 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D3L: Deep Learned 3D Keypoint Detection and Description for LiDARs
Apr 12, 2021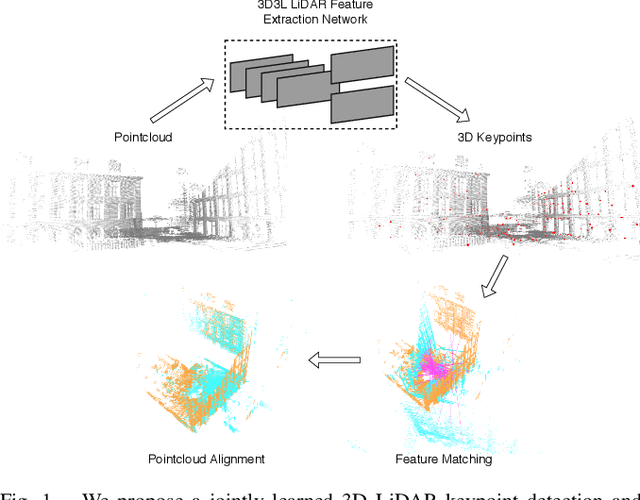
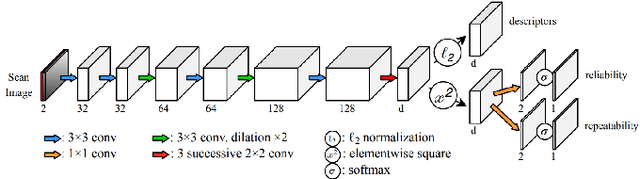
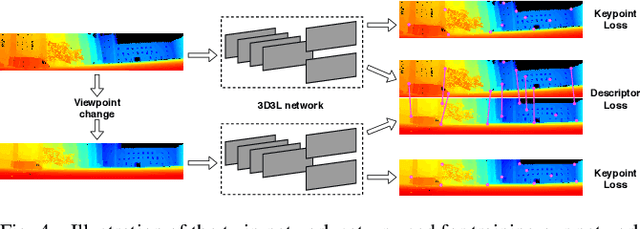

With the advent of powerful, light-weight 3D LiDARs, they have become the hearth of many navigation and SLAM algorithms on various autonomous systems. Pointcloud registration methods working with unstructured pointclouds such as ICP are often computationally expensive or require a good initial guess. Furthermore, 3D feature-based registration methods have never quite reached the robustness of 2D methods in visual SLAM. With the continuously increasing resolution of LiDAR range images, these 2D methods not only become applicable but should exploit the illumination-independent modalities that come with it, such as depth and intensity. In visual SLAM, deep learned 2D features and descriptors perform exceptionally well compared to traditional methods. In this publication, we use a state-of-the-art 2D feature network as a basis for 3D3L, exploiting both intensity and depth of LiDAR range images to extract powerful 3D features. Our results show that these keypoints and descriptors extracted from LiDAR scan images outperform state-of-the-art on different benchmark metrics and allow for robust scan-to-scan alignment as well as global localization.