Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCorpora Compared: The Case of the Swedish Gigaword & Wikipedia Corpora
Paper and Code
Nov 06, 2020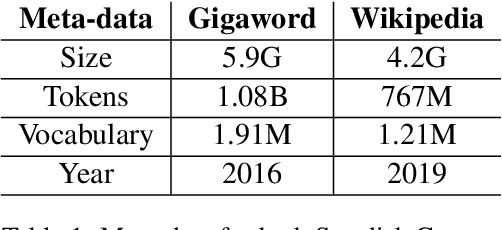
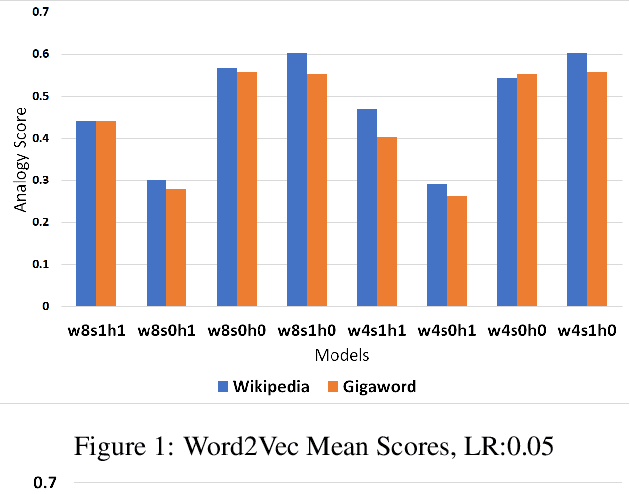
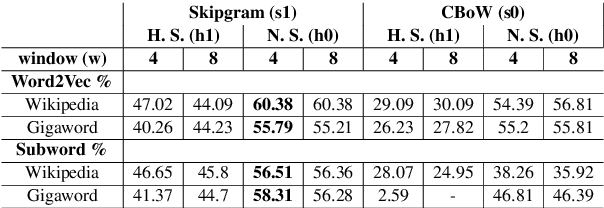
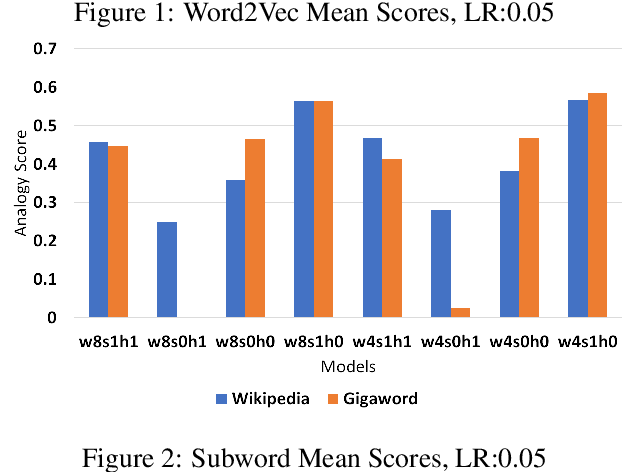
In this work, we show that the difference in performance of embeddings from differently sourced data for a given language can be due to other factors besides data size. Natural language processing (NLP) tasks usually perform better with embeddings from bigger corpora. However, broadness of covered domain and noise can play important roles. We evaluate embeddings based on two Swedish corpora: The Gigaword and Wikipedia, in analogy (intrinsic) tests and discover that the embeddings from the Wikipedia corpus generally outperform those from the Gigaword corpus, which is a bigger corpus. Downstream tests will be required to have a definite evaluation.
* Presented at the Eighth Swedish Language Technology Conference (SLTC)
View paper on