 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Replica Dataset: A Digital Replica of Indoor Spaces
Jun 13, 2019



We introduce Replica, a dataset of 18 highly photo-realistic 3D indoor scene reconstructions at room and building scale. Each scene consists of a dense mesh, high-resolution high-dynamic-range (HDR) textures, per-primitive semantic class and instance information, and planar mirror and glass reflectors. The goal of Replica is to enable machine learning (ML) research that relies on visually, geometrically, and semantically realistic generative models of the world - for instance, egocentric computer vision, semantic segmentation in 2D and 3D, geometric inference, and the development of embodied agents (virtual robots) performing navigation, instruction following, and question answering. Due to the high level of realism of the renderings from Replica, there is hope that ML systems trained on Replica may transfer directly to real world image and video data. Together with the data, we are releasing a minimal C++ SDK as a starting point for working with the Replica dataset. In addition, Replica is `Habitat-compatible', i.e. can be natively used with AI Habitat for training and testing embodied agents.
Continuous-Time Visual-Inertial Odometry for Event Cameras
Jun 10, 2018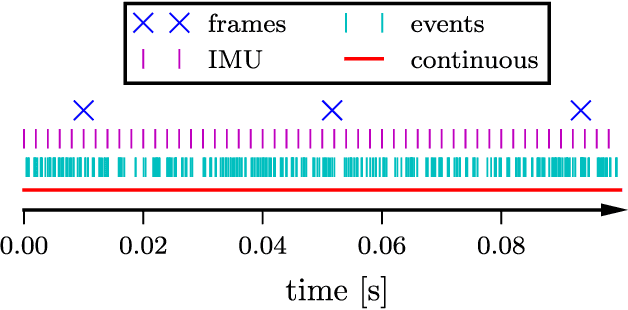
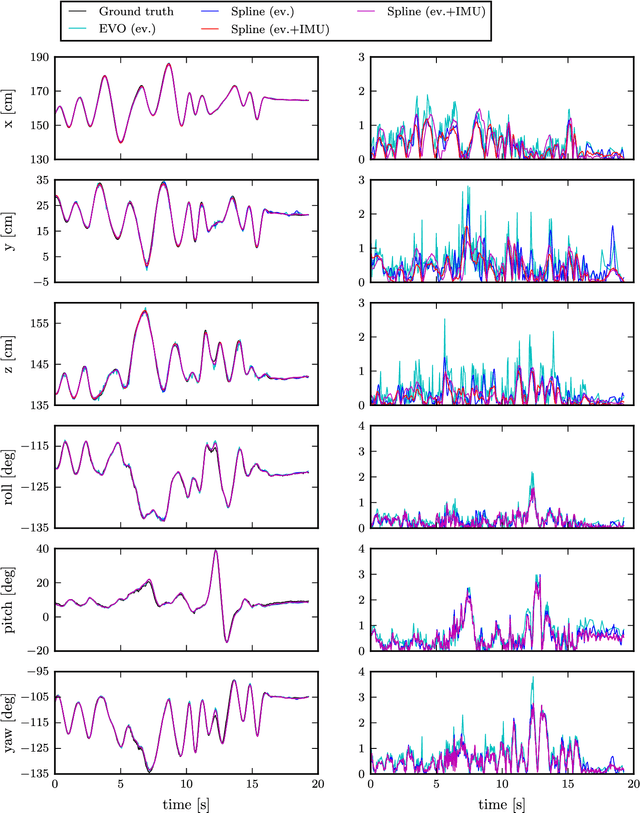
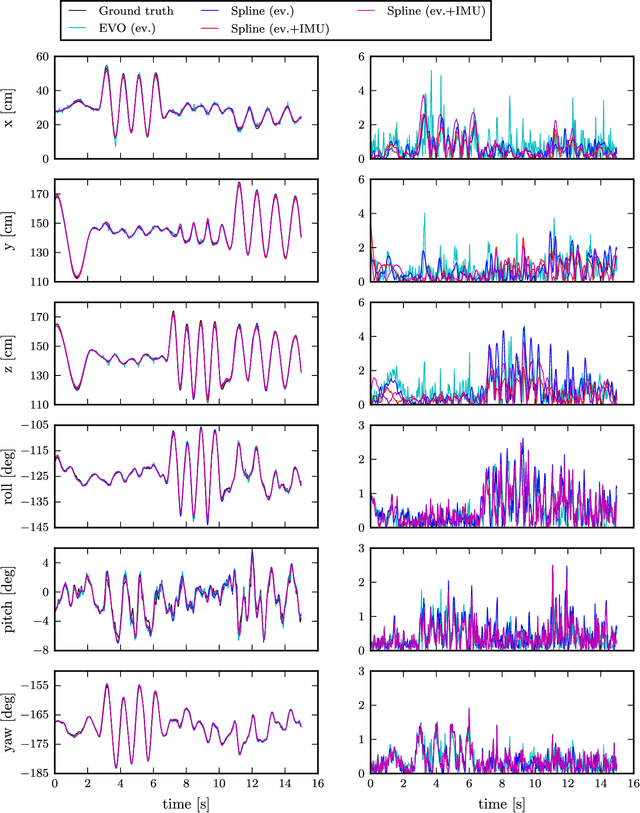
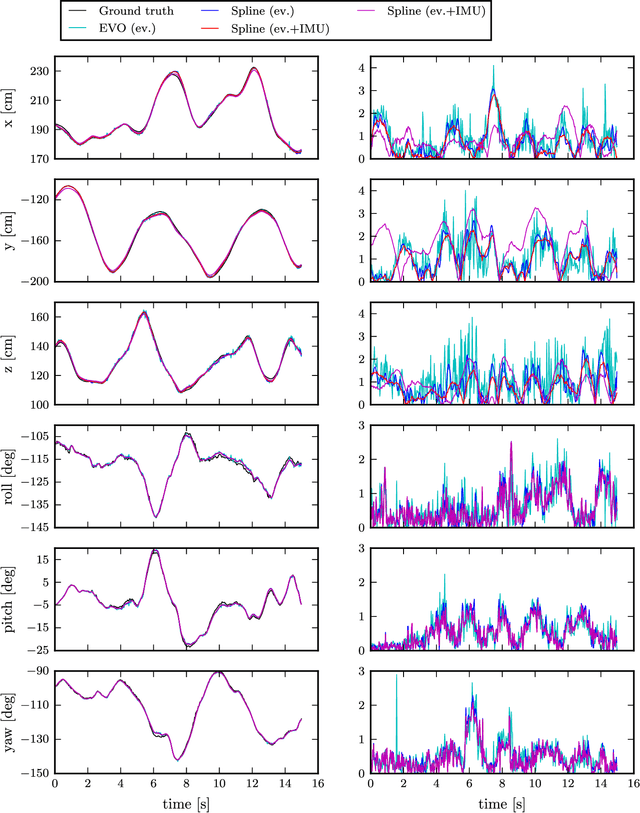
Event cameras are bio-inspired vision sensors that output pixel-level brightness changes instead of standard intensity frames. They offer significant advantages over standard cameras, namely a very high dynamic range, no motion blur, and a latency in the order of microseconds. However, due to the fundamentally different structure of the sensor's output, new algorithms that exploit the high temporal resolution and the asynchronous nature of the sensor are required. Recent work has shown that a continuous-time representation of the event camera pose can deal with the high temporal resolution and asynchronous nature of this sensor in a principled way. In this paper, we leverage such a continuous-time representation to perform visual-inertial odometry with an event camera. This representation allows direct integration of the asynchronous events with micro-second accuracy and the inertial measurements at high frequency. The event camera trajectory is approximated by a smooth curve in the space of rigid-body motions using cubic splines. This formulation significantly reduces the number of variables in trajectory estimation problems. We evaluate our method on real data from several scenes and compare the results against ground truth from a motion-capture system. We show that our method provides improved accuracy over the result of a state-of-the-art visual odometry method for event cameras. We also show that both the map orientation and scale can be recovered accurately by fusing events and inertial data. To the best of our knowledge, this is the first work on visual-inertial fusion with event cameras using a continuous-time framework.
Aggressive Quadrotor Flight through Narrow Gaps with Onboard Sensing and Computing using Active Vision
Apr 05, 2018
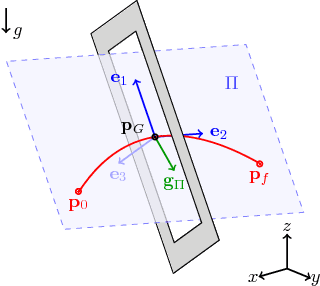


We address one of the main challenges towards autonomous quadrotor flight in complex environments, which is flight through narrow gaps. While previous works relied on off-board localization systems or on accurate prior knowledge of the gap position and orientation, we rely solely on onboard sensing and computing and estimate the full state by fusing gap detection from a single onboard camera with an IMU. This problem is challenging for two reasons: (i) the quadrotor pose uncertainty with respect to the gap increases quadratically with the distance from the gap; (ii) the quadrotor has to actively control its orientation towards the gap to enable state estimation (i.e., active vision). We solve this problem by generating a trajectory that considers geometric, dynamic, and perception constraints: during the approach maneuver, the quadrotor always faces the gap to allow state estimation, while respecting the vehicle dynamics; during the traverse through the gap, the distance of the quadrotor to the edges of the gap is maximized. Furthermore, we replan the trajectory during its execution to cope with the varying uncertainty of the state estimate. We successfully evaluate and demonstrate the proposed approach in many real experiments. To the best of our knowledge, this is the first work that addresses and achieves autonomous, aggressive flight through narrow gaps using only onboard sensing and computing and without prior knowledge of the pose of the gap.
Translation of "Zur Ermittlung eines Objektes aus zwei Perspektiven mit innerer Orientierung" by Erwin Kruppa (1913)
Dec 25, 2017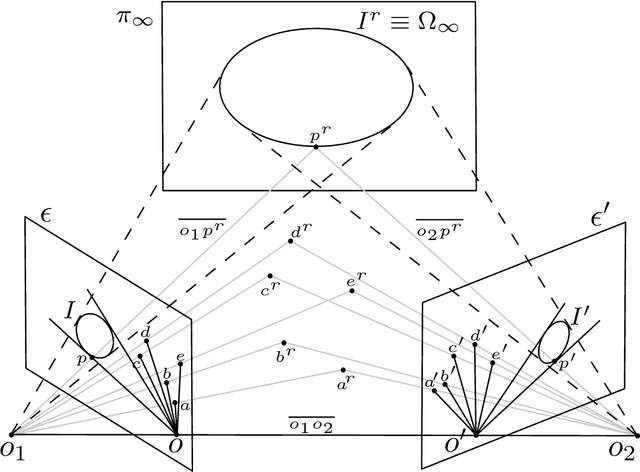
Erwin Kruppa's 1913 paper, Erwin Kruppa, "Zur Ermittlung eines Objektes aus zwei Perspektiven mit innerer Orientierung", Sitzungsberichte der Mathematisch-Naturwissenschaftlichen Kaiserlichen Akademie der Wissenschaften, Vol. 122 (1913), pp. 1939-1948, which may be translated as "To determine a 3D object from two perspective views with known inner orientation", is a landmark paper in Computer Vision because it provides the first five-point algorithm for relative pose estimation. Kruppa showed that (a finite number of solutions for) the relative pose between two calibrated images of a rigid object can be computed from five point matches between the images. Kruppa's work also gained attention in the topic of camera self-calibration, as presented in (Maybank and Faugeras, 1992). Since the paper is still relevant today (more than a hundred citations within the last ten years) and the paper is not available online, we ordered a copy from the German National Library in Frankfurt and provide an English translation along with the German original. We also adapt the terminology to a modern jargon and provide some clarifications (highlighted in sans-serif font). For a historical review of geometric computer vision, the reader is referred to the recent survey paper (Sturm, 2011).
The Event-Camera Dataset and Simulator: Event-based Data for Pose Estimation, Visual Odometry, and SLAM
Nov 08, 2017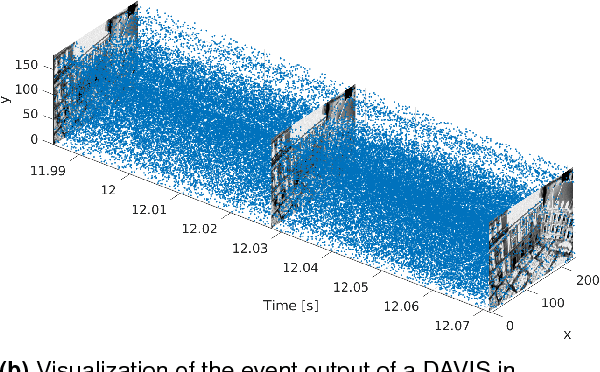

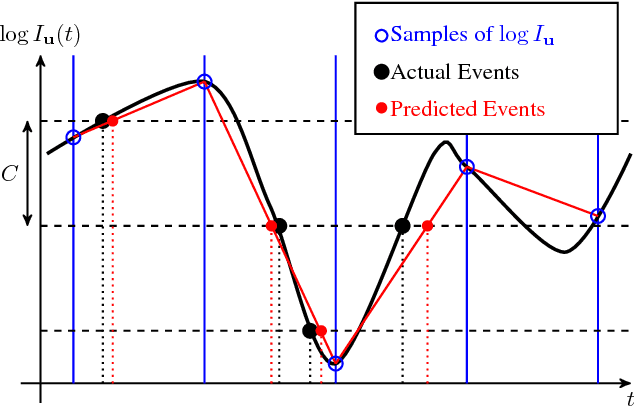
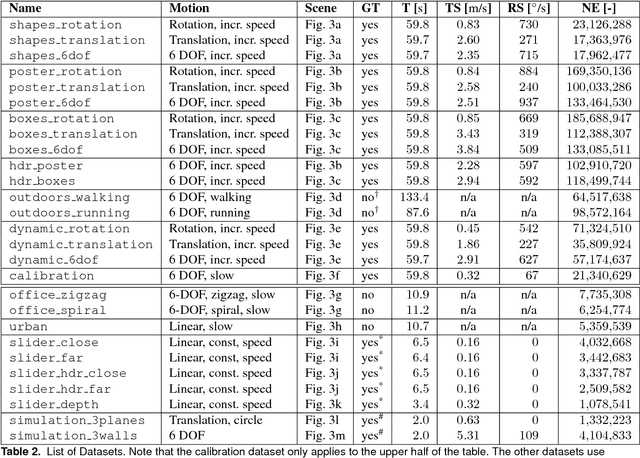
New vision sensors, such as the Dynamic and Active-pixel Vision sensor (DAVIS), incorporate a conventional global-shutter camera and an event-based sensor in the same pixel array. These sensors have great potential for high-speed robotics and computer vision because they allow us to combine the benefits of conventional cameras with those of event-based sensors: low latency, high temporal resolution, and very high dynamic range. However, new algorithms are required to exploit the sensor characteristics and cope with its unconventional output, which consists of a stream of asynchronous brightness changes (called "events") and synchronous grayscale frames. For this purpose, we present and release a collection of datasets captured with a DAVIS in a variety of synthetic and real environments, which we hope will motivate research on new algorithms for high-speed and high-dynamic-range robotics and computer-vision applications. In addition to global-shutter intensity images and asynchronous events, we provide inertial measurements and ground-truth camera poses from a motion-capture system. The latter allows comparing the pose accuracy of ego-motion estimation algorithms quantitatively. All the data are released both as standard text files and binary files (i.e., rosbag). This paper provides an overview of the available data and describes a simulator that we release open-source to create synthetic event-camera data.
* 7 pages, 4 figures, 3 tables
Event-based, 6-DOF Camera Tracking from Photometric Depth Maps
Oct 31, 2017

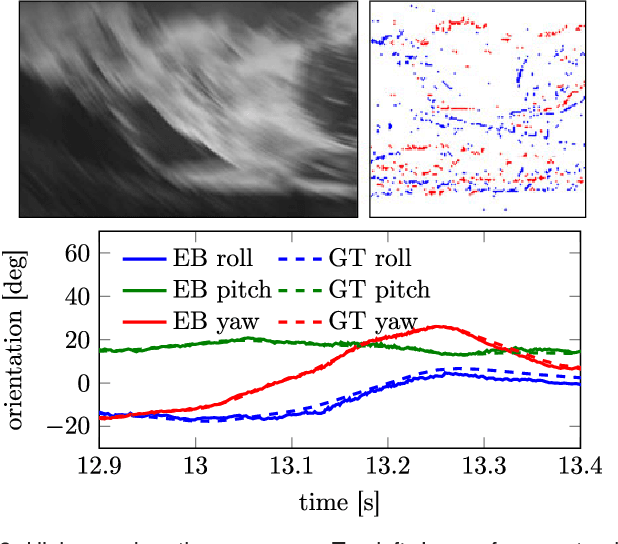

Event cameras are bio-inspired vision sensors that output pixel-level brightness changes instead of standard intensity frames. These cameras do not suffer from motion blur and have a very high dynamic range, which enables them to provide reliable visual information during high-speed motions or in scenes characterized by high dynamic range. These features, along with a very low power consumption, make event cameras an ideal complement to standard cameras for VR/AR and video game applications. With these applications in mind, this paper tackles the problem of accurate, low-latency tracking of an event camera from an existing photometric depth map (i.e., intensity plus depth information) built via classic dense reconstruction pipelines. Our approach tracks the 6-DOF pose of the event camera upon the arrival of each event, thus virtually eliminating latency. We successfully evaluate the method in both indoor and outdoor scenes and show that---because of the technological advantages of the event camera---our pipeline works in scenes characterized by high-speed motion, which are still unaccessible to standard cameras.
* 12 pages, 13 figures. 2 tables. (in press)
Independent Motion Detection with Event-driven Cameras
Jul 04, 2017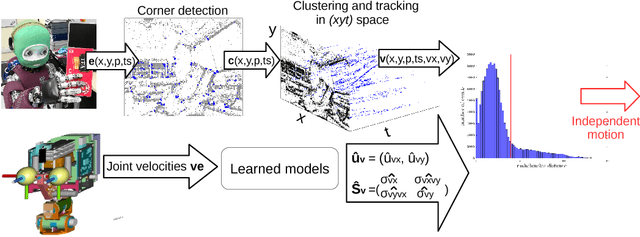

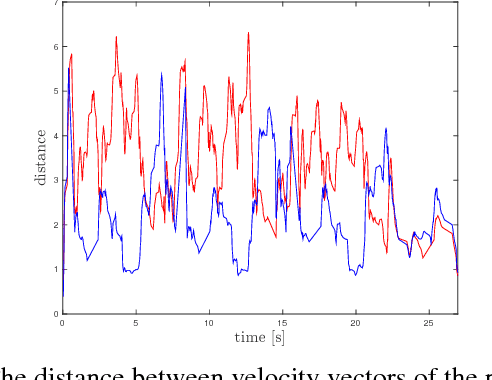
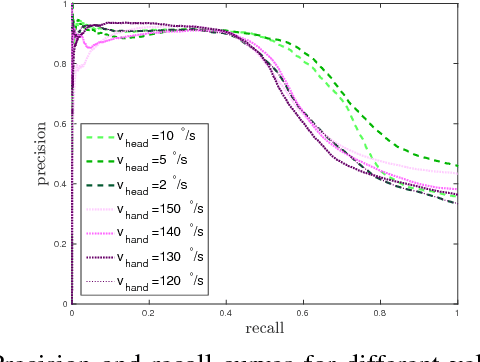
Unlike standard cameras that send intensity images at a constant frame rate, event-driven cameras asynchronously report pixel-level brightness changes, offering low latency and high temporal resolution (both in the order of micro-seconds). As such, they have great potential for fast and low power vision algorithms for robots. Visual tracking, for example, is easily achieved even for very fast stimuli, as only moving objects cause brightness changes. However, cameras mounted on a moving robot are typically non-stationary and the same tracking problem becomes confounded by background clutter events due to the robot ego-motion. In this paper, we propose a method for segmenting the motion of an independently moving object for event-driven cameras. Our method detects and tracks corners in the event stream and learns the statistics of their motion as a function of the robot's joint velocities when no independently moving objects are present. During robot operation, independently moving objects are identified by discrepancies between the predicted corner velocities from ego-motion and the measured corner velocities. We validate the algorithm on data collected from the neuromorphic iCub robot. We achieve a precision of ~ 90 % and show that the method is robust to changes in speed of both the head and the target.
Event-based Camera Pose Tracking using a Generative Event Model
Oct 07, 2015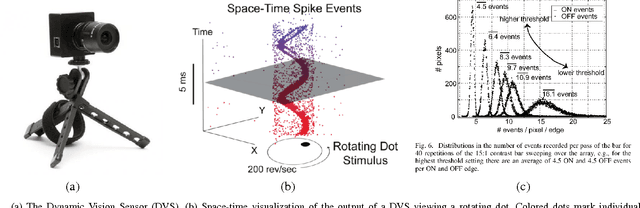
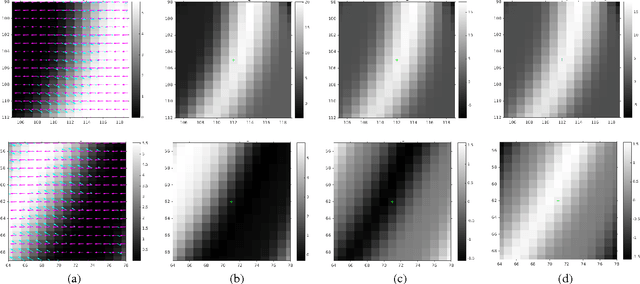
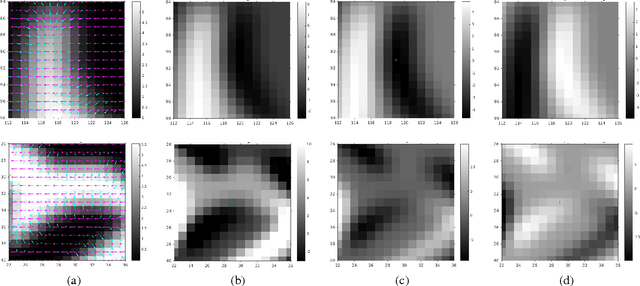
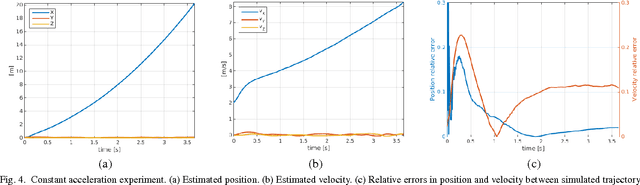
Event-based vision sensors mimic the operation of biological retina and they represent a major paradigm shift from traditional cameras. Instead of providing frames of intensity measurements synchronously, at artificially chosen rates, event-based cameras provide information on brightness changes asynchronously, when they occur. Such non-redundant pieces of information are called "events". These sensors overcome some of the limitations of traditional cameras (response time, bandwidth and dynamic range) but require new methods to deal with the data they output. We tackle the problem of event-based camera localization in a known environment, without additional sensing, using a probabilistic generative event model in a Bayesian filtering framework. Our main contribution is the design of the likelihood function used in the filter to process the observed events. Based on the physical characteristics of the sensor and on empirical evidence of the Gaussian-like distribution of spiked events with respect to the brightness change, we propose to use the contrast residual as a measure of how well the estimated pose of the event-based camera and the environment explain the observed events. The filter allows for localization in the general case of six degrees-of-freedom motions.