 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Modal Binary Attention: An Energy-Efficient Fusion Framework for Audio-Visual Learning
Jan 31, 2026Effective multimodal fusion requires mechanisms that can capture complex cross-modal dependencies while remaining computationally scalable for real-world deployment. Existing audio-visual fusion approaches face a fundamental trade-off: attention-based methods effectively model cross-modal relationships but incur quadratic computational complexity that prevents hierarchical, multi-scale architectures, while efficient fusion strategies rely on simplistic concatenation that fails to extract complementary cross-modal information. We introduce CMQKA, a novel cross-modal fusion mechanism that achieves linear O(N) complexity through efficient binary operations, enabling scalable hierarchical fusion previously infeasible with conventional attention. CMQKA employs bidirectional cross-modal Query-Key attention to extract complementary spatiotemporal features and uses learnable residual fusion to preserve modality-specific characteristics while enriching representations with cross-modal information. Building upon CMQKA, we present SNNergy, an energy-efficient multimodal fusion framework with a hierarchical architecture that processes inputs through progressively decreasing spatial resolutions and increasing semantic abstraction. This multi-scale fusion capability allows the framework to capture both local patterns and global context across modalities. Implemented with event-driven binary spike operations, SNNergy achieves remarkable energy efficiency while maintaining fusion effectiveness and establishing new state-of-the-art results on challenging audio-visual benchmarks, including CREMA-D, AVE, and UrbanSound8K-AV, significantly outperforming existing multimodal fusion baselines. Our framework advances multimodal fusion by introducing a scalable fusion mechanism that enables hierarchical cross-modal integration with practical energy efficiency for real-world audio-visual intelligence systems.
Differentiable Sensor Layouts for End-to-End Learning of Task-Specific Camera Parameters
Apr 28, 2023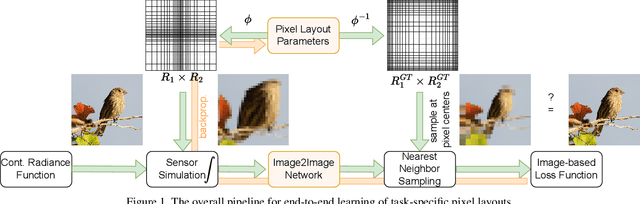
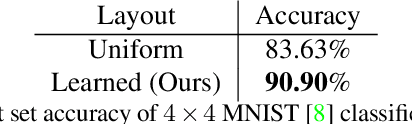
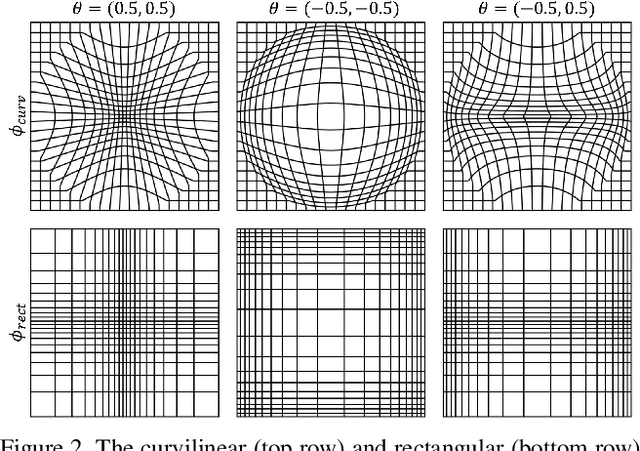
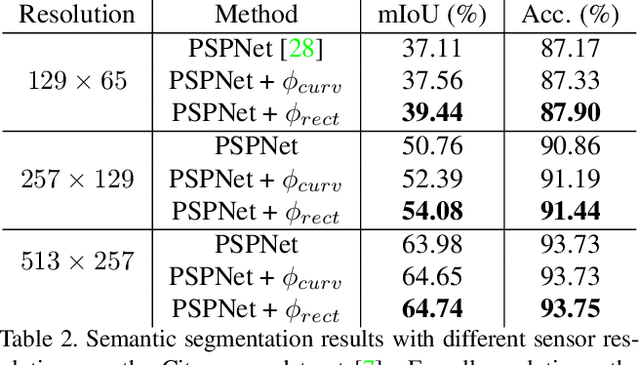
The success of deep learning is frequently described as the ability to train all parameters of a network on a specific application in an end-to-end fashion. Yet, several design choices on the camera level, including the pixel layout of the sensor, are considered as pre-defined and fixed, and high resolution, regular pixel layouts are considered to be the most generic ones in computer vision and graphics, treating all regions of an image as equally important. While several works have considered non-uniform, \eg, hexagonal or foveated, pixel layouts in hardware and image processing, the layout has not been integrated into the end-to-end learning paradigm so far. In this work, we present the first truly end-to-end trained imaging pipeline that optimizes the size and distribution of pixels on the imaging sensor jointly with the parameters of a given neural network on a specific task. We derive an analytic, differentiable approach for the sensor layout parameterization that allows for task-specific, local varying pixel resolutions. We present two pixel layout parameterization functions: rectangular and curvilinear grid shapes that retain a regular topology. We provide a drop-in module that approximates sensor simulation given existing high-resolution images to directly connect our method with existing deep learning models. We show that network predictions benefit from learnable pixel layouts for two different downstream tasks, classification and semantic segmentation.
Cross-Country Skiing Gears Classification using Deep Learning
Jun 27, 2017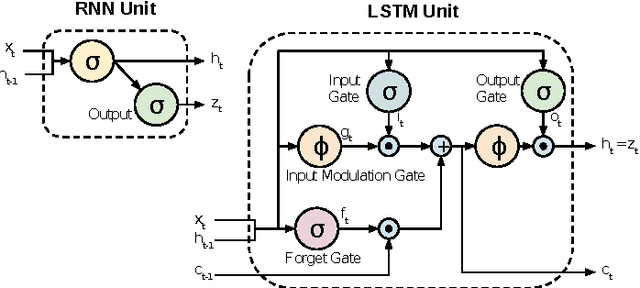
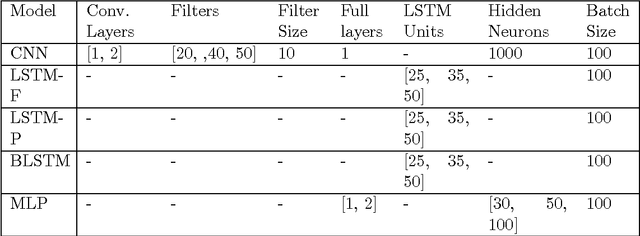
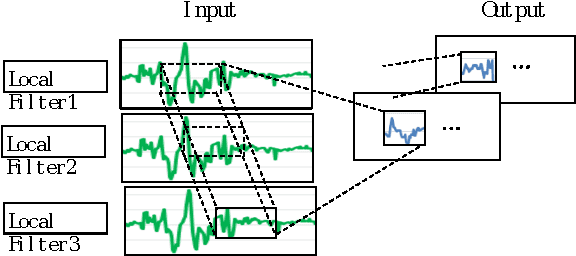
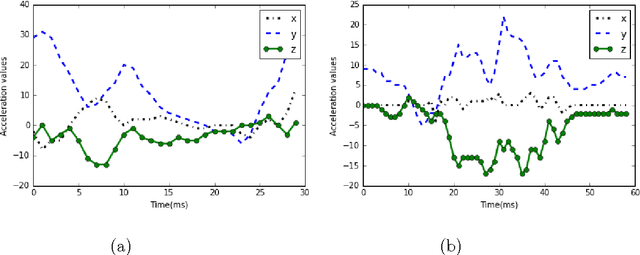
Human Activity Recognition has witnessed a significant progress in the last decade. Although a great deal of work in this field goes in recognizing normal human activities, few studies focused on identifying motion in sports. Recognizing human movements in different sports has high impact on understanding the different styles of humans in the play and on improving their performance. As deep learning models proved to have good results in many classification problems, this paper will utilize deep learning to classify cross-country skiing movements, known as gears, collected using a 3D accelerometer. It will also provide a comparison between different deep learning models such as convolutional and recurrent neural networks versus standard multi-layer perceptron. Results show that deep learning is more effective and has the highest classification accuracy.