 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeELMO: Enhanced Real-time LiDAR Motion Capture through Upsampling
Oct 09, 2024



This paper introduces ELMO, a real-time upsampling motion capture framework designed for a single LiDAR sensor. Modeled as a conditional autoregressive transformer-based upsampling motion generator, ELMO achieves 60 fps motion capture from a 20 fps LiDAR point cloud sequence. The key feature of ELMO is the coupling of the self-attention mechanism with thoughtfully designed embedding modules for motion and point clouds, significantly elevating the motion quality. To facilitate accurate motion capture, we develop a one-time skeleton calibration model capable of predicting user skeleton offsets from a single-frame point cloud. Additionally, we introduce a novel data augmentation technique utilizing a LiDAR simulator, which enhances global root tracking to improve environmental understanding. To demonstrate the effectiveness of our method, we compare ELMO with state-of-the-art methods in both image-based and point cloud-based motion capture. We further conduct an ablation study to validate our design principles. ELMO's fast inference time makes it well-suited for real-time applications, exemplified in our demo video featuring live streaming and interactive gaming scenarios. Furthermore, we contribute a high-quality LiDAR-mocap synchronized dataset comprising 20 different subjects performing a range of motions, which can serve as a valuable resource for future research. The dataset and evaluation code are available at {\blue \url{https://movin3d.github.io/ELMO_SIGASIA2024/}}
MOCHA: Real-Time Motion Characterization via Context Matching
Oct 16, 2023



Transforming neutral, characterless input motions to embody the distinct style of a notable character in real time is highly compelling for character animation. This paper introduces MOCHA, a novel online motion characterization framework that transfers both motion styles and body proportions from a target character to an input source motion. MOCHA begins by encoding the input motion into a motion feature that structures the body part topology and captures motion dependencies for effective characterization. Central to our framework is the Neural Context Matcher, which generates a motion feature for the target character with the most similar context to the input motion feature. The conditioned autoregressive model of the Neural Context Matcher can produce temporally coherent character features in each time frame. To generate the final characterized pose, our Characterizer network incorporates the characteristic aspects of the target motion feature into the input motion feature while preserving its context. This is achieved through a transformer model that introduces the adaptive instance normalization and context mapping-based cross-attention, effectively injecting the character feature into the source feature. We validate the performance of our framework through comparisons with prior work and an ablation study. Our framework can easily accommodate various applications, including characterization with only sparse input and real-time characterization. Additionally, we contribute a high-quality motion dataset comprising six different characters performing a range of motions, which can serve as a valuable resource for future research.
MOVIN: Real-time Motion Capture using a Single LiDAR
Sep 17, 2023Recent advancements in technology have brought forth new forms of interactive applications, such as the social metaverse, where end users interact with each other through their virtual avatars. In such applications, precise full-body tracking is essential for an immersive experience and a sense of embodiment with the virtual avatar. However, current motion capture systems are not easily accessible to end users due to their high cost, the requirement for special skills to operate them, or the discomfort associated with wearable devices. In this paper, we present MOVIN, the data-driven generative method for real-time motion capture with global tracking, using a single LiDAR sensor. Our autoregressive conditional variational autoencoder (CVAE) model learns the distribution of pose variations conditioned on the given 3D point cloud from LiDAR.As a central factor for high-accuracy motion capture, we propose a novel feature encoder to learn the correlation between the historical 3D point cloud data and global, local pose features, resulting in effective learning of the pose prior. Global pose features include root translation, rotation, and foot contacts, while local features comprise joint positions and rotations. Subsequently, a pose generator takes into account the sampled latent variable along with the features from the previous frame to generate a plausible current pose. Our framework accurately predicts the performer's 3D global information and local joint details while effectively considering temporally coherent movements across frames. We demonstrate the effectiveness of our architecture through quantitative and qualitative evaluations, comparing it against state-of-the-art methods. Additionally, we implement a real-time application to showcase our method in real-world scenarios. MOVIN dataset is available at \url{https://movin3d.github.io/movin_pg2023/}.
Motion Puzzle: Arbitrary Motion Style Transfer by Body Part
Feb 10, 2022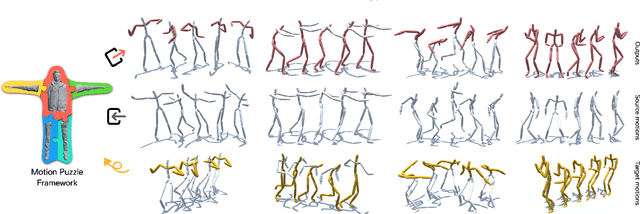
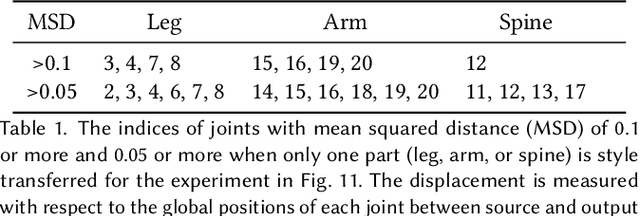
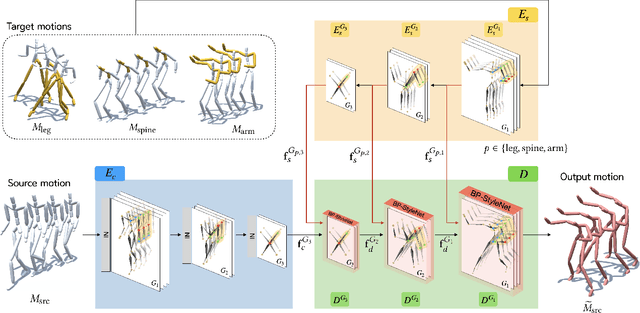

This paper presents Motion Puzzle, a novel motion style transfer network that advances the state-of-the-art in several important respects. The Motion Puzzle is the first that can control the motion style of individual body parts, allowing for local style editing and significantly increasing the range of stylized motions. Designed to keep the human's kinematic structure, our framework extracts style features from multiple style motions for different body parts and transfers them locally to the target body parts. Another major advantage is that it can transfer both global and local traits of motion style by integrating the adaptive instance normalization and attention modules while keeping the skeleton topology. Thus, it can capture styles exhibited by dynamic movements, such as flapping and staggering, significantly better than previous work. In addition, our framework allows for arbitrary motion style transfer without datasets with style labeling or motion pairing, making many publicly available motion datasets available for training. Our framework can be easily integrated with motion generation frameworks to create many applications, such as real-time motion transfer. We demonstrate the advantages of our framework with a number of examples and comparisons with previous work.
* 16 pages