 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Swedish & English fastText Embeddings with the Transformer
Paper and Code

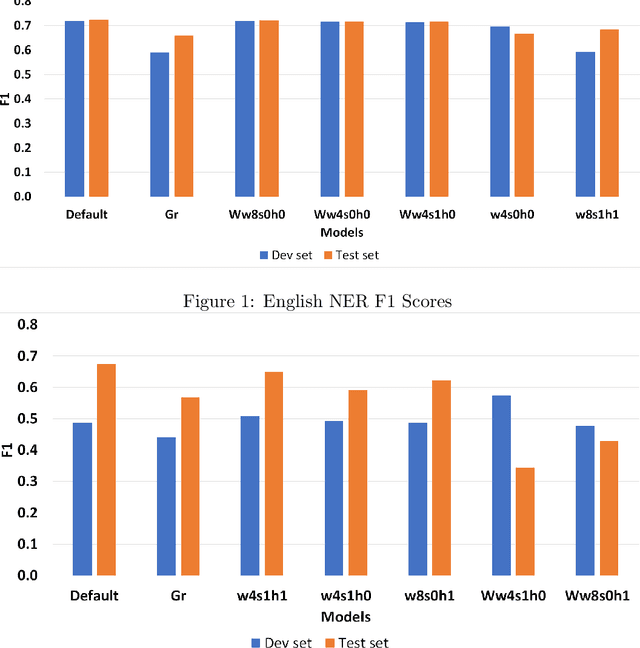

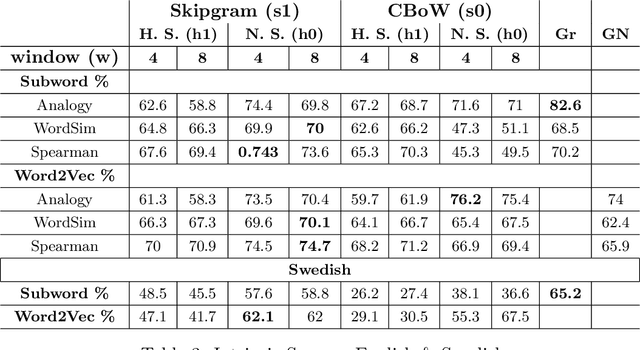
In this paper, our main contributions are that embeddings from relatively smaller corpora can outperform ones from far larger corpora and we present the new Swedish analogy test set. To achieve a good network performance in natural language processing (NLP) downstream tasks, several factors play important roles: dataset size, the right hyper-parameters, and well-trained embedding. We show that, with the right set of hyper-parameters, good network performance can be reached even on smaller datasets. We evaluate the embeddings at the intrinsic level and extrinsic level, by deploying them on the Transformer in named entity recognition (NER) task and conduct significance tests.This is done for both Swedish and English. We obtain better performance in both languages on the downstream task with far smaller training data, compared to recently released, common crawl versions and character n-grams appear useful for Swedish, a morphologically rich language.