 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProSMA-UNet: Decoder Conditioning for Proximal-Sparse Skip Feature Selection
Mar 04, 2026Medical image segmentation commonly relies on U-shaped encoder-decoder architectures such as U-Net, where skip connections preserve fine spatial detail by injecting high-resolution encoder features into the decoder. However, these skip pathways also propagate low-level textures, background clutter, and acquisition noise, allowing irrelevant information to bypass deeper semantic filtering -- an issue that is particularly detrimental in low-contrast clinical imaging. Although attention gates have been introduced to address this limitation, they typically produce dense sigmoid masks that softly reweight features rather than explicitly removing irrelevant activations. We propose ProSMA-UNet (Proximal-Sparse Multi-Scale Attention U-Net), which reformulates skip gating as a decoder-conditioned sparse feature selection problem. ProSMA constructs a multi-scale compatibility field using lightweight depthwise dilated convolutions to capture relevance across local and contextual scales, then enforces explicit sparsity via an $\ell_1$ proximal operator with learnable per-channel thresholds, yielding a closed-form soft-thresholding gate that can remove noisy responses. To further suppress semantically irrelevant channels, ProSMA incorporates decoder-conditioned channel gating driven by global decoder context. Extensive experiments on challenging 2D and 3D benchmarks demonstrate state-of-the-art performance, with particularly large gains ($\approx20$\%) on difficult 3D segmentation tasks. Project page: https://math-ml-x.github.io/ProSMA-UNet/
Deep Spectral Prior
May 26, 2025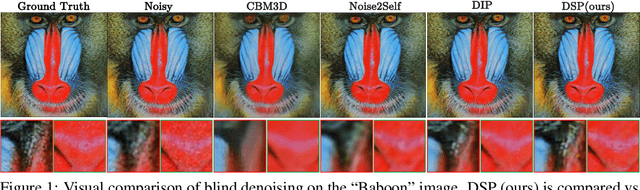
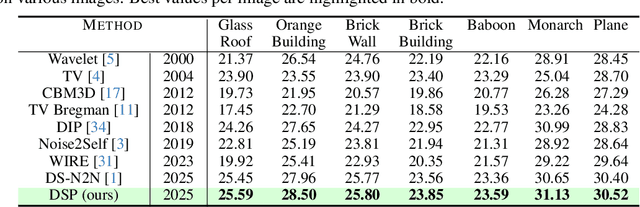


We introduce Deep Spectral Prior (DSP), a new formulation of Deep Image Prior (DIP) that redefines image reconstruction as a frequency-domain alignment problem. Unlike traditional DIP, which relies on pixel-wise loss and early stopping to mitigate overfitting, DSP directly matches Fourier coefficients between the network output and observed measurements. This shift introduces an explicit inductive bias towards spectral coherence, aligning with the known frequency structure of images and the spectral bias of convolutional neural networks. We provide a rigorous theoretical framework demonstrating that DSP acts as an implicit spectral regulariser, suppressing high-frequency noise by design and eliminating the need for early stopping. Our analysis spans four core dimensions establishing smooth convergence dynamics, local stability, and favourable bias-variance tradeoffs. We further show that DSP naturally projects reconstructions onto a frequency-consistent manifold, enhancing interpretability and robustness. These theoretical guarantees are supported by empirical results across denoising, inpainting, and super-resolution tasks, where DSP consistently outperforms classical DIP and other unsupervised baselines.
D2SA: Dual-Stage Distribution and Slice Adaptation for Efficient Test-Time Adaptation in MRI Reconstruction
Mar 25, 2025Variations in Magnetic resonance imaging (MRI) scanners and acquisition protocols cause distribution shifts that degrade reconstruction performance on unseen data. Test-time adaptation (TTA) offers a promising solution to address this discrepancies. However, previous single-shot TTA approaches are inefficient due to repeated training and suboptimal distributional models. Self-supervised learning methods are also limited by scarce date scenarios. To address these challenges, we propose a novel Dual-Stage Distribution and Slice Adaptation (D2SA) via MRI implicit neural representation (MR-INR) to improve MRI reconstruction performance and efficiency, which features two stages. In the first stage, an MR-INR branch performs patient-wise distribution adaptation by learning shared representations across slices and modelling patient-specific shifts with mean and variance adjustments. In the second stage, single-slice adaptation refines the output from frozen convolutional layers with a learnable anisotropic diffusion module, preventing over-smoothing and reducing computation. Experiments across four MRI distribution shifts demonstrate that our method can integrate well with various self-supervised learning (SSL) framework, improving performance and accelerating convergence under diverse conditions.
Implicit U-KAN2.0: Dynamic, Efficient and Interpretable Medical Image Segmentation
Mar 05, 2025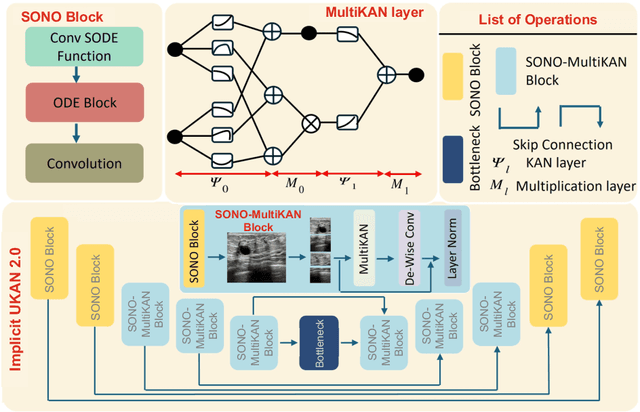
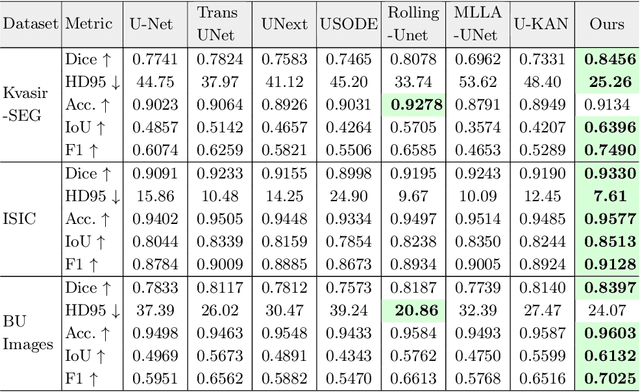
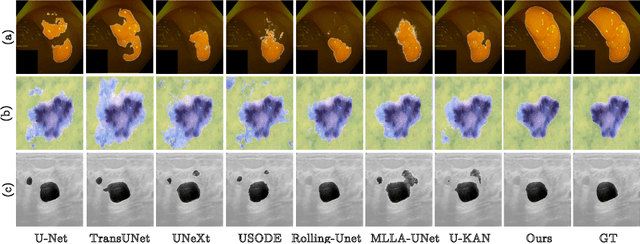

Image segmentation is a fundamental task in both image analysis and medical applications. State-of-the-art methods predominantly rely on encoder-decoder architectures with a U-shaped design, commonly referred to as U-Net. Recent advancements integrating transformers and MLPs improve performance but still face key limitations, such as poor interpretability, difficulty handling intrinsic noise, and constrained expressiveness due to discrete layer structures, often lacking a solid theoretical foundation.In this work, we introduce Implicit U-KAN 2.0, a novel U-Net variant that adopts a two-phase encoder-decoder structure. In the SONO phase, we use a second-order neural ordinary differential equation (NODEs), called the SONO block, for a more efficient, expressive, and theoretically grounded modeling approach. In the SONO-MultiKAN phase, we integrate the second-order NODEs and MultiKAN layer as the core computational block to enhance interpretability and representation power. Our contributions are threefold. First, U-KAN 2.0 is an implicit deep neural network incorporating MultiKAN and second order NODEs, improving interpretability and performance while reducing computational costs. Second, we provide a theoretical analysis demonstrating that the approximation ability of the MultiKAN block is independent of the input dimension. Third, we conduct extensive experiments on a variety of 2D and a single 3D dataset, demonstrating that our model consistently outperforms existing segmentation networks.
You KAN Do It in a Single Shot: Plug-and-Play Methods with Single-Instance Priors
Dec 09, 2024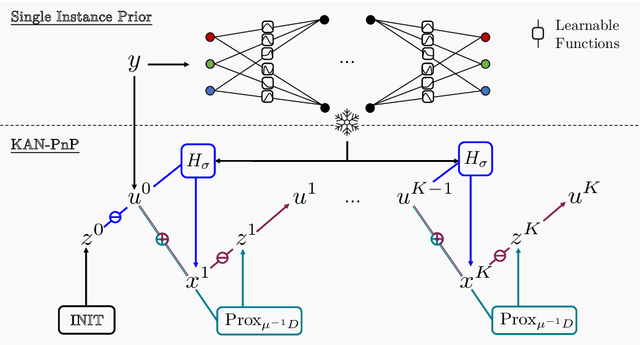
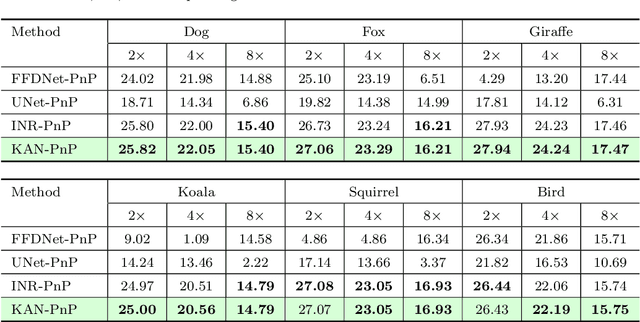

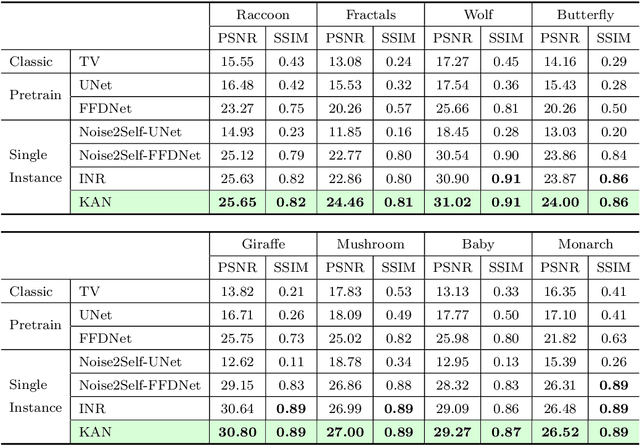
The use of Plug-and-Play (PnP) methods has become a central approach for solving inverse problems, with denoisers serving as regularising priors that guide optimisation towards a clean solution. In this work, we introduce KAN-PnP, an optimisation framework that incorporates Kolmogorov-Arnold Networks (KANs) as denoisers within the Plug-and-Play (PnP) paradigm. KAN-PnP is specifically designed to solve inverse problems with single-instance priors, where only a single noisy observation is available, eliminating the need for large datasets typically required by traditional denoising methods. We show that KANs, based on the Kolmogorov-Arnold representation theorem, serve effectively as priors in such settings, providing a robust approach to denoising. We prove that the KAN denoiser is Lipschitz continuous, ensuring stability and convergence in optimisation algorithms like PnP-ADMM, even in the context of single-shot learning. Additionally, we provide theoretical guarantees for KAN-PnP, demonstrating its convergence under key conditions: the convexity of the data fidelity term, Lipschitz continuity of the denoiser, and boundedness of the regularisation functional. These conditions are crucial for stable and reliable optimisation. Our experimental results show, on super-resolution and joint optimisation, that KAN-PnP outperforms exiting methods, delivering superior performance in single-shot learning with minimal data. The method exhibits strong convergence properties, achieving high accuracy with fewer iterations.
Where Do We Stand with Implicit Neural Representations? A Technical and Performance Survey
Nov 06, 2024



Implicit Neural Representations (INRs) have emerged as a paradigm in knowledge representation, offering exceptional flexibility and performance across a diverse range of applications. INRs leverage multilayer perceptrons (MLPs) to model data as continuous implicit functions, providing critical advantages such as resolution independence, memory efficiency, and generalisation beyond discretised data structures. Their ability to solve complex inverse problems makes them particularly effective for tasks including audio reconstruction, image representation, 3D object reconstruction, and high-dimensional data synthesis. This survey provides a comprehensive review of state-of-the-art INR methods, introducing a clear taxonomy that categorises them into four key areas: activation functions, position encoding, combined strategies, and network structure optimisation. We rigorously analyse their critical properties, such as full differentiability, smoothness, compactness, and adaptability to varying resolutions while also examining their strengths and limitations in addressing locality biases and capturing fine details. Our experimental comparison offers new insights into the trade-offs between different approaches, showcasing the capabilities and challenges of the latest INR techniques across various tasks. In addition to identifying areas where current methods excel, we highlight key limitations and potential avenues for improvement, such as developing more expressive activation functions, enhancing positional encoding mechanisms, and improving scalability for complex, high-dimensional data. This survey serves as a roadmap for researchers, offering practical guidance for future exploration in the field of INRs. We aim to foster new methodologies by outlining promising research directions for INRs and applications.
Biophysics Informed Pathological Regularisation for Brain Tumour Segmentation
Mar 18, 2024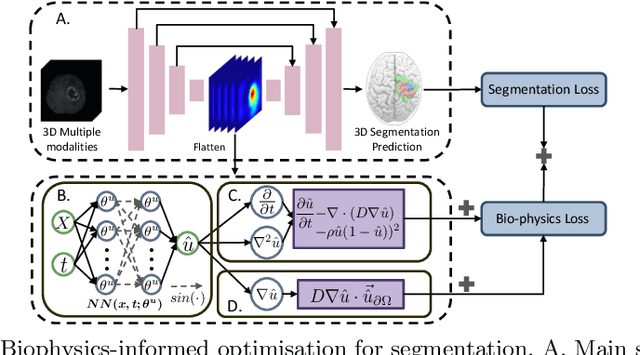
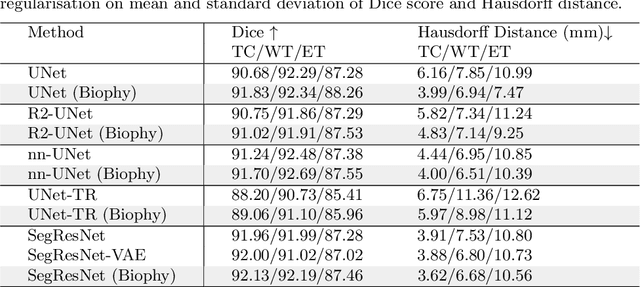
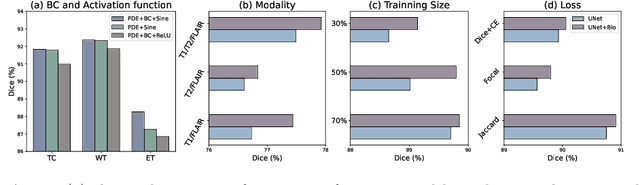
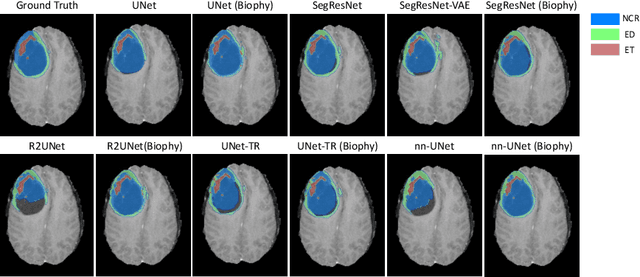
Recent advancements in deep learning have significantly improved brain tumour segmentation techniques; however, the results still lack confidence and robustness as they solely consider image data without biophysical priors or pathological information. Integrating biophysics-informed regularisation is one effective way to change this situation, as it provides an prior regularisation for automated end-to-end learning. In this paper, we propose a novel approach that designs brain tumour growth Partial Differential Equation (PDE) models as a regularisation with deep learning, operational with any network model. Our method introduces tumour growth PDE models directly into the segmentation process, improving accuracy and robustness, especially in data-scarce scenarios. This system estimates tumour cell density using a periodic activation function. By effectively integrating this estimation with biophysical models, we achieve a better capture of tumour characteristics. This approach not only aligns the segmentation closer to actual biological behaviour but also strengthens the model's performance under limited data conditions. We demonstrate the effectiveness of our framework through extensive experiments on the BraTS 2023 dataset, showcasing significant improvements in both precision and reliability of tumour segmentation.
TrafficMOT: A Challenging Dataset for Multi-Object Tracking in Complex Traffic Scenarios
Nov 30, 2023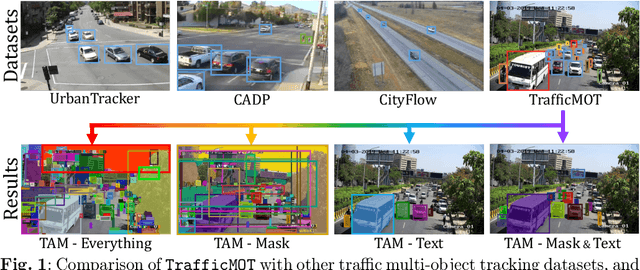
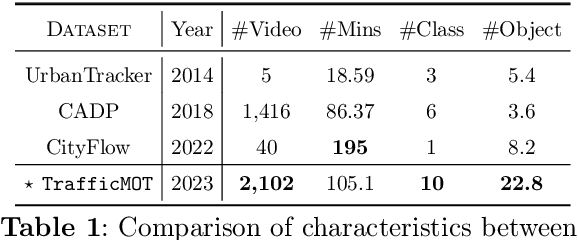

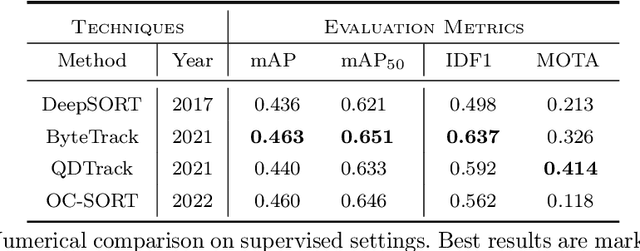
Multi-object tracking in traffic videos is a crucial research area, offering immense potential for enhancing traffic monitoring accuracy and promoting road safety measures through the utilisation of advanced machine learning algorithms. However, existing datasets for multi-object tracking in traffic videos often feature limited instances or focus on single classes, which cannot well simulate the challenges encountered in complex traffic scenarios. To address this gap, we introduce TrafficMOT, an extensive dataset designed to encompass diverse traffic situations with complex scenarios. To validate the complexity and challenges presented by TrafficMOT, we conducted comprehensive empirical studies using three different settings: fully-supervised, semi-supervised, and a recent powerful zero-shot foundation model Tracking Anything Model (TAM). The experimental results highlight the inherent complexity of this dataset, emphasising its value in driving advancements in the field of traffic monitoring and multi-object tracking.
Single-Shot Plug-and-Play Methods for Inverse Problems
Nov 22, 2023



The utilisation of Plug-and-Play (PnP) priors in inverse problems has become increasingly prominent in recent years. This preference is based on the mathematical equivalence between the general proximal operator and the regularised denoiser, facilitating the adaptation of various off-the-shelf denoiser priors to a wide range of inverse problems. However, existing PnP models predominantly rely on pre-trained denoisers using large datasets. In this work, we introduce Single-Shot PnP methods (SS-PnP), shifting the focus to solving inverse problems with minimal data. First, we integrate Single-Shot proximal denoisers into iterative methods, enabling training with single instances. Second, we propose implicit neural priors based on a novel function that preserves relevant frequencies to capture fine details while avoiding the issue of vanishing gradients. We demonstrate, through extensive numerical and visual experiments, that our method leads to better approximations.
TRIDENT: The Nonlinear Trilogy for Implicit Neural Representations
Nov 21, 2023



Implicit neural representations (INRs) have garnered significant interest recently for their ability to model complex, high-dimensional data without explicit parameterisation. In this work, we introduce TRIDENT, a novel function for implicit neural representations characterised by a trilogy of nonlinearities. Firstly, it is designed to represent high-order features through order compactness. Secondly, TRIDENT efficiently captures frequency information, a feature called frequency compactness. Thirdly, it has the capability to represent signals or images such that most of its energy is concentrated in a limited spatial region, denoting spatial compactness. We demonstrated through extensive experiments on various inverse problems that our proposed function outperforms existing implicit neural representation functions.