 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRAWDet-7: A Multi-Scenario Benchmark for Object Detection and Description on Quantized RAW Images
Feb 03, 2026Most vision models are trained on RGB images processed through ISP pipelines optimized for human perception, which can discard sensor-level information useful for machine reasoning. RAW images preserve unprocessed scene data, enabling models to leverage richer cues for both object detection and object description, capturing fine-grained details, spatial relationships, and contextual information often lost in processed images. To support research in this domain, we introduce RAWDet-7, a large-scale dataset of ~25k training and 7.6k test RAW images collected across diverse cameras, lighting conditions, and environments, densely annotated for seven object categories following MS-COCO and LVIS conventions. In addition, we provide object-level descriptions derived from the corresponding high-resolution sRGB images, facilitating the study of object-level information preservation under RAW image processing and low-bit quantization. The dataset allows evaluation under simulated 4-bit, 6-bit, and 8-bit quantization, reflecting realistic sensor constraints, and provides a benchmark for studying detection performance, description quality & detail, and generalization in low-bit RAW image processing. Dataset & code upon acceptance.
$γ$-Quant: Towards Learnable Quantization for Low-bit Pattern Recognition
Sep 26, 2025Most pattern recognition models are developed on pre-proce\-ssed data. In computer vision, for instance, RGB images processed through image signal processing (ISP) pipelines designed to cater to human perception are the most frequent input to image analysis networks. However, many modern vision tasks operate without a human in the loop, raising the question of whether such pre-processing is optimal for automated analysis. Similarly, human activity recognition (HAR) on body-worn sensor data commonly takes normalized floating-point data arising from a high-bit analog-to-digital converter (ADC) as an input, despite such an approach being highly inefficient in terms of data transmission, significantly affecting the battery life of wearable devices. In this work, we target low-bandwidth and energy-constrained settings where sensors are limited to low-bit-depth capture. We propose $\gamma$-Quant, i.e.~the task-specific learning of a non-linear quantization for pattern recognition. We exemplify our approach on raw-image object detection as well as HAR of wearable data, and demonstrate that raw data with a learnable quantization using as few as 4-bits can perform on par with the use of raw 12-bit data. All code to reproduce our experiments is publicly available via https://github.com/Mishalfatima/Gamma-Quant
Direct Image Classification from Fourier Ptychographic Microscopy Measurements without Reconstruction
May 08, 2025The computational imaging technique of Fourier Ptychographic Microscopy (FPM) enables high-resolution imaging with a wide field of view and can serve as an extremely valuable tool, e.g. in the classification of cells in medical applications. However, reconstructing a high-resolution image from tens or even hundreds of measurements is computationally expensive, particularly for a wide field of view. Therefore, in this paper, we investigate the idea of classifying the image content in the FPM measurements directly without performing a reconstruction step first. We show that Convolutional Neural Networks (CNN) can extract meaningful information from measurement sequences, significantly outperforming the classification on a single band-limited image (up to 12 %) while being significantly more efficient than a reconstruction of a high-resolution image. Furthermore, we demonstrate that a learned multiplexing of several raw measurements allows maintaining the classification accuracy while reducing the amount of data (and consequently also the acquisition time) significantly.
Training Data Reconstruction: Privacy due to Uncertainty?
Dec 11, 2024



Being able to reconstruct training data from the parameters of a neural network is a major privacy concern. Previous works have shown that reconstructing training data, under certain circumstances, is possible. In this work, we analyse such reconstructions empirically and propose a new formulation of the reconstruction as a solution to a bilevel optimisation problem. We demonstrate that our formulation as well as previous approaches highly depend on the initialisation of the training images $x$ to reconstruct. In particular, we show that a random initialisation of $x$ can lead to reconstructions that resemble valid training samples while not being part of the actual training dataset. Thus, our experiments on affine and one-hidden layer networks suggest that when reconstructing natural images, yet an adversary cannot identify whether reconstructed images have indeed been part of the set of training samples.
Text-guided Explorable Image Super-resolution
Mar 02, 2024



In this paper, we introduce the problem of zero-shot text-guided exploration of the solutions to open-domain image super-resolution. Our goal is to allow users to explore diverse, semantically accurate reconstructions that preserve data consistency with the low-resolution inputs for different large downsampling factors without explicitly training for these specific degradations. We propose two approaches for zero-shot text-guided super-resolution - i) modifying the generative process of text-to-image \textit{T2I} diffusion models to promote consistency with low-resolution inputs, and ii) incorporating language guidance into zero-shot diffusion-based restoration methods. We show that the proposed approaches result in diverse solutions that match the semantic meaning provided by the text prompt while preserving data consistency with the degraded inputs. We evaluate the proposed baselines for the task of extreme super-resolution and demonstrate advantages in terms of restoration quality, diversity, and explorability of solutions.
Robustness and Exploration of Variational and Machine Learning Approaches to Inverse Problems: An Overview
Feb 19, 2024



This paper attempts to provide an overview of current approaches for solving inverse problems in imaging using variational methods and machine learning. A special focus lies on point estimators and their robustness against adversarial perturbations. In this context results of numerical experiments for a one-dimensional toy problem are provided, showing the robustness of different approaches and empirically verifying theoretical guarantees. Another focus of this review is the exploration of the subspace of data consistent solutions through explicit guidance to satisfy specific semantic or textural properties.
Evaluating Adversarial Robustness of Low dose CT Recovery
Feb 18, 2024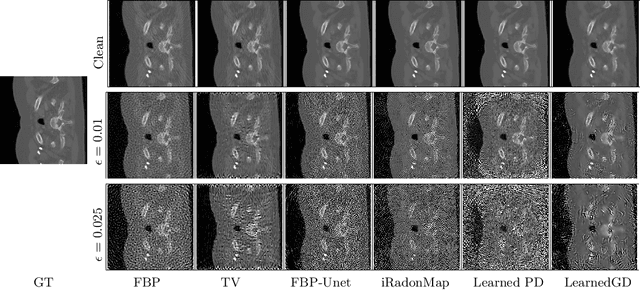

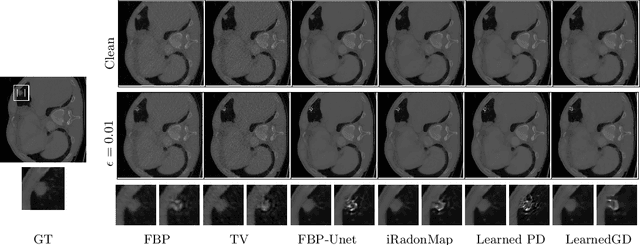

Low dose computed tomography (CT) acquisition using reduced radiation or sparse angle measurements is recommended to decrease the harmful effects of X-ray radiation. Recent works successfully apply deep networks to the problem of low dose CT recovery on bench-mark datasets. However, their robustness needs a thorough evaluation before use in clinical settings. In this work, we evaluate the robustness of different deep learning approaches and classical methods for CT recovery. We show that deep networks, including model-based networks encouraging data consistency, are more susceptible to untargeted attacks. Surprisingly, we observe that data consistency is not heavily affected even for these poor quality reconstructions, motivating the need for better regularization for the networks. We demonstrate the feasibility of universal attacks and study attack transferability across different methods. We analyze robustness to attacks causing localized changes in clinically relevant regions. Both classical approaches and deep networks are affected by such attacks leading to changes in the visual appearance of localized lesions, for extremely small perturbations. As the resulting reconstructions have high data consistency with the original measurements, these localized attacks can be used to explore the solution space of the CT recovery problem.
On the unreasonable vulnerability of transformers for image restoration -- and an easy fix
Jul 25, 2023Following their success in visual recognition tasks, Vision Transformers(ViTs) are being increasingly employed for image restoration. As a few recent works claim that ViTs for image classification also have better robustness properties, we investigate whether the improved adversarial robustness of ViTs extends to image restoration. We consider the recently proposed Restormer model, as well as NAFNet and the "Baseline network" which are both simplified versions of a Restormer. We use Projected Gradient Descent (PGD) and CosPGD, a recently proposed adversarial attack tailored to pixel-wise prediction tasks for our robustness evaluation. Our experiments are performed on real-world images from the GoPro dataset for image deblurring. Our analysis indicates that contrary to as advocated by ViTs in image classification works, these models are highly susceptible to adversarial attacks. We attempt to improve their robustness through adversarial training. While this yields a significant increase in robustness for Restormer, results on other networks are less promising. Interestingly, the design choices in NAFNet and Baselines, which were based on iid performance, and not on robust generalization, seem to be at odds with the model robustness. Thus, we investigate this further and find a fix.
LDEdit: Towards Generalized Text Guided Image Manipulation via Latent Diffusion Models
Oct 05, 2022

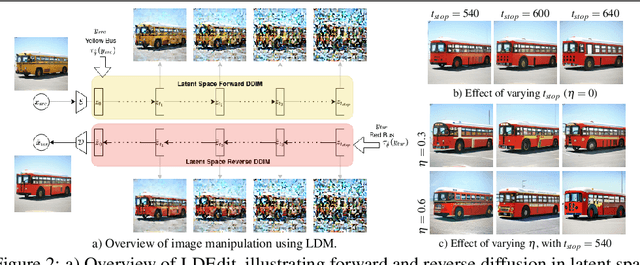
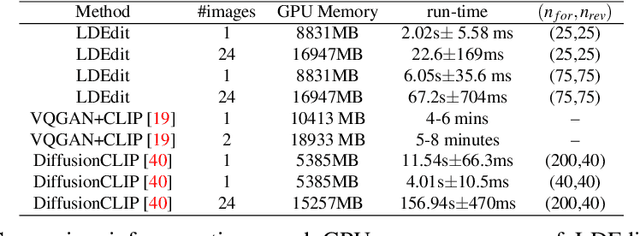
Research in vision-language models has seen rapid developments off-late, enabling natural language-based interfaces for image generation and manipulation. Many existing text guided manipulation techniques are restricted to specific classes of images, and often require fine-tuning to transfer to a different style or domain. Nevertheless, generic image manipulation using a single model with flexible text inputs is highly desirable. Recent work addresses this task by guiding generative models trained on the generic image datasets using pretrained vision-language encoders. While promising, this approach requires expensive optimization for each input. In this work, we propose an optimization-free method for the task of generic image manipulation from text prompts. Our approach exploits recent Latent Diffusion Models (LDM) for text to image generation to achieve zero-shot text guided manipulation. We employ a deterministic forward diffusion in a lower dimensional latent space, and the desired manipulation is achieved by simply providing the target text to condition the reverse diffusion process. We refer to our approach as LDEdit. We demonstrate the applicability of our method on semantic image manipulation and artistic style transfer. Our method can accomplish image manipulation on diverse domains and enables editing multiple attributes in a straightforward fashion. Extensive experiments demonstrate the benefit of our approach over competing baselines.
On Adversarial Robustness of Deep Image Deblurring
Oct 05, 2022
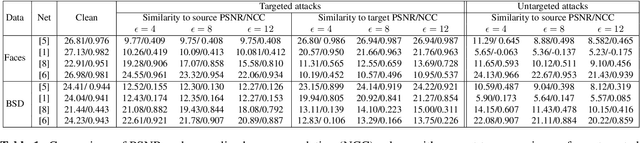


Recent approaches employ deep learning-based solutions for the recovery of a sharp image from its blurry observation. This paper introduces adversarial attacks against deep learning-based image deblurring methods and evaluates the robustness of these neural networks to untargeted and targeted attacks. We demonstrate that imperceptible distortion can significantly degrade the performance of state-of-the-art deblurring networks, even producing drastically different content in the output, indicating the strong need to include adversarially robust training not only in classification but also for image recovery.