 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePotential Idiomatic Expression (PIE)-English: Corpus for Classes of Idioms
Apr 25, 2021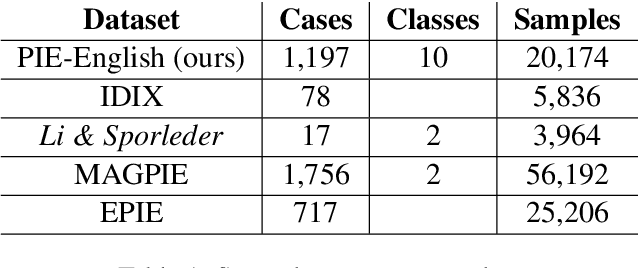
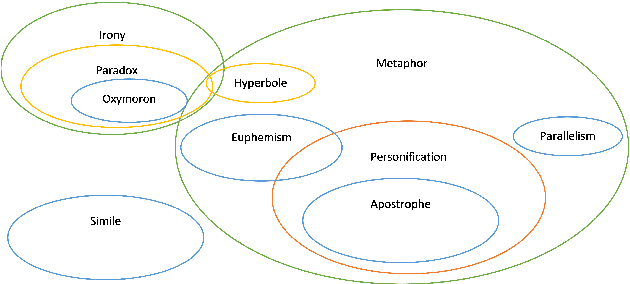
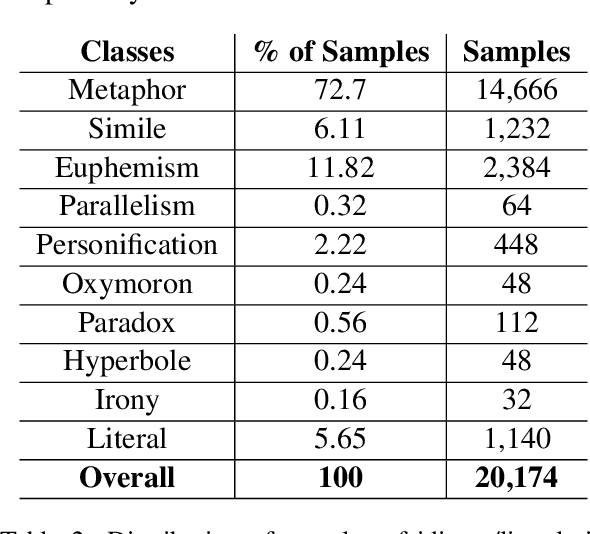
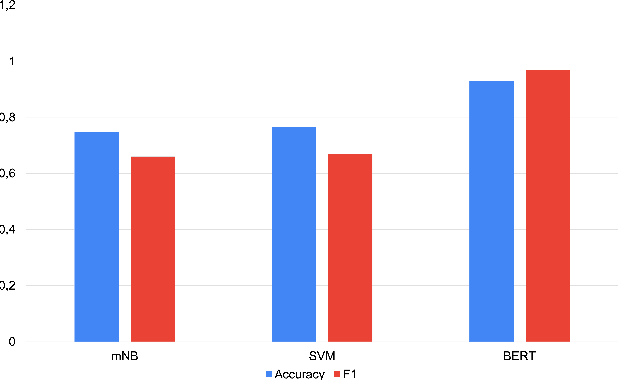
We present a fairly large, Potential Idiomatic Expression (PIE) dataset for Natural Language Processing (NLP) in English. The challenges with NLP systems with regards to tasks such as Machine Translation (MT), word sense disambiguation (WSD) and information retrieval make it imperative to have a labelled idioms dataset with classes such as it is in this work. To the best of the authors' knowledge, this is the first idioms corpus with classes of idioms beyond the literal and the general idioms classification. In particular, the following classes are labelled in the dataset: metaphor, simile, euphemism, parallelism, personification, oxymoron, paradox, hyperbole, irony and literal. Many past efforts have been limited in the corpus size and classes of samples but this dataset contains over 20,100 samples with almost 1,200 cases of idioms (with their meanings) from 10 classes (or senses). The corpus may also be extended by researchers to meet specific needs. The corpus has part of speech (PoS) tagging from the NLTK library. Classification experiments performed on the corpus to obtain a baseline and comparison among three common models, including the BERT model, give good results. We also make publicly available the corpus and the relevant codes for working with it for NLP tasks.
The Challenge of Diacritics in Yoruba Embeddings
Nov 15, 2020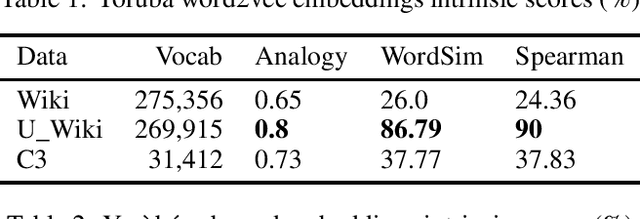
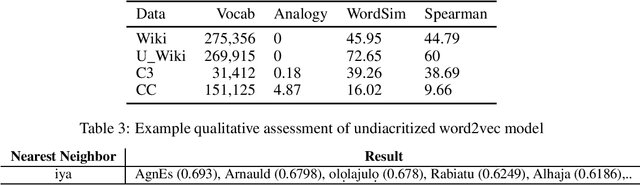
The major contributions of this work include the empirical establishment of a better performance for Yoruba embeddings from undiacritized (normalized) dataset and provision of new analogy sets for evaluation. The Yoruba language, being a tonal language, utilizes diacritics (tonal marks) in written form. We show that this affects embedding performance by creating embeddings from exactly the same Wikipedia dataset but with the second one normalized to be undiacritized. We further compare average intrinsic performance with two other work (using analogy test set & WordSim) and we obtain the best performance in WordSim and corresponding Spearman correlation.
Corpora Compared: The Case of the Swedish Gigaword & Wikipedia Corpora
Nov 06, 2020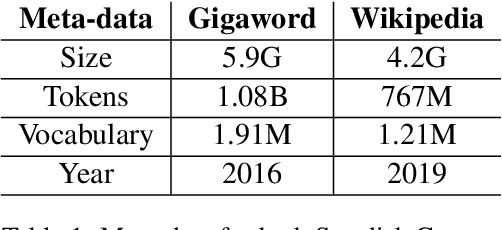
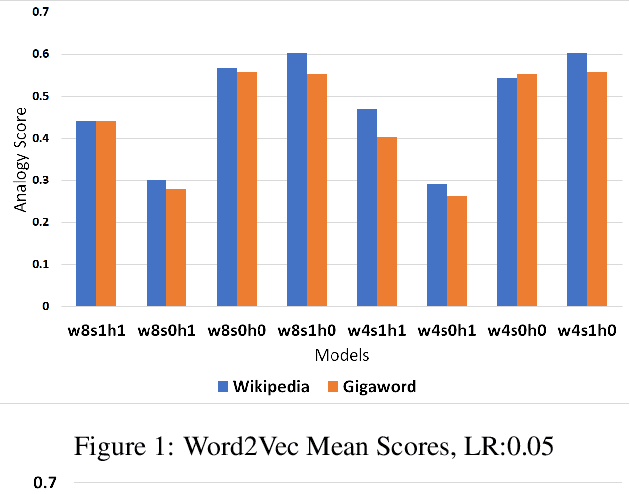
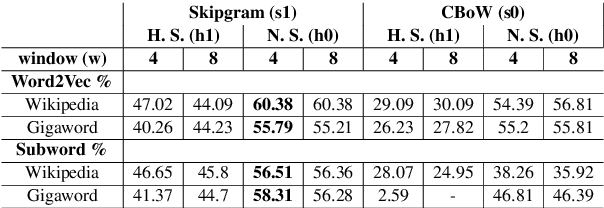
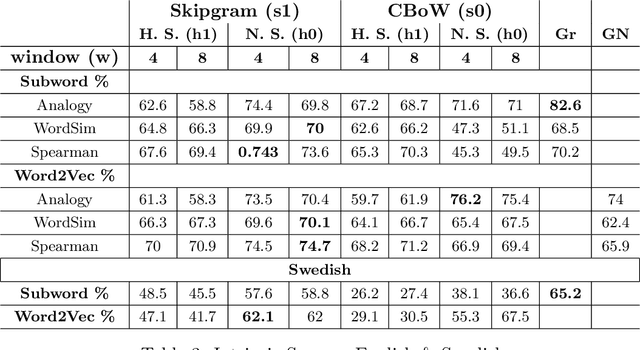
In this work, we show that the difference in performance of embeddings from differently sourced data for a given language can be due to other factors besides data size. Natural language processing (NLP) tasks usually perform better with embeddings from bigger corpora. However, broadness of covered domain and noise can play important roles. We evaluate embeddings based on two Swedish corpora: The Gigaword and Wikipedia, in analogy (intrinsic) tests and discover that the embeddings from the Wikipedia corpus generally outperform those from the Gigaword corpus, which is a bigger corpus. Downstream tests will be required to have a definite evaluation.
Exploring Swedish & English fastText Embeddings with the Transformer
Jul 23, 2020
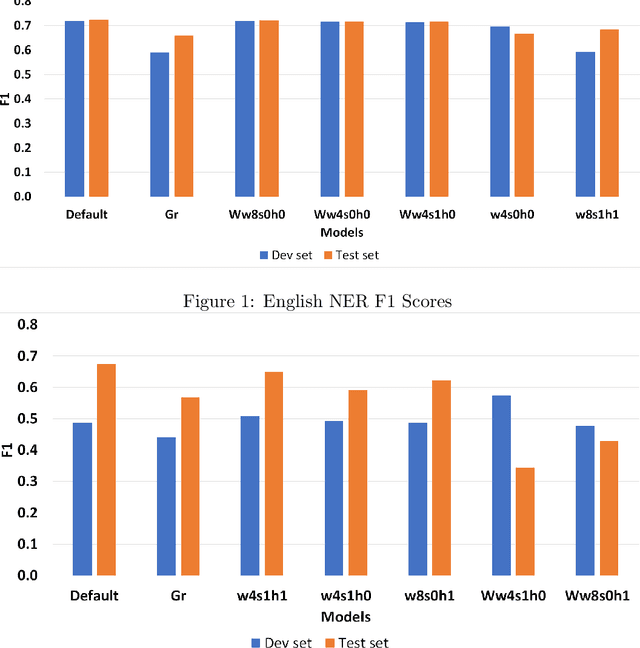

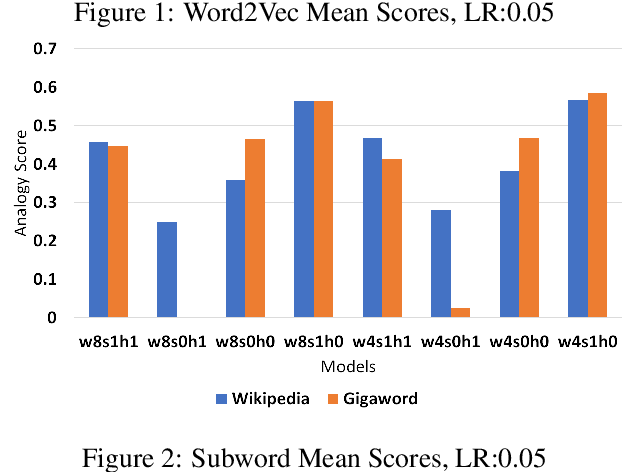
In this paper, our main contributions are that embeddings from relatively smaller corpora can outperform ones from far larger corpora and we present the new Swedish analogy test set. To achieve a good network performance in natural language processing (NLP) downstream tasks, several factors play important roles: dataset size, the right hyper-parameters, and well-trained embedding. We show that, with the right set of hyper-parameters, good network performance can be reached even on smaller datasets. We evaluate the embeddings at the intrinsic level and extrinsic level, by deploying them on the Transformer in named entity recognition (NER) task and conduct significance tests.This is done for both Swedish and English. We obtain better performance in both languages on the downstream task with far smaller training data, compared to recently released, common crawl versions and character n-grams appear useful for Swedish, a morphologically rich language.
Word2Vec: Optimal Hyper-Parameters and Their Impact on NLP Downstream Tasks
Mar 23, 2020

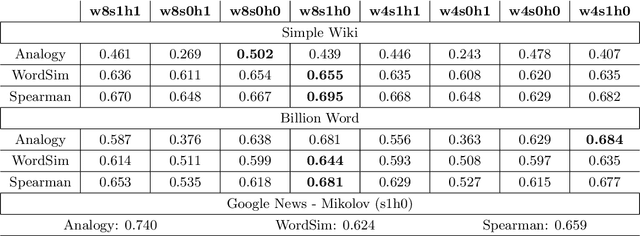
Word2Vec is a prominent tool for Natural Language Processing (NLP) tasks. Similar inspiration is found in distributed embeddings for state-of-the-art (sota) deep neural networks. However, wrong combination of hyper-parameters can produce poor quality vectors. The objective of this work is to show optimal combination of hyper-parameters exists and evaluate various combinations. We compare them with the original model released by Mikolov. Both intrinsic and extrinsic (downstream) evaluations, including Named Entity Recognition (NER) and Sentiment Analysis (SA) were carried out. The downstream tasks reveal that the best model is task-specific, high analogy scores don't necessarily correlate positively with F1 scores and the same applies for more data. Increasing vector dimension size after a point leads to poor quality or performance. If ethical considerations to save time, energy and the environment are made, then reasonably smaller corpora may do just as well or even better in some cases. Besides, using a small corpus, we obtain better human-assigned WordSim scores, corresponding Spearman correlation and better downstream (NER & SA) performance compared to Mikolov's model, trained on 100 billion word corpus.