Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Challenge of Diacritics in Yoruba Embeddings
Paper and Code
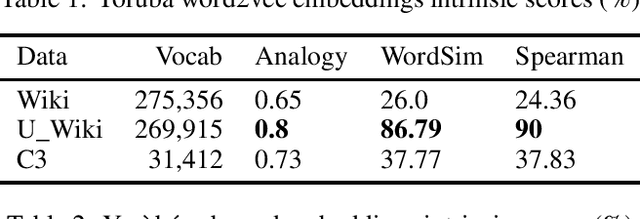
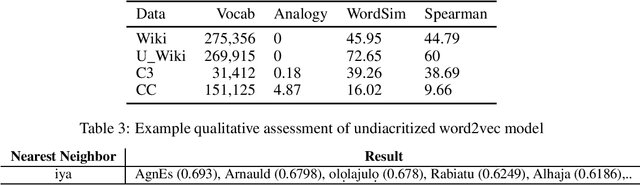
The major contributions of this work include the empirical establishment of a better performance for Yoruba embeddings from undiacritized (normalized) dataset and provision of new analogy sets for evaluation. The Yoruba language, being a tonal language, utilizes diacritics (tonal marks) in written form. We show that this affects embedding performance by creating embeddings from exactly the same Wikipedia dataset but with the second one normalized to be undiacritized. We further compare average intrinsic performance with two other work (using analogy test set & WordSim) and we obtain the best performance in WordSim and corresponding Spearman correlation.
* Presented at NeurIPS 2020 Workshop on Machine Learning for the
Developing World
View paper on