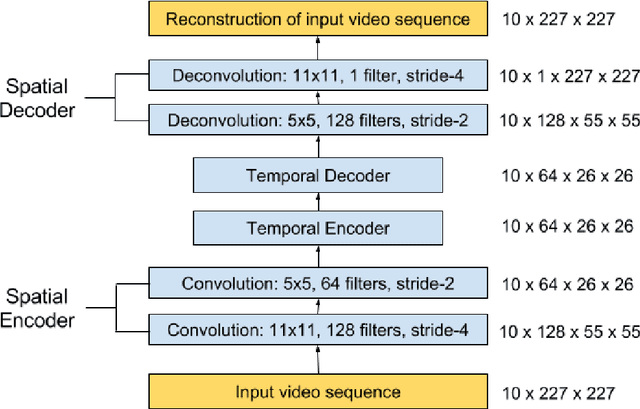
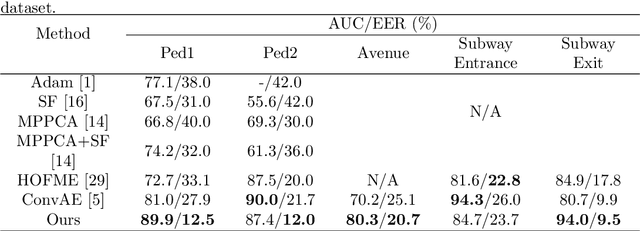
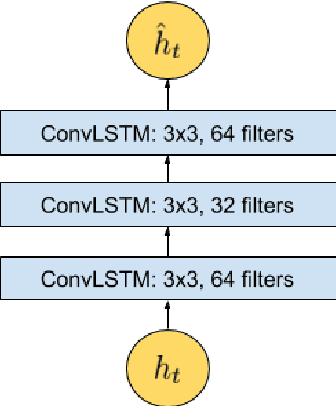
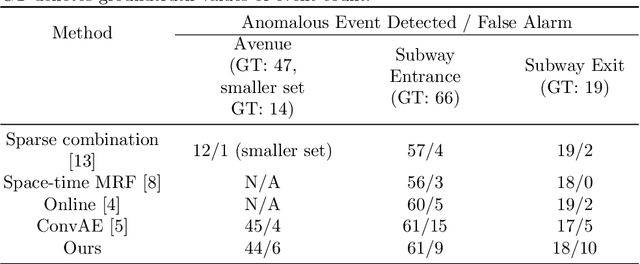
We present an efficient method for detecting anomalies in videos. Recent applications of convolutional neural networks have shown promises of convolutional layers for object detection and recognition, especially in images. However, convolutional neural networks are supervised and require labels as learning signals. We propose a spatiotemporal architecture for anomaly detection in videos including crowded scenes. Our architecture includes two main components, one for spatial feature representation, and one for learning the temporal evolution of the spatial features. Experimental results on Avenue, Subway and UCSD benchmarks confirm that the detection accuracy of our method is comparable to state-of-the-art methods at a considerable speed of up to 140 fps.
Modeling Representation of Videos for Anomaly Detection using Deep Learning: A Review
May 04, 2015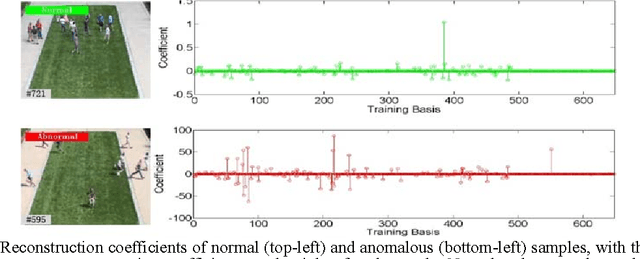
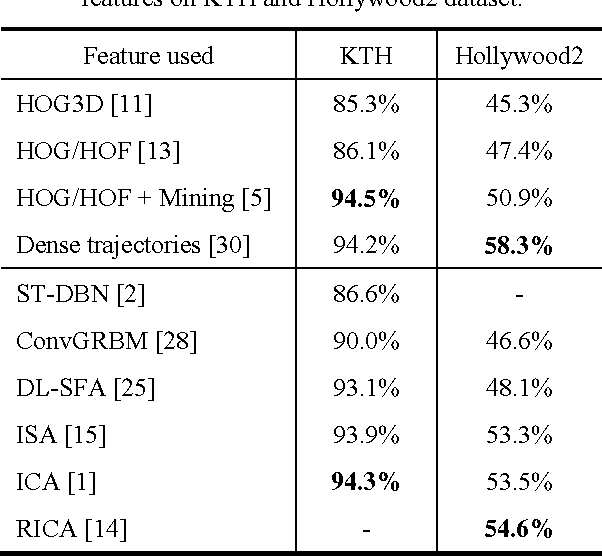
This review article surveys the current progresses made toward video-based anomaly detection. We address the most fundamental aspect for video anomaly detection, that is, video feature representation. Much research works have been done in finding the right representation to perform anomaly detection in video streams accurately with an acceptable false alarm rate. However, this is very challenging due to large variations in environment and human movement, and high space-time complexity due to huge dimensionality of video data. The weakly supervised nature of deep learning algorithms can help in learning representations from the video data itself instead of manually designing the right feature for specific scenes. In this paper, we would like to review the existing methods of modeling video representations using deep learning techniques for the task of anomaly detection and action recognition.