 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText-guided Explorable Image Super-resolution
Mar 02, 2024



In this paper, we introduce the problem of zero-shot text-guided exploration of the solutions to open-domain image super-resolution. Our goal is to allow users to explore diverse, semantically accurate reconstructions that preserve data consistency with the low-resolution inputs for different large downsampling factors without explicitly training for these specific degradations. We propose two approaches for zero-shot text-guided super-resolution - i) modifying the generative process of text-to-image \textit{T2I} diffusion models to promote consistency with low-resolution inputs, and ii) incorporating language guidance into zero-shot diffusion-based restoration methods. We show that the proposed approaches result in diverse solutions that match the semantic meaning provided by the text prompt while preserving data consistency with the degraded inputs. We evaluate the proposed baselines for the task of extreme super-resolution and demonstrate advantages in terms of restoration quality, diversity, and explorability of solutions.
Evaluating Adversarial Robustness of Low dose CT Recovery
Feb 18, 2024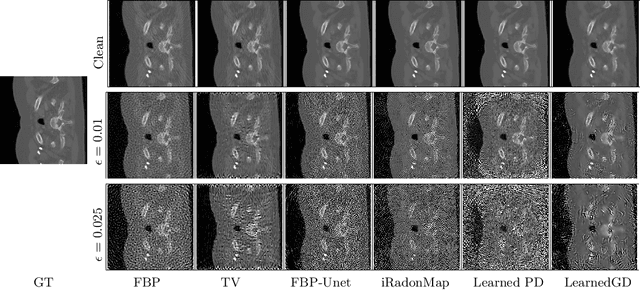

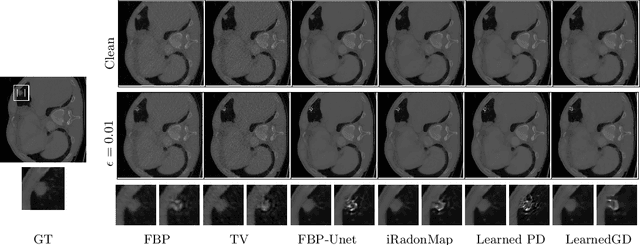

Low dose computed tomography (CT) acquisition using reduced radiation or sparse angle measurements is recommended to decrease the harmful effects of X-ray radiation. Recent works successfully apply deep networks to the problem of low dose CT recovery on bench-mark datasets. However, their robustness needs a thorough evaluation before use in clinical settings. In this work, we evaluate the robustness of different deep learning approaches and classical methods for CT recovery. We show that deep networks, including model-based networks encouraging data consistency, are more susceptible to untargeted attacks. Surprisingly, we observe that data consistency is not heavily affected even for these poor quality reconstructions, motivating the need for better regularization for the networks. We demonstrate the feasibility of universal attacks and study attack transferability across different methods. We analyze robustness to attacks causing localized changes in clinically relevant regions. Both classical approaches and deep networks are affected by such attacks leading to changes in the visual appearance of localized lesions, for extremely small perturbations. As the resulting reconstructions have high data consistency with the original measurements, these localized attacks can be used to explore the solution space of the CT recovery problem.
On the unreasonable vulnerability of transformers for image restoration -- and an easy fix
Jul 25, 2023Following their success in visual recognition tasks, Vision Transformers(ViTs) are being increasingly employed for image restoration. As a few recent works claim that ViTs for image classification also have better robustness properties, we investigate whether the improved adversarial robustness of ViTs extends to image restoration. We consider the recently proposed Restormer model, as well as NAFNet and the "Baseline network" which are both simplified versions of a Restormer. We use Projected Gradient Descent (PGD) and CosPGD, a recently proposed adversarial attack tailored to pixel-wise prediction tasks for our robustness evaluation. Our experiments are performed on real-world images from the GoPro dataset for image deblurring. Our analysis indicates that contrary to as advocated by ViTs in image classification works, these models are highly susceptible to adversarial attacks. We attempt to improve their robustness through adversarial training. While this yields a significant increase in robustness for Restormer, results on other networks are less promising. Interestingly, the design choices in NAFNet and Baselines, which were based on iid performance, and not on robust generalization, seem to be at odds with the model robustness. Thus, we investigate this further and find a fix.
LDEdit: Towards Generalized Text Guided Image Manipulation via Latent Diffusion Models
Oct 05, 2022

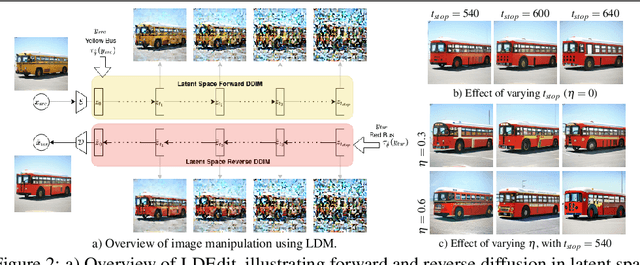
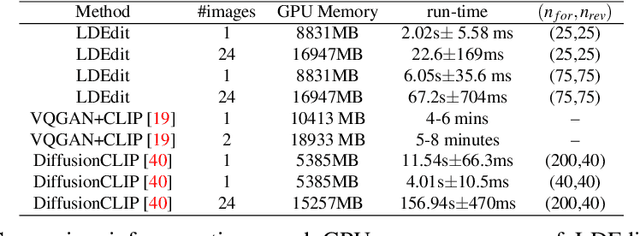
Research in vision-language models has seen rapid developments off-late, enabling natural language-based interfaces for image generation and manipulation. Many existing text guided manipulation techniques are restricted to specific classes of images, and often require fine-tuning to transfer to a different style or domain. Nevertheless, generic image manipulation using a single model with flexible text inputs is highly desirable. Recent work addresses this task by guiding generative models trained on the generic image datasets using pretrained vision-language encoders. While promising, this approach requires expensive optimization for each input. In this work, we propose an optimization-free method for the task of generic image manipulation from text prompts. Our approach exploits recent Latent Diffusion Models (LDM) for text to image generation to achieve zero-shot text guided manipulation. We employ a deterministic forward diffusion in a lower dimensional latent space, and the desired manipulation is achieved by simply providing the target text to condition the reverse diffusion process. We refer to our approach as LDEdit. We demonstrate the applicability of our method on semantic image manipulation and artistic style transfer. Our method can accomplish image manipulation on diverse domains and enables editing multiple attributes in a straightforward fashion. Extensive experiments demonstrate the benefit of our approach over competing baselines.
On Adversarial Robustness of Deep Image Deblurring
Oct 05, 2022
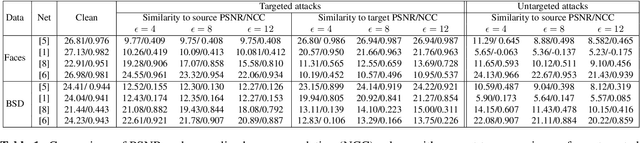


Recent approaches employ deep learning-based solutions for the recovery of a sharp image from its blurry observation. This paper introduces adversarial attacks against deep learning-based image deblurring methods and evaluates the robustness of these neural networks to untargeted and targeted attacks. We demonstrate that imperceptible distortion can significantly degrade the performance of state-of-the-art deblurring networks, even producing drastically different content in the output, indicating the strong need to include adversarially robust training not only in classification but also for image recovery.
Light Field Implicit Representation for Flexible Resolution Reconstruction
Nov 30, 2021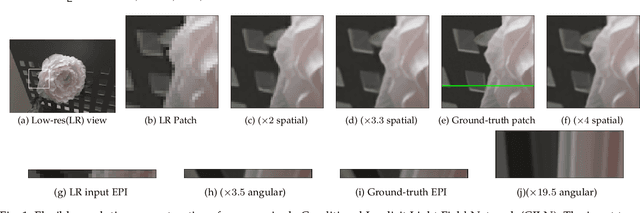
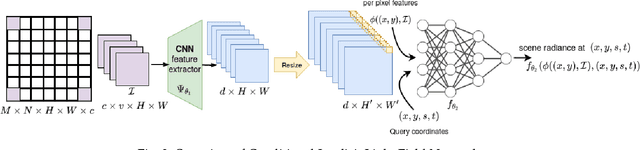
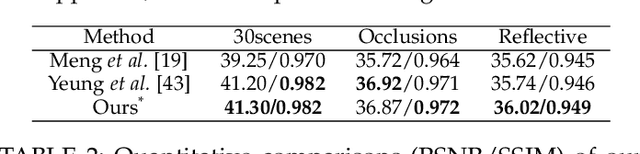
Inspired by the recent advances in implicitly representing signals with trained neural networks, we aim to learn a continuous representation for narrow-baseline 4D light fields. We propose an implicit representation model for 4D light fields which is conditioned on a sparse set of input views. Our model is trained to output the light field values for a continuous range of query spatio-angular coordinates. Given a sparse set of input views, our scheme can super-resolve the input in both spatial and angular domains by flexible factors. consists of a feature extractor and a decoder which are trained on a dataset of light field patches. The feature extractor captures per-pixel features from the input views. These features can be resized to a desired spatial resolution and fed to the decoder along with the query coordinates. This formulation enables us to reconstruct light field views at any desired spatial and angular resolution. Additionally, our network can handle scenarios in which input views are either of low-resolution or with missing pixels. Experiments show that our method achieves state-of-the-art performance for the task of view synthesis while being computationally fast.
Generative Models for Generic Light Field Reconstruction
May 13, 2020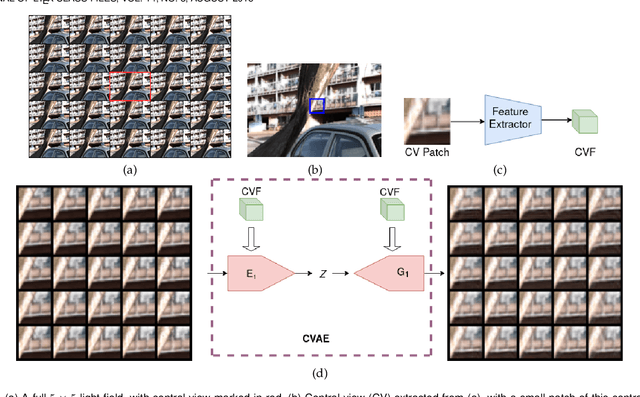
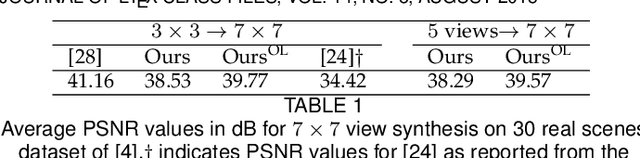
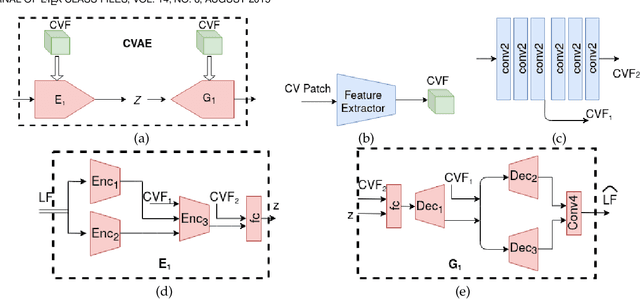
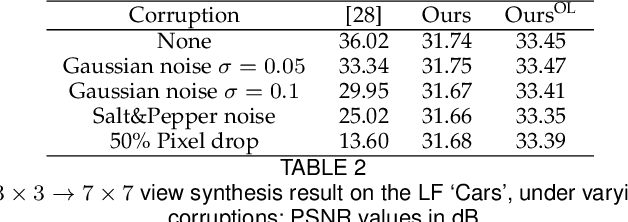
Recently deep generative models have achieved impressive progress in modeling the distribution of training data. In this work, we present for the first time generative models for 4D light field patches using variational autoencoders to capture the data distribution of light field patches. We develop two generative models, a model conditioned on the central view of the light field and an unconditional model. We incorporate our generative priors in an energy minimization framework to address diverse light field reconstruction tasks. While pure learning-based approaches do achieve excellent results on each instance of such a problem, their applicability is limited to the specific observation model they have been trained on. On the contrary, our trained light field generative models can be incorporated as a prior into any model-based optimization approach and therefore extend to diverse reconstruction tasks including light field view synthesis, spatial-angular super resolution and reconstruction from coded projections. Our proposed method demonstrates good reconstruction, with performance approaching end-to-end trained networks, while outperforming traditional model-based approaches on both synthetic and real scenes. Furthermore, we show that our approach enables reliable light field recovery despite distortions in the input.
A `Little Bit' Too Much? High Speed Imaging from Sparse Photon Counts
Nov 06, 2018



Recent advances in photographic sensing technologies have made it possible to achieve light detection in terms of a single photon. Photon counting sensors are being increasingly used in many diverse applications. We address the problem of jointly recovering spatial and temporal scene radiance from very few photon counts. Our ConvNet-based scheme effectively combines spatial and temporal information present in measurements to reduce noise. We demonstrate that using our method one can acquire videos at a high frame rate and still achieve good quality signal-to-noise ratio. Experiments show that the proposed scheme performs quite well in different challenging scenarios while the existing denoising schemes are unable to handle them.
Motion Deblurring in the Wild
Aug 29, 2017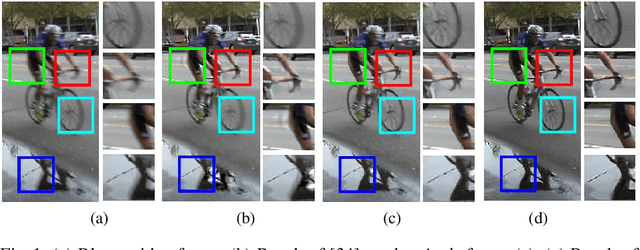



The task of image deblurring is a very ill-posed problem as both the image and the blur are unknown. Moreover, when pictures are taken in the wild, this task becomes even more challenging due to the blur varying spatially and the occlusions between the object. Due to the complexity of the general image model we propose a novel convolutional network architecture which directly generates the sharp image.This network is built in three stages, and exploits the benefits of pyramid schemes often used in blind deconvolution. One of the main difficulties in training such a network is to design a suitable dataset. While useful data can be obtained by synthetically blurring a collection of images, more realistic data must be collected in the wild. To obtain such data we use a high frame rate video camera and keep one frame as the sharp image and frame average as the corresponding blurred image. We show that this realistic dataset is key in achieving state-of-the-art performance and dealing with occlusions.
Reflection Separation and Deblurring of Plenoptic Images
Aug 22, 2017



In this paper, we address the problem of reflection removal and deblurring from a single image captured by a plenoptic camera. We develop a two-stage approach to recover the scene depth and high resolution textures of the reflected and transmitted layers. For depth estimation in the presence of reflections, we train a classifier through convolutional neural networks. For recovering high resolution textures, we assume that the scene is composed of planar regions and perform the reconstruction of each layer by using an explicit form of the plenoptic camera point spread function. The proposed framework also recovers the sharp scene texture with different motion blurs applied to each layer. We demonstrate our method on challenging real and synthetic images.