 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifferentiable Sensor Layouts for End-to-End Learning of Task-Specific Camera Parameters
Apr 28, 2023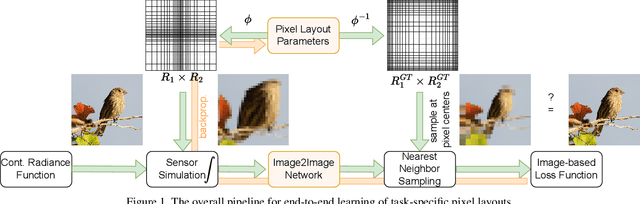
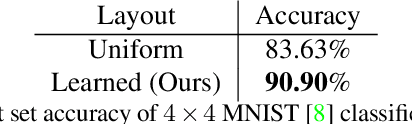
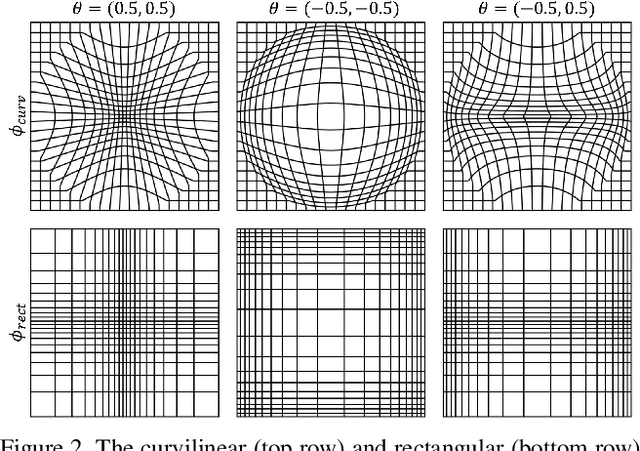
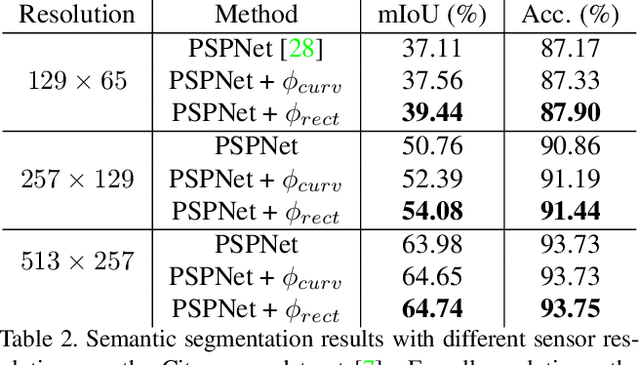
The success of deep learning is frequently described as the ability to train all parameters of a network on a specific application in an end-to-end fashion. Yet, several design choices on the camera level, including the pixel layout of the sensor, are considered as pre-defined and fixed, and high resolution, regular pixel layouts are considered to be the most generic ones in computer vision and graphics, treating all regions of an image as equally important. While several works have considered non-uniform, \eg, hexagonal or foveated, pixel layouts in hardware and image processing, the layout has not been integrated into the end-to-end learning paradigm so far. In this work, we present the first truly end-to-end trained imaging pipeline that optimizes the size and distribution of pixels on the imaging sensor jointly with the parameters of a given neural network on a specific task. We derive an analytic, differentiable approach for the sensor layout parameterization that allows for task-specific, local varying pixel resolutions. We present two pixel layout parameterization functions: rectangular and curvilinear grid shapes that retain a regular topology. We provide a drop-in module that approximates sensor simulation given existing high-resolution images to directly connect our method with existing deep learning models. We show that network predictions benefit from learnable pixel layouts for two different downstream tasks, classification and semantic segmentation.
Neural Volume Super-Resolution
Dec 09, 2022Neural volumetric representations have become a widely adopted model for radiance fields in 3D scenes. These representations are fully implicit or hybrid function approximators of the instantaneous volumetric radiance in a scene, which are typically learned from multi-view captures of the scene. We investigate the new task of neural volume super-resolution - rendering high-resolution views corresponding to a scene captured at low resolution. To this end, we propose a neural super-resolution network that operates directly on the volumetric representation of the scene. This approach allows us to exploit an advantage of operating in the volumetric domain, namely the ability to guarantee consistent super-resolution across different viewing directions. To realize our method, we devise a novel 3D representation that hinges on multiple 2D feature planes. This allows us to super-resolve the 3D scene representation by applying 2D convolutional networks on the 2D feature planes. We validate the proposed method's capability of super-resolving multi-view consistent views both quantitatively and qualitatively on a diverse set of unseen 3D scenes, demonstrating a significant advantage over existing approaches.
Light Field Implicit Representation for Flexible Resolution Reconstruction
Nov 30, 2021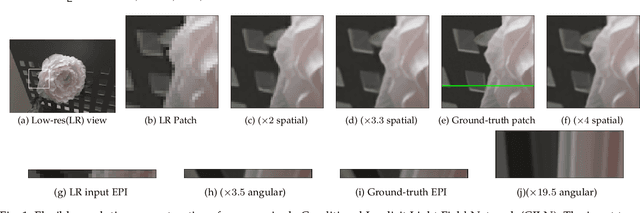
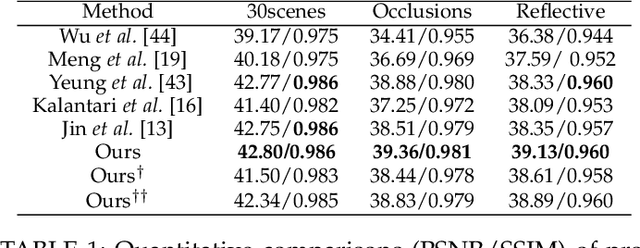
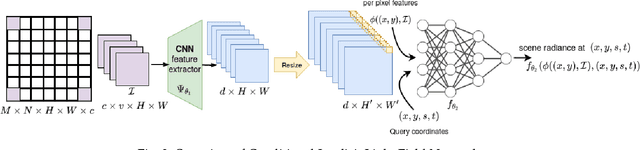
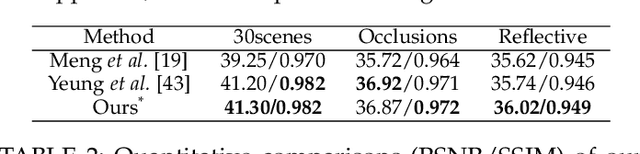
Inspired by the recent advances in implicitly representing signals with trained neural networks, we aim to learn a continuous representation for narrow-baseline 4D light fields. We propose an implicit representation model for 4D light fields which is conditioned on a sparse set of input views. Our model is trained to output the light field values for a continuous range of query spatio-angular coordinates. Given a sparse set of input views, our scheme can super-resolve the input in both spatial and angular domains by flexible factors. consists of a feature extractor and a decoder which are trained on a dataset of light field patches. The feature extractor captures per-pixel features from the input views. These features can be resized to a desired spatial resolution and fed to the decoder along with the query coordinates. This formulation enables us to reconstruct light field views at any desired spatial and angular resolution. Additionally, our network can handle scenarios in which input views are either of low-resolution or with missing pixels. Experiments show that our method achieves state-of-the-art performance for the task of view synthesis while being computationally fast.
Generative Models for Generic Light Field Reconstruction
May 13, 2020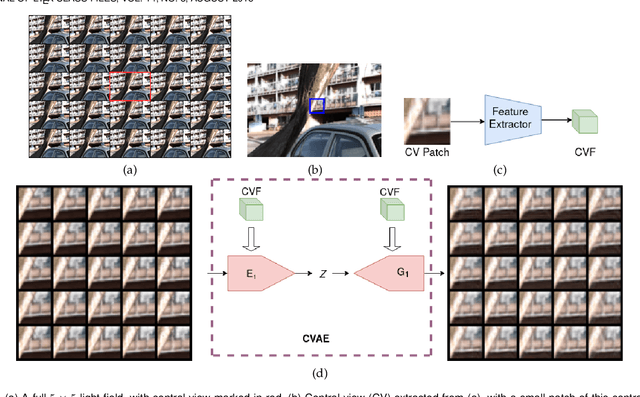
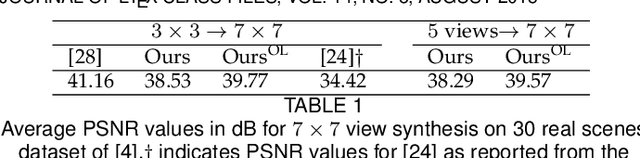
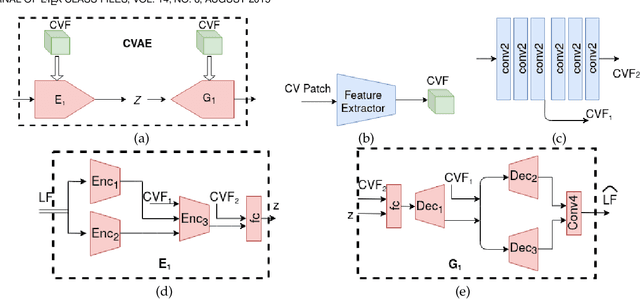
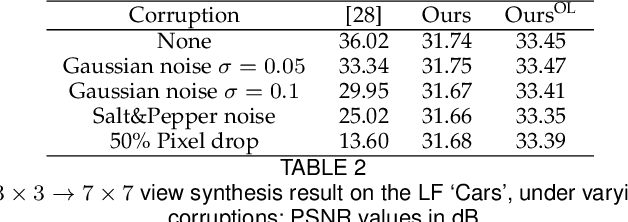
Recently deep generative models have achieved impressive progress in modeling the distribution of training data. In this work, we present for the first time generative models for 4D light field patches using variational autoencoders to capture the data distribution of light field patches. We develop two generative models, a model conditioned on the central view of the light field and an unconditional model. We incorporate our generative priors in an energy minimization framework to address diverse light field reconstruction tasks. While pure learning-based approaches do achieve excellent results on each instance of such a problem, their applicability is limited to the specific observation model they have been trained on. On the contrary, our trained light field generative models can be incorporated as a prior into any model-based optimization approach and therefore extend to diverse reconstruction tasks including light field view synthesis, spatial-angular super resolution and reconstruction from coded projections. Our proposed method demonstrates good reconstruction, with performance approaching end-to-end trained networks, while outperforming traditional model-based approaches on both synthetic and real scenes. Furthermore, we show that our approach enables reliable light field recovery despite distortions in the input.
Training Auto-encoder-based Optimizers for Terahertz Image Reconstruction
Jul 02, 2019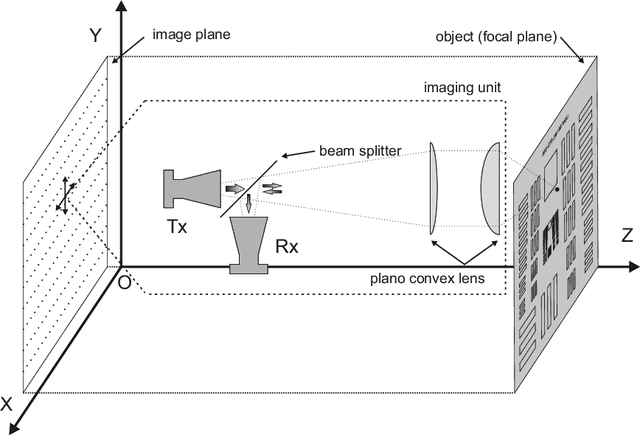
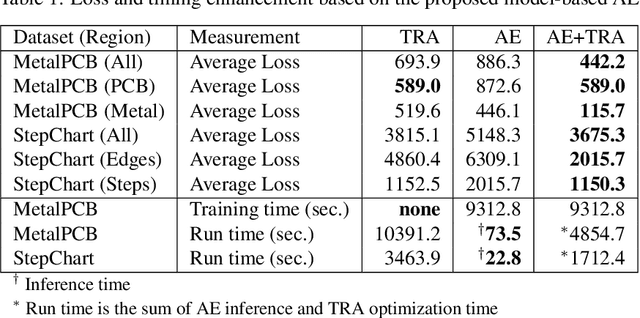
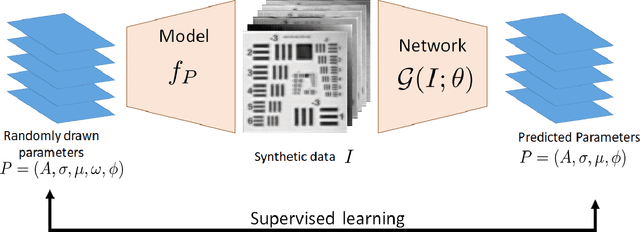
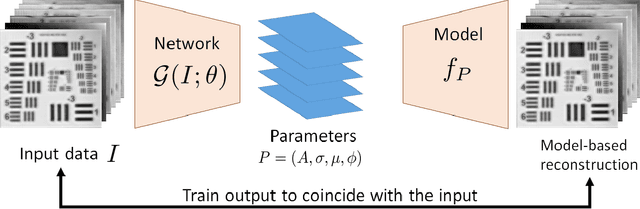
Terahertz (THz) sensing is a promising imaging technology for a wide variety of different applications. Extracting the interpretable and physically meaningful parameters for such applications, however, requires solving an inverse problem in which a model function determined by these parameters needs to be fitted to the measured data. Since the underlying optimization problem is nonconvex and very costly to solve, we propose learning the prediction of suitable parameters from the measured data directly. More precisely, we develop a model-based autoencoder in which the encoder network predicts suitable parameters and the decoder is fixed to a physically meaningful model function, such that we can train the encoding network in an unsupervised way. We illustrate numerically that the resulting network is more than 140 times faster than classical optimization techniques while making predictions with only slightly higher objective values. Using such predictions as starting points of local optimization techniques allows us to converge to better local minima about twice as fast as optimization without the network-based initialization.
Supervised Deep Kriging for Single-Image Super-Resolution
Dec 10, 2018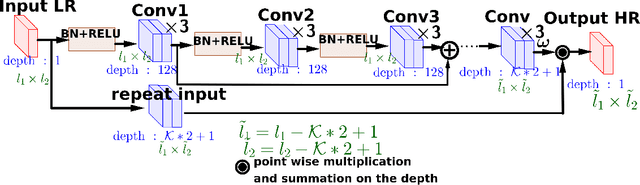
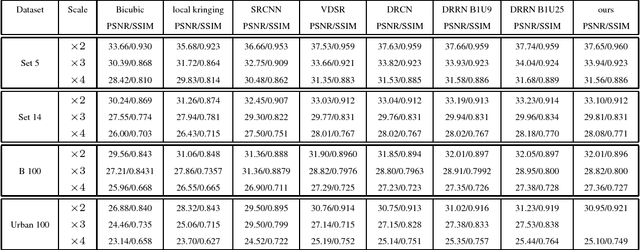
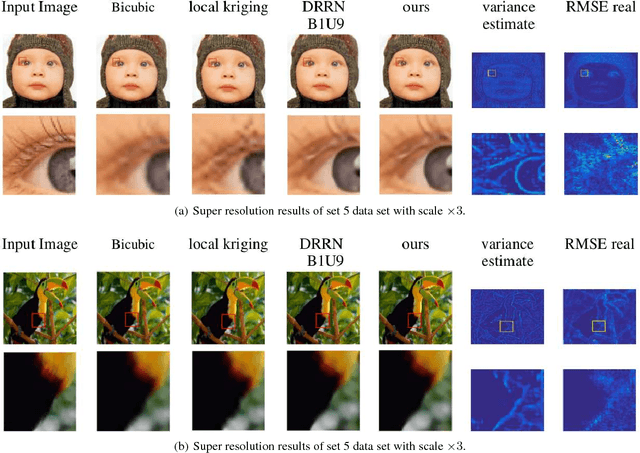
We propose a novel single-image super-resolution approach based on the geostatistical method of kriging. Kriging is a zero-bias minimum-variance estimator that performs spatial interpolation based on a weighted average of known observations. Rather than solving for the kriging weights via the traditional method of inverting covariance matrices, we propose a supervised form in which we learn a deep network to generate said weights. We combine the kriging weight generation and kriging process into a joint network that can be learned end-to-end. Our network achieves competitive super-resolution results as other state-of-the-art methods. In addition, since the super-resolution process follows a known statistical framework, we are able to estimate bias and variance, something which is rarely possible for other deep networks.
A `Little Bit' Too Much? High Speed Imaging from Sparse Photon Counts
Nov 06, 2018



Recent advances in photographic sensing technologies have made it possible to achieve light detection in terms of a single photon. Photon counting sensors are being increasingly used in many diverse applications. We address the problem of jointly recovering spatial and temporal scene radiance from very few photon counts. Our ConvNet-based scheme effectively combines spatial and temporal information present in measurements to reduce noise. We demonstrate that using our method one can acquire videos at a high frame rate and still achieve good quality signal-to-noise ratio. Experiments show that the proposed scheme performs quite well in different challenging scenarios while the existing denoising schemes are unable to handle them.
Residuum-Condition Diagram and Reduction of Over-Complete Endmember-Sets
Sep 26, 2018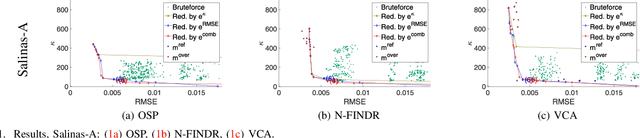
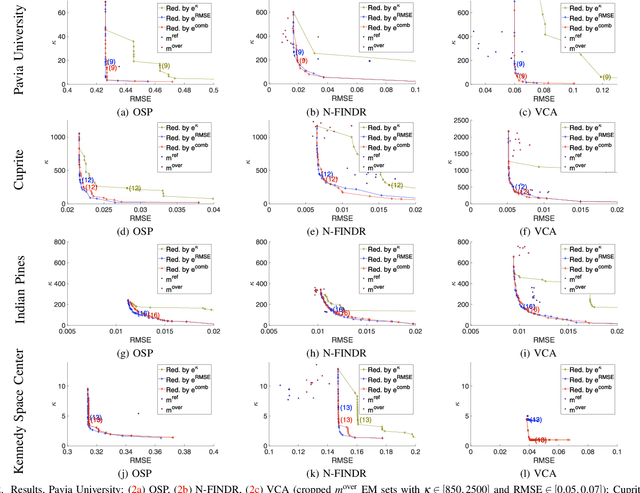
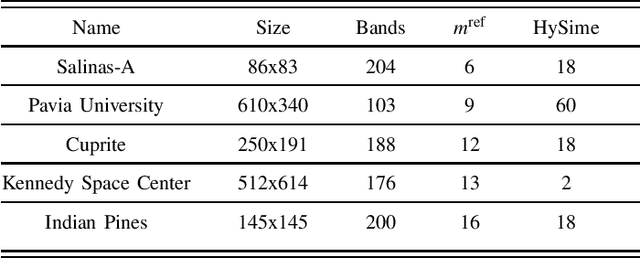
Extracting reference spectra, or endmembers (EMs) from a given multi- or hyperspectral image, as well as estimating the size of the EM set, plays an important role in multispectral image processing. In this paper, we present condition-residuum-diagrams. By plotting the residuum resulting from the unmixing and reconstruction and the condition number of various EM sets, the resulting diagram provides insight into the behavior of the spectral unmixing under a varying amount of endmembers (EMs). Furthermore, we utilize condition-residuum-diagrams to realize an EM reduction algorithm that starts with an initially extracted, over-complete EM set. An over-complete EM set commonly exhibits a good unmixing result, i.e. a lower reconstruction residuum, but due to its partial redundancy, the unmixing gets numerically unstable, i.e. the unmixed abundances values are less reliable. Our greedy reduction scheme improves the EM set by reducing the condition number, i.e. enhancing the set's stability, while keeping the reconstruction error as low as possible. The resulting set sequence gives hint to the optimal EM set and its size. We demonstrate the benefit of our condition-residuum-diagram and reduction scheme on well-studied datasets with known reference EM set sizes for several well-known EE algorithms.
Preoperative Volume Determination for Pituitary Adenoma
Feb 05, 2016The most common sellar lesion is the pituitary adenoma, and sellar tumors are approximately 10-15% of all intracranial neoplasms. Manual slice-by-slice segmentation takes quite some time that can be reduced by using the appropriate algorithms. In this contribution, we present a segmentation method for pituitary adenoma. The method is based on an algorithm that we have applied recently to segmenting glioblastoma multiforme. A modification of this scheme is used for adenoma segmentation that is much harder to perform, due to lack of contrast-enhanced boundaries. In our experimental evaluation, neurosurgeons performed manual slice-by-slice segmentation of ten magnetic resonance imaging (MRI) cases. The segmentations were compared to the segmentation results of the proposed method using the Dice Similarity Coefficient (DSC). The average DSC for all datasets was 75.92% +/- 7.24%. A manual segmentation took about four minutes and our algorithm required about one second.
Kinect Range Sensing: Structured-Light versus Time-of-Flight Kinect
May 20, 2015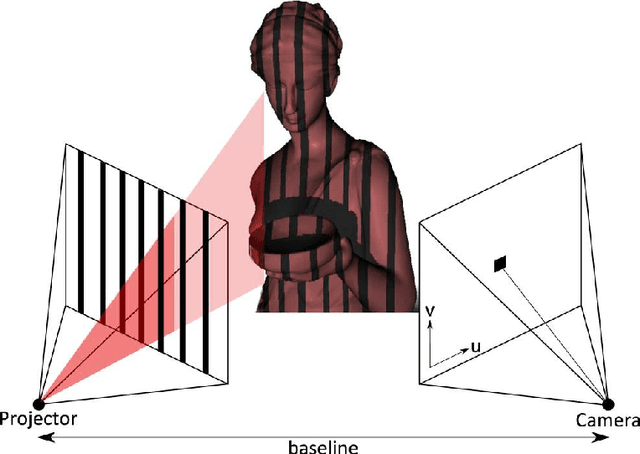



Recently, the new Kinect One has been issued by Microsoft, providing the next generation of real-time range sensing devices based on the Time-of-Flight (ToF) principle. As the first Kinect version was using a structured light approach, one would expect various differences in the characteristics of the range data delivered by both devices. This paper presents a detailed and in-depth comparison between both devices. In order to conduct the comparison, we propose a framework of seven different experimental setups, which is a generic basis for evaluating range cameras such as Kinect. The experiments have been designed with the goal to capture individual effects of the Kinect devices as isolatedly as possible and in a way, that they can also be adopted, in order to apply them to any other range sensing device. The overall goal of this paper is to provide a solid insight into the pros and cons of either device. Thus, scientists that are interested in using Kinect range sensing cameras in their specific application scenario can directly assess the expected, specific benefits and potential problem of either device.