Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeML_LTU at SemEval-2022 Task 4: T5 Towards Identifying Patronizing and Condescending Language
Paper and Code



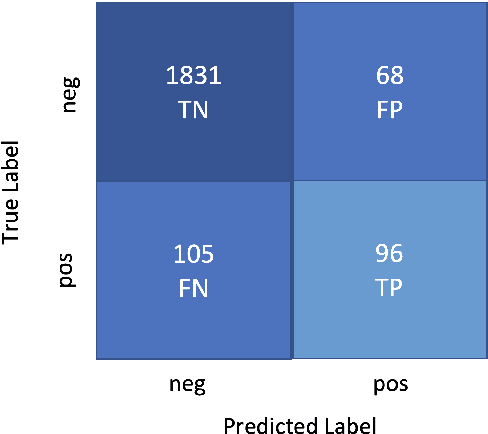
This paper describes the system used by the Machine Learning Group of LTU in subtask 1 of the SemEval-2022 Task 4: Patronizing and Condescending Language (PCL) Detection. Our system consists of finetuning a pretrained Text-to-Text-Transfer Transformer (T5) and innovatively reducing its out-of-class predictions. The main contributions of this paper are 1) the description of the implementation details of the T5 model we used, 2) analysis of the successes & struggles of the model in this task, and 3) ablation studies beyond the official submission to ascertain the relative importance of data split. Our model achieves an F1 score of 0.5452 on the official test set.
* Accepted at the International Workshop on Semantic Evaluation (2022)
co-located with NAACL
View paper on