 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey of Historical Document Image Datasets
Paper and Code

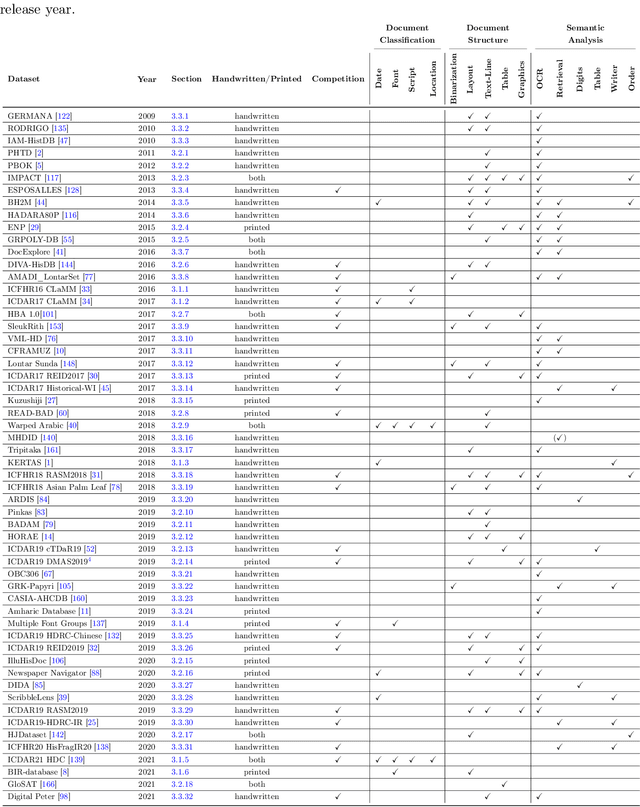
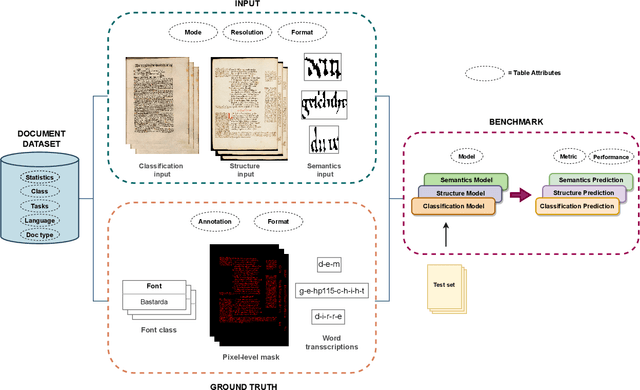
This paper presents a systematic literature review of image datasets for document image analysis, focusing on historical documents, such as handwritten manuscripts and early prints. Finding appropriate datasets for historical document analysis is a crucial prerequisite to facilitate research using different machine learning algorithms. However, because of the very large variety of the actual data (e.g., scripts, tasks, dates, support systems, and amount of deterioration), the different formats for data and label representation, and the different evaluation processes and benchmarks, finding appropriate datasets is a difficult task. This work fills this gap, presenting a meta-study on existing datasets. After a systematic selection process (according to PRISMA guidelines), we select 56 studies that are chosen based on different factors, such as the year of publication, number of methods implemented in the article, reliability of the chosen algorithms, dataset size, and journal outlet. We summarize each study by assigning it to one of three pre-defined tasks: document classification, layout structure, or semantic analysis. We present the statistics, document type, language, tasks, input visual aspects, and ground truth information for every dataset. In addition, we provide the benchmark tasks and results from these papers or recent competitions. We further discuss gaps and challenges in this domain. We advocate for providing conversion tools to common formats (e.g., COCO format for computer vision tasks) and always providing a set of evaluation metrics, instead of just one, to make results comparable across studies.