 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifferentiable Sensor Layouts for End-to-End Learning of Task-Specific Camera Parameters
Apr 28, 2023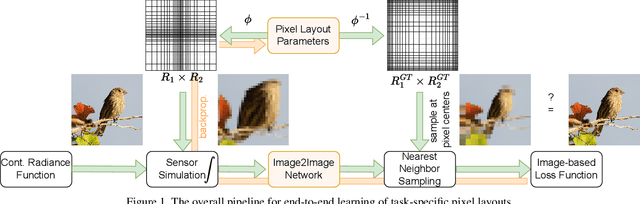
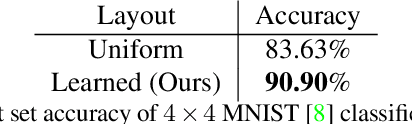
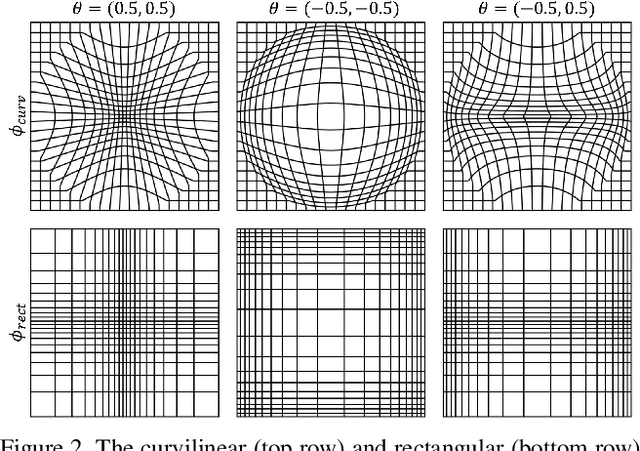
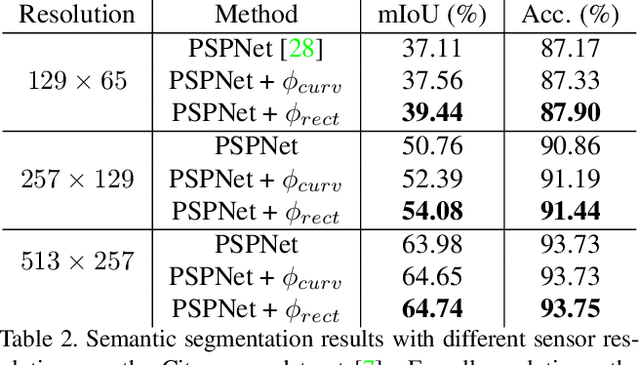
The success of deep learning is frequently described as the ability to train all parameters of a network on a specific application in an end-to-end fashion. Yet, several design choices on the camera level, including the pixel layout of the sensor, are considered as pre-defined and fixed, and high resolution, regular pixel layouts are considered to be the most generic ones in computer vision and graphics, treating all regions of an image as equally important. While several works have considered non-uniform, \eg, hexagonal or foveated, pixel layouts in hardware and image processing, the layout has not been integrated into the end-to-end learning paradigm so far. In this work, we present the first truly end-to-end trained imaging pipeline that optimizes the size and distribution of pixels on the imaging sensor jointly with the parameters of a given neural network on a specific task. We derive an analytic, differentiable approach for the sensor layout parameterization that allows for task-specific, local varying pixel resolutions. We present two pixel layout parameterization functions: rectangular and curvilinear grid shapes that retain a regular topology. We provide a drop-in module that approximates sensor simulation given existing high-resolution images to directly connect our method with existing deep learning models. We show that network predictions benefit from learnable pixel layouts for two different downstream tasks, classification and semantic segmentation.
Neural Volume Super-Resolution
Dec 09, 2022Neural volumetric representations have become a widely adopted model for radiance fields in 3D scenes. These representations are fully implicit or hybrid function approximators of the instantaneous volumetric radiance in a scene, which are typically learned from multi-view captures of the scene. We investigate the new task of neural volume super-resolution - rendering high-resolution views corresponding to a scene captured at low resolution. To this end, we propose a neural super-resolution network that operates directly on the volumetric representation of the scene. This approach allows us to exploit an advantage of operating in the volumetric domain, namely the ability to guarantee consistent super-resolution across different viewing directions. To realize our method, we devise a novel 3D representation that hinges on multiple 2D feature planes. This allows us to super-resolve the 3D scene representation by applying 2D convolutional networks on the 2D feature planes. We validate the proposed method's capability of super-resolving multi-view consistent views both quantitatively and qualitatively on a diverse set of unseen 3D scenes, demonstrating a significant advantage over existing approaches.
Light Field Implicit Representation for Flexible Resolution Reconstruction
Nov 30, 2021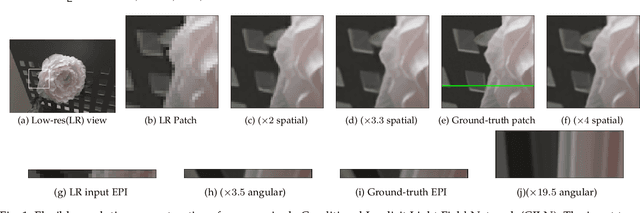
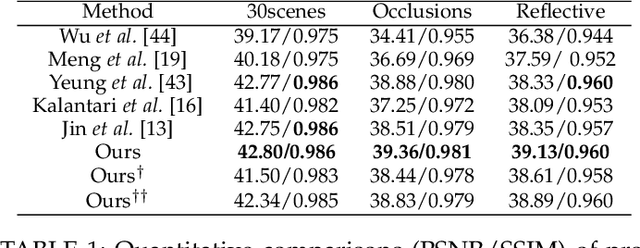
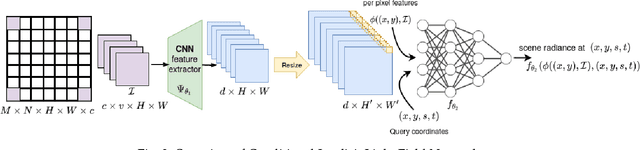
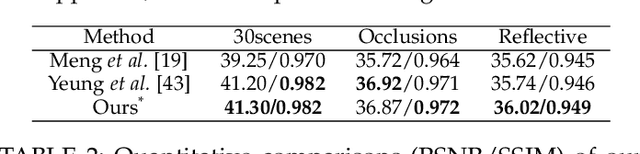
Inspired by the recent advances in implicitly representing signals with trained neural networks, we aim to learn a continuous representation for narrow-baseline 4D light fields. We propose an implicit representation model for 4D light fields which is conditioned on a sparse set of input views. Our model is trained to output the light field values for a continuous range of query spatio-angular coordinates. Given a sparse set of input views, our scheme can super-resolve the input in both spatial and angular domains by flexible factors. consists of a feature extractor and a decoder which are trained on a dataset of light field patches. The feature extractor captures per-pixel features from the input views. These features can be resized to a desired spatial resolution and fed to the decoder along with the query coordinates. This formulation enables us to reconstruct light field views at any desired spatial and angular resolution. Additionally, our network can handle scenarios in which input views are either of low-resolution or with missing pixels. Experiments show that our method achieves state-of-the-art performance for the task of view synthesis while being computationally fast.