 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProSMA-UNet: Decoder Conditioning for Proximal-Sparse Skip Feature Selection
Mar 04, 2026Medical image segmentation commonly relies on U-shaped encoder-decoder architectures such as U-Net, where skip connections preserve fine spatial detail by injecting high-resolution encoder features into the decoder. However, these skip pathways also propagate low-level textures, background clutter, and acquisition noise, allowing irrelevant information to bypass deeper semantic filtering -- an issue that is particularly detrimental in low-contrast clinical imaging. Although attention gates have been introduced to address this limitation, they typically produce dense sigmoid masks that softly reweight features rather than explicitly removing irrelevant activations. We propose ProSMA-UNet (Proximal-Sparse Multi-Scale Attention U-Net), which reformulates skip gating as a decoder-conditioned sparse feature selection problem. ProSMA constructs a multi-scale compatibility field using lightweight depthwise dilated convolutions to capture relevance across local and contextual scales, then enforces explicit sparsity via an $\ell_1$ proximal operator with learnable per-channel thresholds, yielding a closed-form soft-thresholding gate that can remove noisy responses. To further suppress semantically irrelevant channels, ProSMA incorporates decoder-conditioned channel gating driven by global decoder context. Extensive experiments on challenging 2D and 3D benchmarks demonstrate state-of-the-art performance, with particularly large gains ($\approx20$\%) on difficult 3D segmentation tasks. Project page: https://math-ml-x.github.io/ProSMA-UNet/
MAP-Diff: Multi-Anchor Guided Diffusion for Progressive 3D Whole-Body Low-Dose PET Denoising
Mar 02, 2026Low-dose Positron Emission Tomography (PET) reduces radiation exposure but suffers from severe noise and quantitative degradation. Diffusion-based denoising models achieve strong final reconstructions, yet their reverse trajectories are typically unconstrained and not aligned with the progressive nature of PET dose formation. We propose MAP-Diff, a multi-anchor guided diffusion framework for progressive 3D whole-body PET denoising. MAP-Diff introduces clinically observed intermediate-dose scans as trajectory anchors and enforces timestep-dependent supervision to regularize the reverse process toward dose-aligned intermediate states. Anchor timesteps are calibrated via degradation matching between simulated diffusion corruption and real multi-dose PET pairs, and a timestep-weighted anchor loss stabilizes stage-wise learning. At inference, the model requires only ultra-low-dose input while enabling progressive, dose-consistent intermediate restoration. Experiments on internal (Siemens Biograph Vision Quadra) and cross-scanner (United Imaging uEXPLORER) datasets show consistent improvements over strong CNN-, Transformer-, GAN-, and diffusion-based baselines. On the internal dataset, MAP-Diff improves PSNR from 42.48 dB to 43.71 dB (+1.23 dB), increases SSIM to 0.986, and reduces NMAE from 0.115 to 0.103 (-0.012) compared to 3D DDPM. Performance gains generalize across scanners, achieving 34.42 dB PSNR and 0.141 NMAE on the external cohort, outperforming all competing methods.
SpectraKAN: Conditioning Spectral Operators
Feb 05, 2026Spectral neural operators, particularly Fourier Neural Operators (FNO), are a powerful framework for learning solution operators of partial differential equations (PDEs) due to their efficient global mixing in the frequency domain. However, existing spectral operators rely on static Fourier kernels applied uniformly across inputs, limiting their ability to capture multi-scale, regime-dependent, and anisotropic dynamics governed by the global state of the system. We introduce SpectraKAN, a neural operator that conditions the spectral operator on the input itself, turning static spectral convolution into an input-conditioned integral operator. This is achieved by extracting a compact global representation from spatio-temporal history and using it to modulate a multi-scale Fourier trunk via single-query cross-attention, enabling the operator to adapt its behaviour while retaining the efficiency of spectral mixing. We provide theoretical justification showing that this modulation converges to a resolution-independent continuous operator under mesh refinement and KAN gives smooth, Lipschitz-controlled global modulation. Across diverse PDE benchmarks, SpectraKAN achieves state-of-the-art performance, reducing RMSE by up to 49% over strong baselines, with particularly large gains on challenging spatio-temporal prediction tasks.
Product Interaction: An Algebraic Formalism for Deep Learning Architectures
Jan 31, 2026In this paper, we introduce product interactions, an algebraic formalism in which neural network layers are constructed from compositions of a multiplication operator defined over suitable algebras. Product interactions provide a principled way to generate and organize algebraic expressions by increasing interaction order. Our central observation is that algebraic expressions in modern neural networks admit a unified construction in terms of linear, quadratic, and higher-order product interactions. Convolutional and equivariant networks arise as symmetry-constrained linear product interactions, while attention and Mamba correspond to higher-order product interactions.
Training-Free Test-Time Adaptation with Brownian Distance Covariance in Vision-Language Models
Jan 30, 2026Vision-language models suffer performance degradation under domain shift, limiting real-world applicability. Existing test-time adaptation methods are computationally intensive, rely on back-propagation, and often focus on single modalities. To address these issues, we propose Training-free Test-Time Adaptation with Brownian Distance Covariance (TaTa). TaTa leverages Brownian Distance Covariance-a powerful statistical measure that captures both linear and nonlinear dependencies via pairwise distances-to dynamically adapt VLMs to new domains without training or back-propagation. This not only improves efficiency but also enhances stability by avoiding disruptive weight updates. TaTa further integrates attribute-enhanced prompting to improve vision-language inference with descriptive visual cues. Combined with dynamic clustering and pseudo-label refinement, it effectively recalibrates the model for novel visual contexts. Experiments across diverse datasets show that TaTa significantly reduces computational cost while achieving state-of-the-art performance in domain and cross-dataset generalization.
3D Wavelet-Based Structural Priors for Controlled Diffusion in Whole-Body Low-Dose PET Denoising
Jan 11, 2026Low-dose Positron Emission Tomography (PET) imaging reduces patient radiation exposure but suffers from increased noise that degrades image quality and diagnostic reliability. Although diffusion models have demonstrated strong denoising capability, their stochastic nature makes it challenging to enforce anatomically consistent structures, particularly in low signal-to-noise regimes and volumetric whole-body imaging. We propose Wavelet-Conditioned ControlNet (WCC-Net), a fully 3D diffusion-based framework that introduces explicit frequency-domain structural priors via wavelet representations to guide volumetric PET denoising. By injecting wavelet-based structural guidance into a frozen pretrained diffusion backbone through a lightweight control branch, WCC-Net decouples anatomical structure from noise while preserving generative expressiveness and 3D structural continuity. Extensive experiments demonstrate that WCC-Net consistently outperforms CNN-, GAN-, and diffusion-based baselines. On the internal 1/20-dose test set, WCC-Net improves PSNR by +1.21 dB and SSIM by +0.008 over a strong diffusion baseline, while reducing structural distortion (GMSD) and intensity error (NMAE). Moreover, WCC-Net generalizes robustly to unseen dose levels (1/50 and 1/4), achieving superior quantitative performance and improved volumetric anatomical consistency.
LEGATO: Good Identity Unlearning Is Continuous
Jan 07, 2026Machine unlearning has become a crucial role in enabling generative models trained on large datasets to remove sensitive, private, or copyright-protected data. However, existing machine unlearning methods face three challenges in learning to forget identity of generative models: 1) inefficient, where identity erasure requires fine-tuning all the model's parameters; 2) limited controllability, where forgetting intensity cannot be controlled and explainability is lacking; 3) catastrophic collapse, where the model's retention capability undergoes drastic degradation as forgetting progresses. Forgetting has typically been handled through discrete and unstable updates, often requiring full-model fine-tuning and leading to catastrophic collapse. In this work, we argue that identity forgetting should be modeled as a continuous trajectory, and introduce LEGATO - Learn to ForgEt Identity in GenerAtive Models via Trajectory-consistent Neural Ordinary Differential Equations. LEGATO augments pre-trained generators with fine-tunable lightweight Neural ODE adapters, enabling smooth, controllable forgetting while keeping the original model weights frozen. This formulation allows forgetting intensity to be precisely modulated via ODE step size, offering interpretability and robustness. To further ensure stability, we introduce trajectory consistency constraints that explicitly prevent catastrophic collapse during unlearning. Extensive experiments across in-domain and out-of-domain identity unlearning benchmarks show that LEGATO achieves state-of-the-art forgetting performance, avoids catastrophic collapse and reduces fine-tuned parameters.
Training-Free Dual Hyperbolic Adapters for Better Cross-Modal Reasoning
Dec 09, 2025Recent research in Vision-Language Models (VLMs) has significantly advanced our capabilities in cross-modal reasoning. However, existing methods suffer from performance degradation with domain changes or require substantial computational resources for fine-tuning in new domains. To address this issue, we develop a new adaptation method for large vision-language models, called \textit{Training-free Dual Hyperbolic Adapters} (T-DHA). We characterize the vision-language relationship between semantic concepts, which typically has a hierarchical tree structure, in the hyperbolic space instead of the traditional Euclidean space. Hyperbolic spaces exhibit exponential volume growth with radius, unlike the polynomial growth in Euclidean space. We find that this unique property is particularly effective for embedding hierarchical data structures using the Poincaré ball model, achieving significantly improved representation and discrimination power. Coupled with negative learning, it provides more accurate and robust classifications with fewer feature dimensions. Our extensive experimental results on various datasets demonstrate that the T-DHA method significantly outperforms existing state-of-the-art methods in few-shot image recognition and domain generalization tasks.
Implicit U-KAN2.0: Dynamic, Efficient and Interpretable Medical Image Segmentation
Mar 05, 2025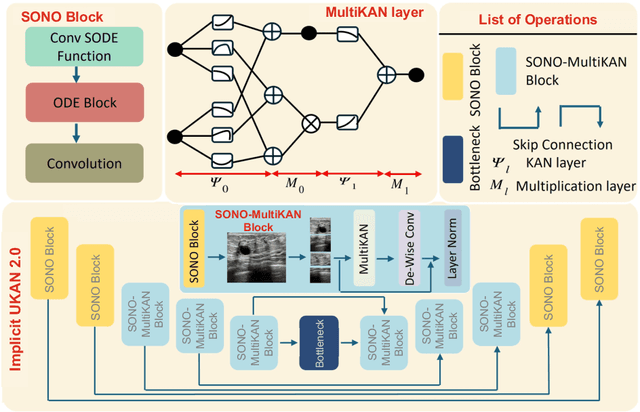
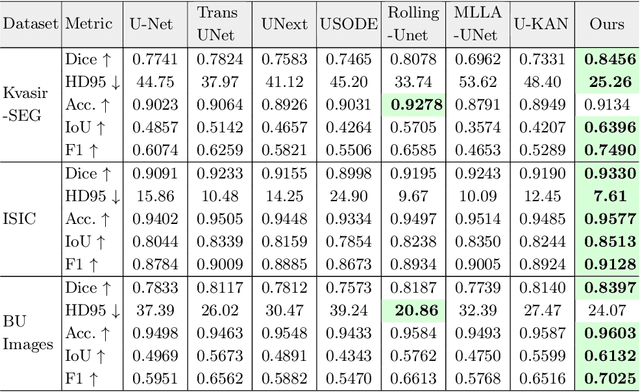
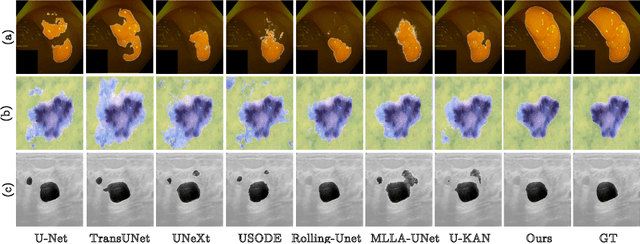

Image segmentation is a fundamental task in both image analysis and medical applications. State-of-the-art methods predominantly rely on encoder-decoder architectures with a U-shaped design, commonly referred to as U-Net. Recent advancements integrating transformers and MLPs improve performance but still face key limitations, such as poor interpretability, difficulty handling intrinsic noise, and constrained expressiveness due to discrete layer structures, often lacking a solid theoretical foundation.In this work, we introduce Implicit U-KAN 2.0, a novel U-Net variant that adopts a two-phase encoder-decoder structure. In the SONO phase, we use a second-order neural ordinary differential equation (NODEs), called the SONO block, for a more efficient, expressive, and theoretically grounded modeling approach. In the SONO-MultiKAN phase, we integrate the second-order NODEs and MultiKAN layer as the core computational block to enhance interpretability and representation power. Our contributions are threefold. First, U-KAN 2.0 is an implicit deep neural network incorporating MultiKAN and second order NODEs, improving interpretability and performance while reducing computational costs. Second, we provide a theoretical analysis demonstrating that the approximation ability of the MultiKAN block is independent of the input dimension. Third, we conduct extensive experiments on a variety of 2D and a single 3D dataset, demonstrating that our model consistently outperforms existing segmentation networks.
Cross-Modal Few-Shot Learning with Second-Order Neural Ordinary Differential Equations
Dec 20, 2024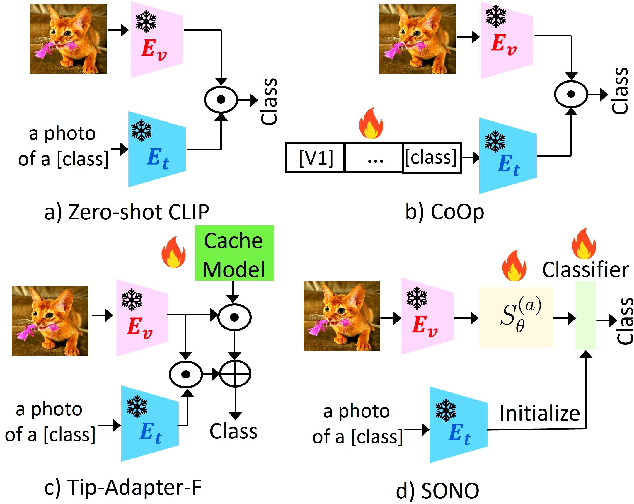
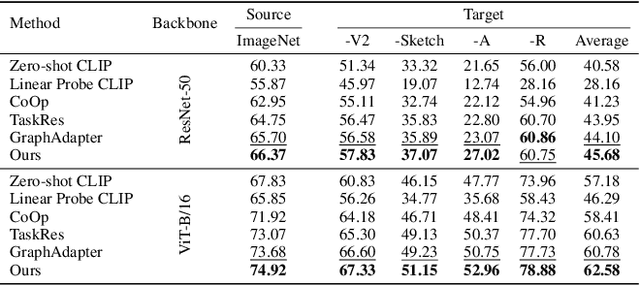
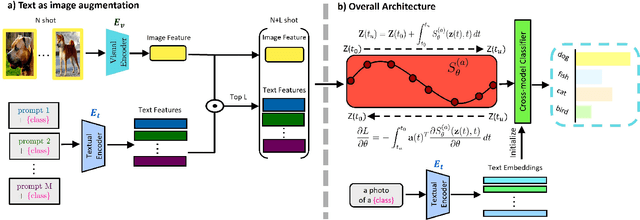
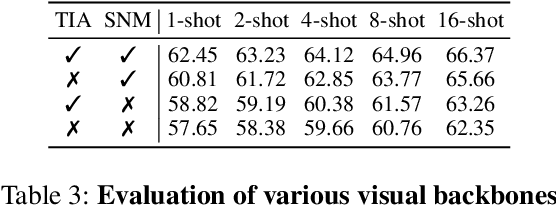
We introduce SONO, a novel method leveraging Second-Order Neural Ordinary Differential Equations (Second-Order NODEs) to enhance cross-modal few-shot learning. By employing a simple yet effective architecture consisting of a Second-Order NODEs model paired with a cross-modal classifier, SONO addresses the significant challenge of overfitting, which is common in few-shot scenarios due to limited training examples. Our second-order approach can approximate a broader class of functions, enhancing the model's expressive power and feature generalization capabilities. We initialize our cross-modal classifier with text embeddings derived from class-relevant prompts, streamlining training efficiency by avoiding the need for frequent text encoder processing. Additionally, we utilize text-based image augmentation, exploiting CLIP's robust image-text correlation to enrich training data significantly. Extensive experiments across multiple datasets demonstrate that SONO outperforms existing state-of-the-art methods in few-shot learning performance.