 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaskAdapt: Learning Flexible Motion Adaptation via Mask-Invariant Prior for Physics-Based Characters
Apr 02, 2026We present MaskAdapt, a framework for flexible motion adaptation in physics-based humanoid control. The framework follows a two-stage residual learning paradigm. In the first stage, we train a mask-invariant base policy using stochastic body-part masking and a regularization term that enforces consistent action distributions across masking conditions. This yields a robust motion prior that remains stable under missing observations, anticipating later adaptation in those regions. In the second stage, a residual policy is trained atop the frozen base controller to modify only the targeted body parts while preserving the original behaviors elsewhere. We demonstrate the versatility of this design through two applications: (i) motion composition, where varying masks enable multi-part adaptation within a single sequence, and (ii) text-driven partial goal tracking, where designated body parts follow kinematic targets provided by a pre-trained text-conditioned autoregressive motion generator. Through experiments, MaskAdapt demonstrates strong robustness and adaptability, producing diverse behaviors under masked observations and delivering superior targeted motion adaptation compared to prior work.
Scene-agnostic Hierarchical Bimanual Task Planning via Visual Affordance Reasoning
Dec 10, 2025Embodied agents operating in open environments must translate high-level instructions into grounded, executable behaviors, often requiring coordinated use of both hands. While recent foundation models offer strong semantic reasoning, existing robotic task planners remain predominantly unimanual and fail to address the spatial, geometric, and coordination challenges inherent to bimanual manipulation in scene-agnostic settings. We present a unified framework for scene-agnostic bimanual task planning that bridges high-level reasoning with 3D-grounded two-handed execution. Our approach integrates three key modules. Visual Point Grounding (VPG) analyzes a single scene image to detect relevant objects and generate world-aligned interaction points. Bimanual Subgoal Planner (BSP) reasons over spatial adjacency and cross-object accessibility to produce compact, motion-neutralized subgoals that exploit opportunities for coordinated two-handed actions. Interaction-Point-Driven Bimanual Prompting (IPBP) binds these subgoals to a structured skill library, instantiating synchronized unimanual or bimanual action sequences that satisfy hand-state and affordance constraints. Together, these modules enable agents to plan semantically meaningful, physically feasible, and parallelizable two-handed behaviors in cluttered, previously unseen scenes. Experiments show that it produces coherent, feasible, and compact two-handed plans, and generalizes to cluttered scenes without retraining, demonstrating robust scene-agnostic affordance reasoning for bimanual tasks.
DivaTrack: Diverse Bodies and Motions from Acceleration-Enhanced Three-Point Trackers
Feb 14, 2024Full-body avatar presence is crucial for immersive social and environmental interactions in digital reality. However, current devices only provide three six degrees of freedom (DOF) poses from the headset and two controllers (i.e. three-point trackers). Because it is a highly under-constrained problem, inferring full-body pose from these inputs is challenging, especially when supporting the full range of body proportions and use cases represented by the general population. In this paper, we propose a deep learning framework, DivaTrack, which outperforms existing methods when applied to diverse body sizes and activities. We augment the sparse three-point inputs with linear accelerations from Inertial Measurement Units (IMU) to improve foot contact prediction. We then condition the otherwise ambiguous lower-body pose with the predictions of foot contact and upper-body pose in a two-stage model. We further stabilize the inferred full-body pose in a wide range of configurations by learning to blend predictions that are computed in two reference frames, each of which is designed for different types of motions. We demonstrate the effectiveness of our design on a large dataset that captures 22 subjects performing challenging locomotion for three-point tracking, including lunges, hula-hooping, and sitting. As shown in a live demo using the Meta VR headset and Xsens IMUs, our method runs in real-time while accurately tracking a user's motion when they perform a diverse set of movements.
SPnet: Estimating Garment Sewing Patterns from a Single Image
Dec 26, 2023This paper presents a novel method for reconstructing 3D garment models from a single image of a posed user. Previous studies that have primarily focused on accurately reconstructing garment geometries to match the input garment image may often result in unnatural-looking garments when deformed for new poses. To overcome this limitation, our approach takes a different approach by inferring the fundamental shape of the garment through sewing patterns from a single image, rather than directly reconstructing 3D garments. Our method consists of two stages. Firstly, given a single image of a posed user, it predicts the garment image worn on a T-pose, representing the baseline form of the garment. Then, it estimates the sewing pattern parameters based on the T-pose garment image. By simulating the stitching and draping of the sewing pattern using physics simulation, we can generate 3D garments that can adaptively deform to arbitrary poses. The effectiveness of our method is validated through ablation studies on the major components and a comparison with other approaches.
DeepIron: Predicting Unwarped Garment Texture from a Single Image
Oct 26, 2023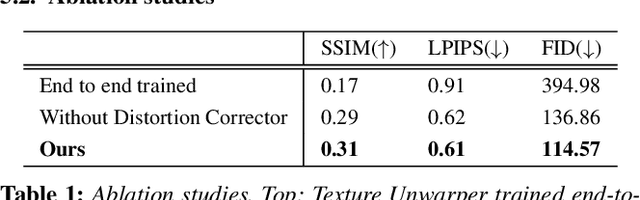
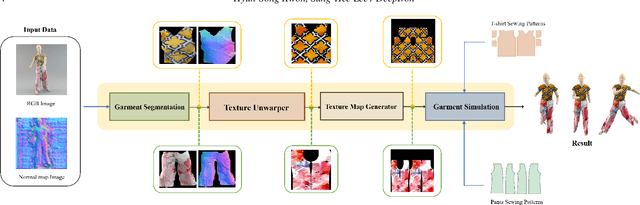
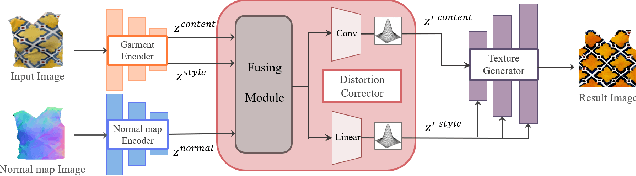
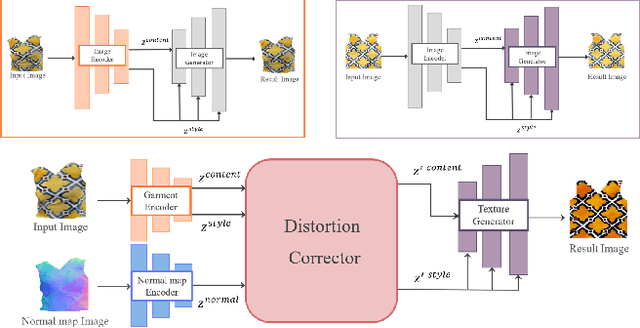
Realistic reconstruction of 3D clothing from an image has wide applications, such as avatar creation and virtual try-on. This paper presents a novel framework that reconstructs the texture map for 3D garments from a single image with pose. Assuming that 3D garments are modeled by stitching 2D garment sewing patterns, our specific goal is to generate a texture image for the sewing patterns. A key component of our framework, the Texture Unwarper, infers the original texture image from the input clothing image, which exhibits warping and occlusion of texture due to the user's body shape and pose. The Texture Unwarper effectively transforms between the input and output images by mapping the latent spaces of the two images. By inferring the unwarped original texture of the input garment, our method helps reconstruct 3D garment models that can show high-quality texture images realistically deformed for new poses. We validate the effectiveness of our approach through a comparison with other methods and ablation studies.
MOCHA: Real-Time Motion Characterization via Context Matching
Oct 16, 2023



Transforming neutral, characterless input motions to embody the distinct style of a notable character in real time is highly compelling for character animation. This paper introduces MOCHA, a novel online motion characterization framework that transfers both motion styles and body proportions from a target character to an input source motion. MOCHA begins by encoding the input motion into a motion feature that structures the body part topology and captures motion dependencies for effective characterization. Central to our framework is the Neural Context Matcher, which generates a motion feature for the target character with the most similar context to the input motion feature. The conditioned autoregressive model of the Neural Context Matcher can produce temporally coherent character features in each time frame. To generate the final characterized pose, our Characterizer network incorporates the characteristic aspects of the target motion feature into the input motion feature while preserving its context. This is achieved through a transformer model that introduces the adaptive instance normalization and context mapping-based cross-attention, effectively injecting the character feature into the source feature. We validate the performance of our framework through comparisons with prior work and an ablation study. Our framework can easily accommodate various applications, including characterization with only sparse input and real-time characterization. Additionally, we contribute a high-quality motion dataset comprising six different characters performing a range of motions, which can serve as a valuable resource for future research.
MOVIN: Real-time Motion Capture using a Single LiDAR
Sep 17, 2023Recent advancements in technology have brought forth new forms of interactive applications, such as the social metaverse, where end users interact with each other through their virtual avatars. In such applications, precise full-body tracking is essential for an immersive experience and a sense of embodiment with the virtual avatar. However, current motion capture systems are not easily accessible to end users due to their high cost, the requirement for special skills to operate them, or the discomfort associated with wearable devices. In this paper, we present MOVIN, the data-driven generative method for real-time motion capture with global tracking, using a single LiDAR sensor. Our autoregressive conditional variational autoencoder (CVAE) model learns the distribution of pose variations conditioned on the given 3D point cloud from LiDAR.As a central factor for high-accuracy motion capture, we propose a novel feature encoder to learn the correlation between the historical 3D point cloud data and global, local pose features, resulting in effective learning of the pose prior. Global pose features include root translation, rotation, and foot contacts, while local features comprise joint positions and rotations. Subsequently, a pose generator takes into account the sampled latent variable along with the features from the previous frame to generate a plausible current pose. Our framework accurately predicts the performer's 3D global information and local joint details while effectively considering temporally coherent movements across frames. We demonstrate the effectiveness of our architecture through quantitative and qualitative evaluations, comparing it against state-of-the-art methods. Additionally, we implement a real-time application to showcase our method in real-world scenarios. MOVIN dataset is available at \url{https://movin3d.github.io/movin_pg2023/}.
Motion Puzzle: Arbitrary Motion Style Transfer by Body Part
Feb 10, 2022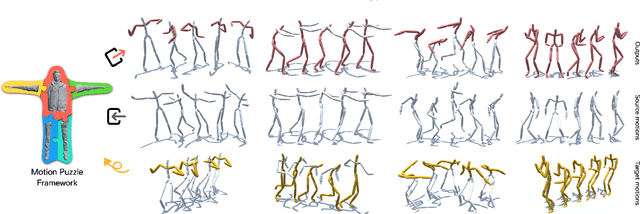
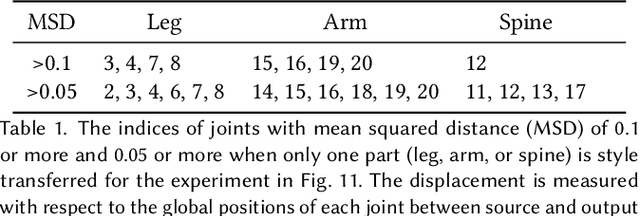
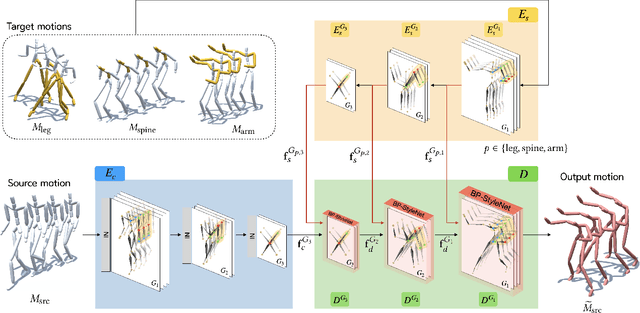

This paper presents Motion Puzzle, a novel motion style transfer network that advances the state-of-the-art in several important respects. The Motion Puzzle is the first that can control the motion style of individual body parts, allowing for local style editing and significantly increasing the range of stylized motions. Designed to keep the human's kinematic structure, our framework extracts style features from multiple style motions for different body parts and transfers them locally to the target body parts. Another major advantage is that it can transfer both global and local traits of motion style by integrating the adaptive instance normalization and attention modules while keeping the skeleton topology. Thus, it can capture styles exhibited by dynamic movements, such as flapping and staggering, significantly better than previous work. In addition, our framework allows for arbitrary motion style transfer without datasets with style labeling or motion pairing, making many publicly available motion datasets available for training. Our framework can be easily integrated with motion generation frameworks to create many applications, such as real-time motion transfer. We demonstrate the advantages of our framework with a number of examples and comparisons with previous work.
* 16 pages
NeuralTailor: Reconstructing Sewing Pattern Structures from 3D Point Clouds of Garments
Jan 31, 2022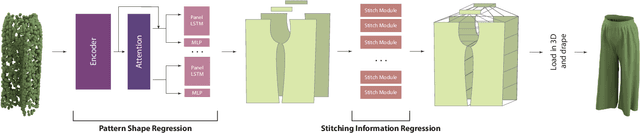
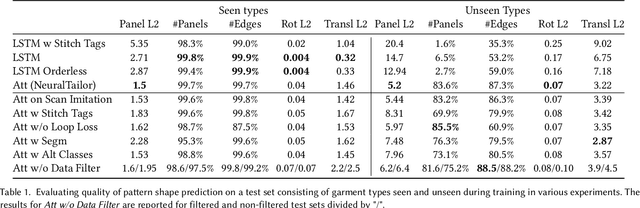

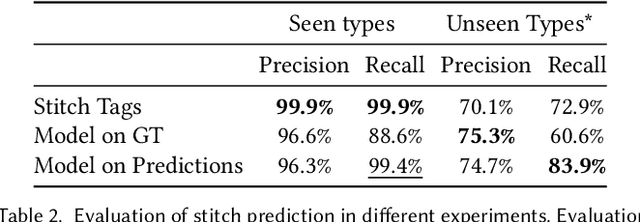
The fields of SocialVR, performance capture, and virtual try-on are often faced with a need to faithfully reproduce real garments in the virtual world. One critical task is the disentanglement of the intrinsic garment shape from deformations due to fabric properties, physical forces, and contact with the body. We propose to use a garment sewing pattern, a realistic and compact garment descriptor, to facilitate the intrinsic garment shape estimation. Another major challenge is a high diversity of shapes and designs in the domain. The most common approach for Deep Learning on 3D garments is to build specialized models for individual garments or garment types. We argue that building a unified model for various garment designs has the benefit of generalization to novel garment types, hence covering a larger design domain than individual models would. We introduce NeuralTailor, a novel architecture based on point-level attention for set regression with variable cardinality, and apply it to the task of reconstructing 2D garment sewing patterns from the 3D point could garment models. Our experiments show that NeuralTailor successfully reconstructs sewing patterns and generalizes to garment types with pattern topologies unseen during training.
Generating Datasets of 3D Garments with Sewing Patterns
Sep 12, 2021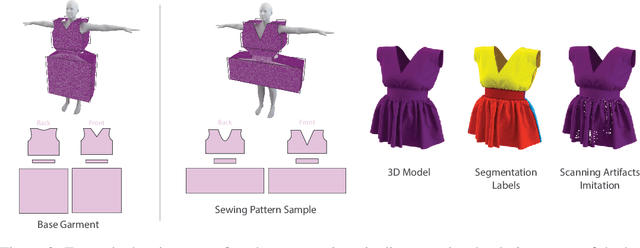
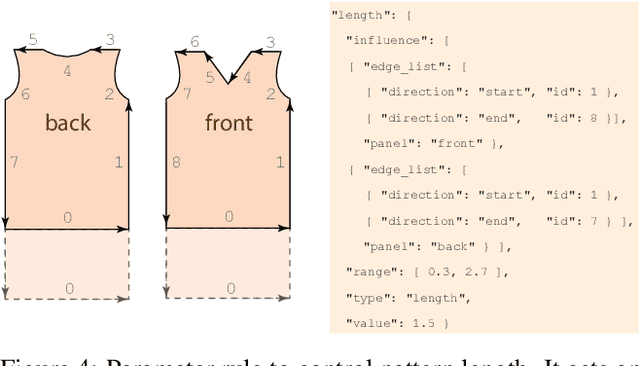
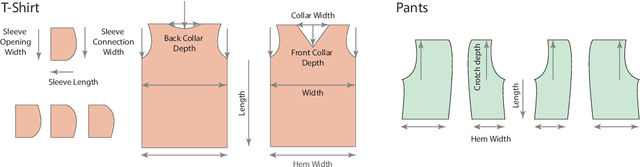
Garments are ubiquitous in both real and many of the virtual worlds. They are highly deformable objects, exhibit an immense variety of designs and shapes, and yet, most garments are created from a set of regularly shaped flat pieces. Exploration of garment structure presents a peculiar case for an object structure estimation task and might prove useful for downstream tasks of neural 3D garment modeling and reconstruction by providing strong prior on garment shapes. To facilitate research in these directions, we propose a method for generating large synthetic datasets of 3D garment designs and their sewing patterns. Our method consists of a flexible description structure for specifying parametric sewing pattern templates and the automatic generation pipeline to produce garment 3D models with little-to-none manual intervention. To add realism, the pipeline additionally creates corrupted versions of the final meshes that imitate artifacts of 3D scanning. With this pipeline, we created the first large-scale synthetic dataset of 3D garment models with their sewing patterns. The dataset contains more than 20000 garment design variations produced from 19 different base types. Seven of these garment types are specifically designed to target evaluation of the generalization across garment sewing pattern topologies.