 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSegmentation-free Vehicle License Plate Recognition using ConvNet-RNN
Paper and Code
Jan 23, 2017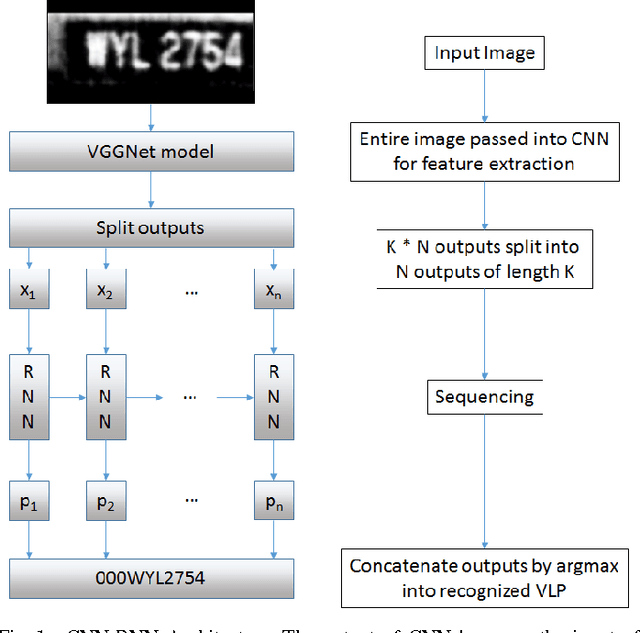

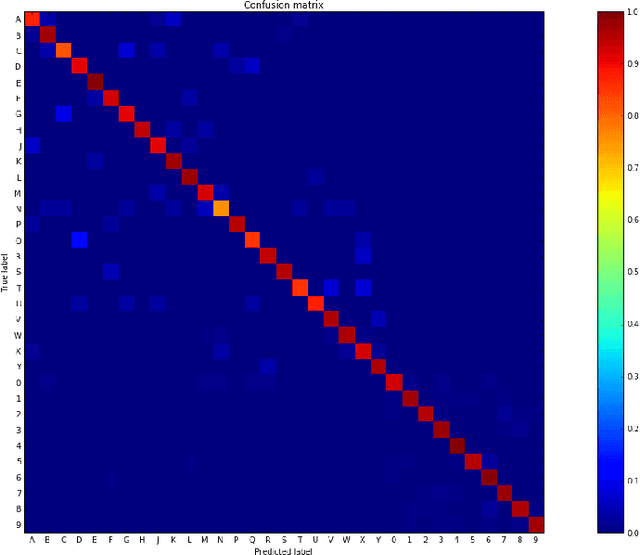
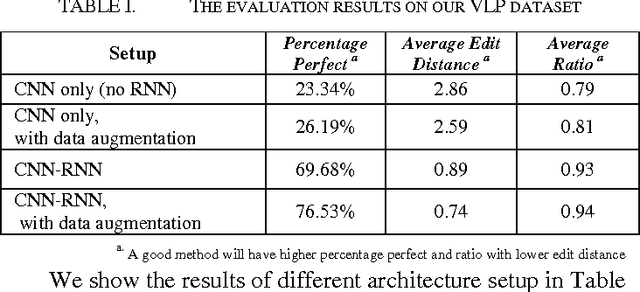
While vehicle license plate recognition (VLPR) is usually done with a sliding window approach, it can have limited performance on datasets with characters that are of variable width. This can be solved by hand-crafting algorithms to prescale the characters. While this approach can work fairly well, the recognizer is only aware of the pixels within each detector window, and fails to account for other contextual information that might be present in other parts of the image. A sliding window approach also requires training data in the form of presegmented characters, which can be more difficult to obtain. In this paper, we propose a unified ConvNet-RNN model to recognize real-world captured license plate photographs. By using a Convolutional Neural Network (ConvNet) to perform feature extraction and using a Recurrent Neural Network (RNN) for sequencing, we address the problem of sliding window approaches being unable to access the context of the entire image by feeding the entire image as input to the ConvNet. This has the added benefit of being able to perform end-to-end training of the entire model on labelled, full license plate images. Experimental results comparing the ConvNet-RNN architecture to a sliding window-based approach shows that the ConvNet-RNN architecture performs significantly better.