 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSmooth Model Compression without Fine-Tuning
May 30, 2025Compressing and pruning large machine learning models has become a critical step towards their deployment in real-world applications. Standard pruning and compression techniques are typically designed without taking the structure of the network's weights into account, limiting their effectiveness. We explore the impact of smooth regularization on neural network training and model compression. By applying nuclear norm, first- and second-order derivative penalties of the weights during training, we encourage structured smoothness while preserving predictive performance on par with non-smooth models. We find that standard pruning methods often perform better when applied to these smooth models. Building on this observation, we apply a Singular-Value-Decomposition-based compression method that exploits the underlying smooth structure and approximates the model's weight tensors by smaller low-rank tensors. Our approach enables state-of-the-art compression without any fine-tuning - reaching up to $91\%$ accuracy on a smooth ResNet-18 on CIFAR-10 with $70\%$ fewer parameters.
Training Data Reconstruction: Privacy due to Uncertainty?
Dec 11, 2024



Being able to reconstruct training data from the parameters of a neural network is a major privacy concern. Previous works have shown that reconstructing training data, under certain circumstances, is possible. In this work, we analyse such reconstructions empirically and propose a new formulation of the reconstruction as a solution to a bilevel optimisation problem. We demonstrate that our formulation as well as previous approaches highly depend on the initialisation of the training images $x$ to reconstruct. In particular, we show that a random initialisation of $x$ can lead to reconstructions that resemble valid training samples while not being part of the actual training dataset. Thus, our experiments on affine and one-hidden layer networks suggest that when reconstructing natural images, yet an adversary cannot identify whether reconstructed images have indeed been part of the set of training samples.
Operator learning regularization for macroscopic permeability prediction in dual-scale flow problem
Nov 30, 2024



Liquid composites moulding is an important manufacturing technology for fibre reinforced composites, due to its cost-effectiveness. Challenges lie in the optimisation of the process due to the lack of understanding of key characteristic of textile fabrics - permeability. The problem of computing the permeability coefficient can be modelled as the well-known Stokes-Brinkman equation, which introduces a heterogeneous parameter $\beta$ distinguishing macropore regions and fibre-bundle regions. In the present work, we train a Fourier neural operator to learn the nonlinear map from the heterogeneous coefficient $\beta$ to the velocity field $u$, and recover the corresponding macroscopic permeability $K$. This is a challenging inverse problem since both the input and output fields span several order of magnitudes, we introduce different regularization techniques for the loss function and perform a quantitative comparison between them.
Continuous Learned Primal Dual
May 03, 2024
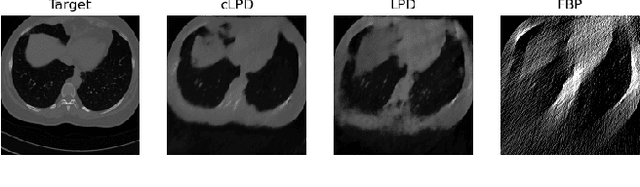
Neural ordinary differential equations (Neural ODEs) propose the idea that a sequence of layers in a neural network is just a discretisation of an ODE, and thus can instead be directly modelled by a parameterised ODE. This idea has had resounding success in the deep learning literature, with direct or indirect influence in many state of the art ideas, such as diffusion models or time dependant models. Recently, a continuous version of the U-net architecture has been proposed, showing increased performance over its discrete counterpart in many imaging applications and wrapped with theoretical guarantees around its performance and robustness. In this work, we explore the use of Neural ODEs for learned inverse problems, in particular with the well-known Learned Primal Dual algorithm, and apply it to computed tomography (CT) reconstruction.
Continuous U-Net: Faster, Greater and Noiseless
Feb 01, 2023



Image segmentation is a fundamental task in image analysis and clinical practice. The current state-of-the-art techniques are based on U-shape type encoder-decoder networks with skip connections, called U-Net. Despite the powerful performance reported by existing U-Net type networks, they suffer from several major limitations. Issues include the hard coding of the receptive field size, compromising the performance and computational cost, as well as the fact that they do not account for inherent noise in the data. They have problems associated with discrete layers, and do not offer any theoretical underpinning. In this work we introduce continuous U-Net, a novel family of networks for image segmentation. Firstly, continuous U-Net is a continuous deep neural network that introduces new dynamic blocks modelled by second order ordinary differential equations. Secondly, we provide theoretical guarantees for our network demonstrating faster convergence, higher robustness and less sensitivity to noise. Thirdly, we derive qualitative measures to tailor-made segmentation tasks. We demonstrate, through extensive numerical and visual results, that our model outperforms existing U-Net blocks for several medical image segmentation benchmarking datasets.
Multi-Modal Hypergraph Diffusion Network with Dual Prior for Alzheimer Classification
Apr 04, 2022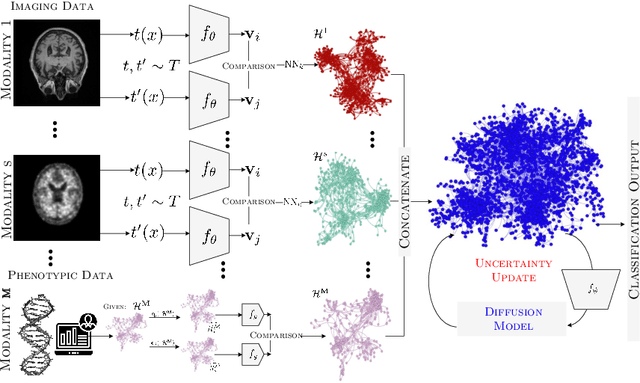
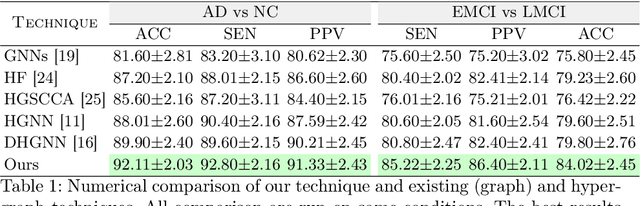
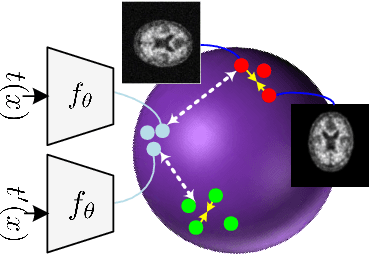
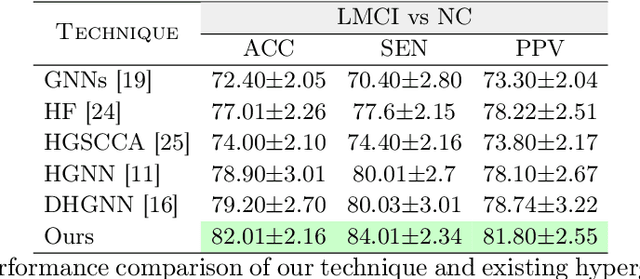
The automatic early diagnosis of prodromal stages of Alzheimer's disease is of great relevance for patient treatment to improve quality of life. We address this problem as a multi-modal classification task. Multi-modal data provides richer and complementary information. However, existing techniques only consider either lower order relations between the data and single/multi-modal imaging data. In this work, we introduce a novel semi-supervised hypergraph learning framework for Alzheimer's disease diagnosis. Our framework allows for higher-order relations among multi-modal imaging and non-imaging data whilst requiring a tiny labelled set. Firstly, we introduce a dual embedding strategy for constructing a robust hypergraph that preserves the data semantics. We achieve this by enforcing perturbation invariance at the image and graph levels using a contrastive based mechanism. Secondly, we present a dynamically adjusted hypergraph diffusion model, via a semi-explicit flow, to improve the predictive uncertainty. We demonstrate, through our experiments, that our framework is able to outperform current techniques for Alzheimer's disease diagnosis.
Depthwise Separable Convolutions Allow for Fast and Memory-Efficient Spectral Normalization
Feb 12, 2021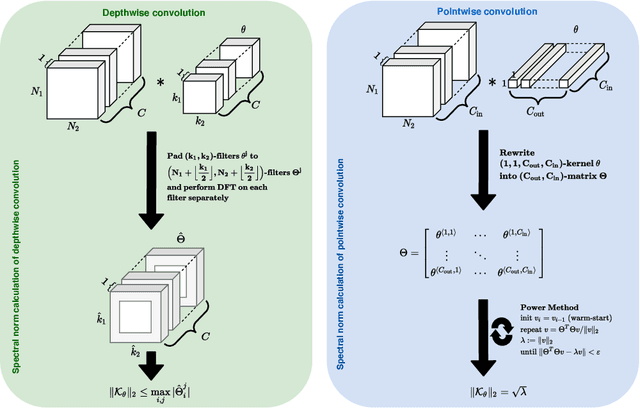
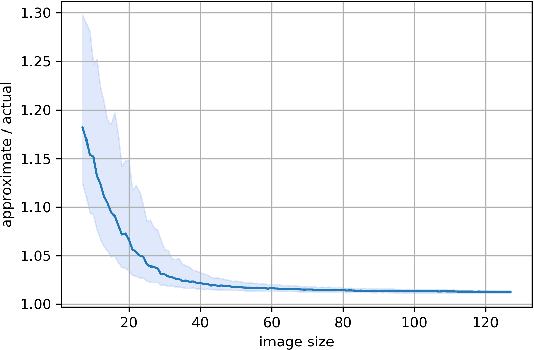

An increasing number of models require the control of the spectral norm of convolutional layers of a neural network. While there is an abundance of methods for estimating and enforcing upper bounds on those during training, they are typically costly in either memory or time. In this work, we introduce a very simple method for spectral normalization of depthwise separable convolutions, which introduces negligible computational and memory overhead. We demonstrate the effectiveness of our method on image classification tasks using standard architectures like MobileNetV2.
Exploiting the Logits: Joint Sign Language Recognition and Spell-Correction
Jul 01, 2020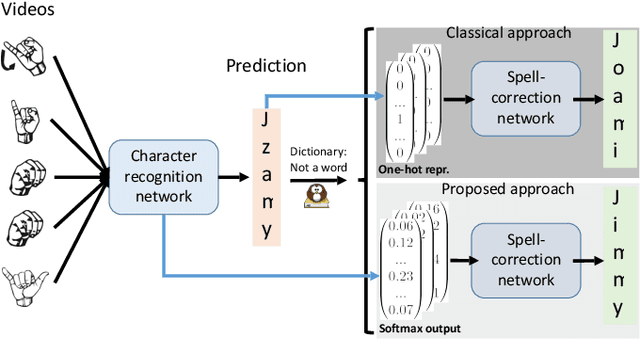
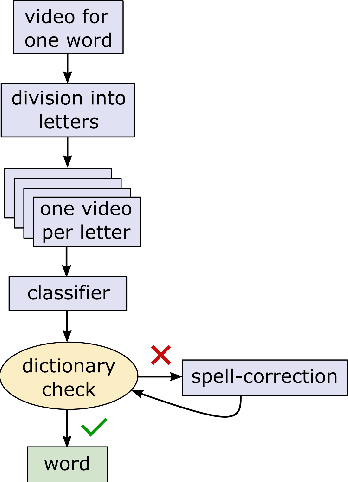


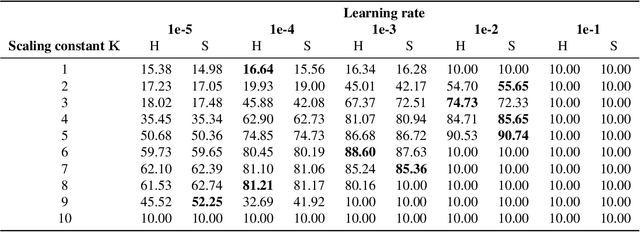
Machine learning techniques have excelled in the automatic semantic analysis of images, reaching human-level performances on challenging benchmarks. Yet, the semantic analysis of videos remains challenging due to the significantly higher dimensionality of the input data, respectively, the significantly higher need for annotated training examples. By studying the automatic recognition of German sign language videos, we demonstrate that on the relatively scarce training data of 2.800 videos, modern deep learning architectures for video analysis (such as ResNeXt) along with transfer learning on large gesture recognition tasks, can achieve about 75% character accuracy. Considering that this leaves us with a probability of under 25% that a 5 letter word is spelled correctly, spell-correction systems are crucial for producing readable outputs. The contribution of this paper is to propose a convolutional neural network for spell-correction that expects the softmax outputs of the character recognition network (instead of a misspelled word) as an input. We demonstrate that purely learning on softmax inputs in combination with scarce training data yields overfitting as the network learns the inputs by heart. In contrast, training the network on several variants of the logits of the classification output i.e. scaling by a constant factor, adding of random noise, mixing of softmax and hardmax inputs or purely training on hardmax inputs, leads to better generalization while benefitting from the significant information hidden in these outputs (that have 98% top-5 accuracy), yielding a readable text despite the comparably low character accuracy.