 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Class-wise Robustness Analysis
Nov 29, 2024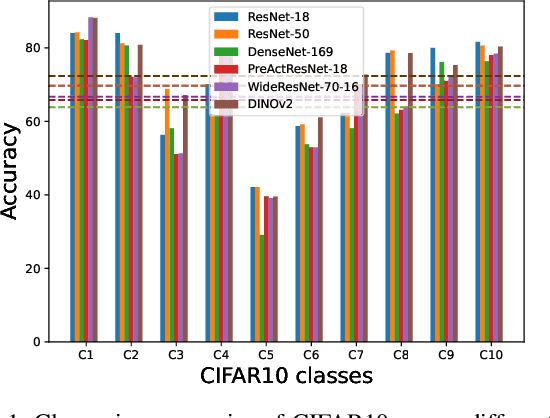
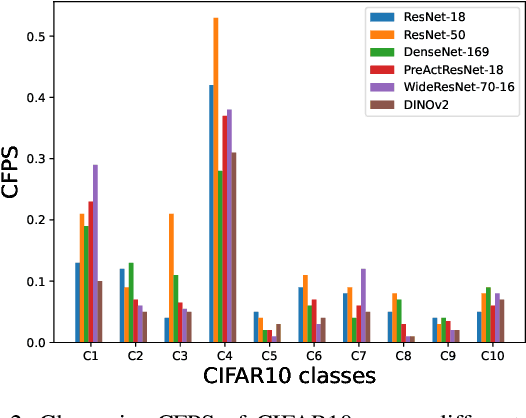
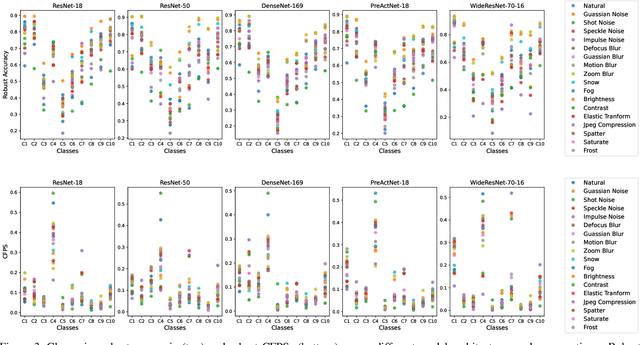
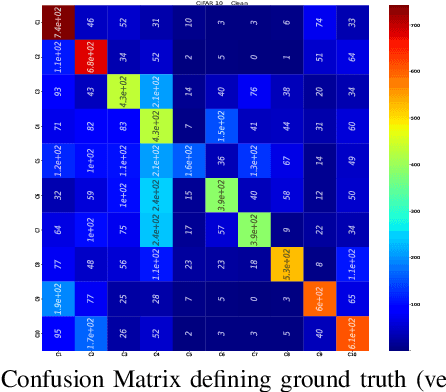
While being very successful in solving many downstream tasks, the application of deep neural networks is limited in real-life scenarios because of their susceptibility to domain shifts such as common corruptions, and adversarial attacks. The existence of adversarial examples and data corruption significantly reduces the performance of deep classification models. Researchers have made strides in developing robust neural architectures to bolster decisions of deep classifiers. However, most of these works rely on effective adversarial training methods, and predominantly focus on overall model robustness, disregarding class-wise differences in robustness, which are critical. Exploiting weakly robust classes is a potential avenue for attackers to fool the image recognition models. Therefore, this study investigates class-to-class biases across adversarially trained robust classification models to understand their latent space structures and analyze their strong and weak class-wise properties. We further assess the robustness of classes against common corruptions and adversarial attacks, recognizing that class vulnerability extends beyond the number of correct classifications for a specific class. We find that the number of false positives of classes as specific target classes significantly impacts their vulnerability to attacks. Through our analysis on the Class False Positive Score, we assess a fair evaluation of how susceptible each class is to misclassification.
Beware of Aliases -- Signal Preservation is Crucial for Robust Image Restoration
Jun 11, 2024

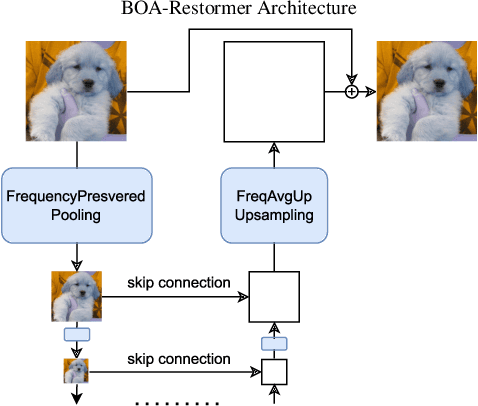

Image restoration networks are usually comprised of an encoder and a decoder, responsible for aggregating image content from noisy, distorted data and to restore clean, undistorted images, respectively. Data aggregation as well as high-resolution image generation both usually come at the risk of involving aliases, i.e.~standard architectures put their ability to reconstruct the model input in jeopardy to reach high PSNR values on validation data. The price to be paid is low model robustness. In this work, we show that simply providing alias-free paths in state-of-the-art reconstruction transformers supports improved model robustness at low costs on the restoration performance. We do so by proposing BOA-Restormer, a transformer-based image restoration model that executes downsampling and upsampling operations partly in the frequency domain to ensure alias-free paths along the entire model while potentially preserving all relevant high-frequency information.
Improving Stability during Upsampling -- on the Importance of Spatial Context
Nov 29, 2023State-of-the-art models for pixel-wise prediction tasks such as image restoration, image segmentation, or disparity estimation, involve several stages of data resampling, in which the resolution of feature maps is first reduced to aggregate information and then sequentially increased to generate a high-resolution output. Several previous works have investigated the effect of artifacts that are invoked during downsampling and diverse cures have been proposed that facilitate to improve prediction stability and even robustness for image classification. However, equally relevant, artifacts that arise during upsampling have been less discussed. This is significantly relevant as upsampling and downsampling approaches face fundamentally different challenges. While during downsampling, aliases and artifacts can be reduced by blurring feature maps, the emergence of fine details is crucial during upsampling. Blurring is therefore not an option and dedicated operations need to be considered. In this work, we are the first to explore the relevance of context during upsampling by employing convolutional upsampling operations with increasing kernel size while keeping the encoder unchanged. We find that increased kernel sizes can in general improve the prediction stability in tasks such as image restoration or image segmentation, while a block that allows for a combination of small-size kernels for fine details and large-size kernels for artifact removal and increased context yields the best results.
On the unreasonable vulnerability of transformers for image restoration -- and an easy fix
Jul 25, 2023Following their success in visual recognition tasks, Vision Transformers(ViTs) are being increasingly employed for image restoration. As a few recent works claim that ViTs for image classification also have better robustness properties, we investigate whether the improved adversarial robustness of ViTs extends to image restoration. We consider the recently proposed Restormer model, as well as NAFNet and the "Baseline network" which are both simplified versions of a Restormer. We use Projected Gradient Descent (PGD) and CosPGD, a recently proposed adversarial attack tailored to pixel-wise prediction tasks for our robustness evaluation. Our experiments are performed on real-world images from the GoPro dataset for image deblurring. Our analysis indicates that contrary to as advocated by ViTs in image classification works, these models are highly susceptible to adversarial attacks. We attempt to improve their robustness through adversarial training. While this yields a significant increase in robustness for Restormer, results on other networks are less promising. Interestingly, the design choices in NAFNet and Baselines, which were based on iid performance, and not on robust generalization, seem to be at odds with the model robustness. Thus, we investigate this further and find a fix.
Fix your downsampling ASAP! Be natively more robust via Aliasing and Spectral Artifact free Pooling
Jul 19, 2023



Convolutional neural networks encode images through a sequence of convolutions, normalizations and non-linearities as well as downsampling operations into potentially strong semantic embeddings. Yet, previous work showed that even slight mistakes during sampling, leading to aliasing, can be directly attributed to the networks' lack in robustness. To address such issues and facilitate simpler and faster adversarial training, [12] recently proposed FLC pooling, a method for provably alias-free downsampling - in theory. In this work, we conduct a further analysis through the lens of signal processing and find that such current pooling methods, which address aliasing in the frequency domain, are still prone to spectral leakage artifacts. Hence, we propose aliasing and spectral artifact-free pooling, short ASAP. While only introducing a few modifications to FLC pooling, networks using ASAP as downsampling method exhibit higher native robustness against common corruptions, a property that FLC pooling was missing. ASAP also increases native robustness against adversarial attacks on high and low resolution data while maintaining similar clean accuracy or even outperforming the baseline.
As large as it gets: Learning infinitely large Filters via Neural Implicit Functions in the Fourier Domain
Jul 19, 2023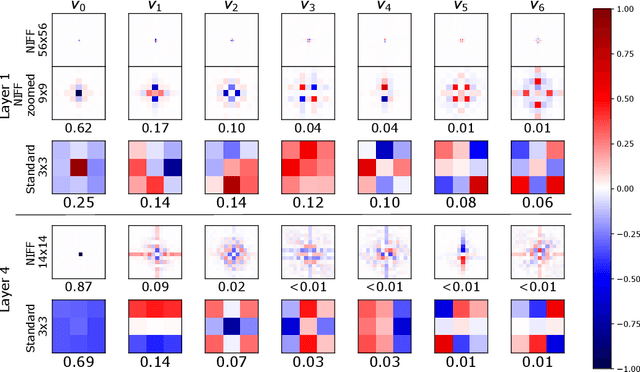

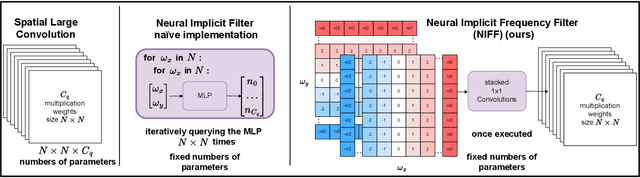
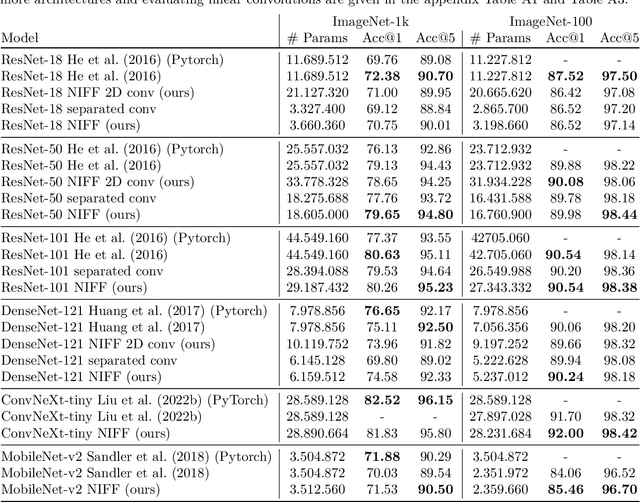
Motivated by the recent trend towards the usage of larger receptive fields for more context-aware neural networks in vision applications, we aim to investigate how large these receptive fields really need to be. To facilitate such study, several challenges need to be addressed, most importantly: (i) We need to provide an effective way for models to learn large filters (potentially as large as the input data) without increasing their memory consumption during training or inference, (ii) the study of filter sizes has to be decoupled from other effects such as the network width or number of learnable parameters, and (iii) the employed convolution operation should be a plug-and-play module that can replace any conventional convolution in a Convolutional Neural Network (CNN) and allow for an efficient implementation in current frameworks. To facilitate such models, we propose to learn not spatial but frequency representations of filter weights as neural implicit functions, such that even infinitely large filters can be parameterized by only a few learnable weights. The resulting neural implicit frequency CNNs are the first models to achieve results on par with the state-of-the-art on large image classification benchmarks while executing convolutions solely in the frequency domain and can be employed within any CNN architecture. They allow us to provide an extensive analysis of the learned receptive fields. Interestingly, our analysis shows that, although the proposed networks could learn very large convolution kernels, the learned filters practically translate into well-localized and relatively small convolution kernels in the spatial domain.
Robust Models are less Over-Confident
Oct 12, 2022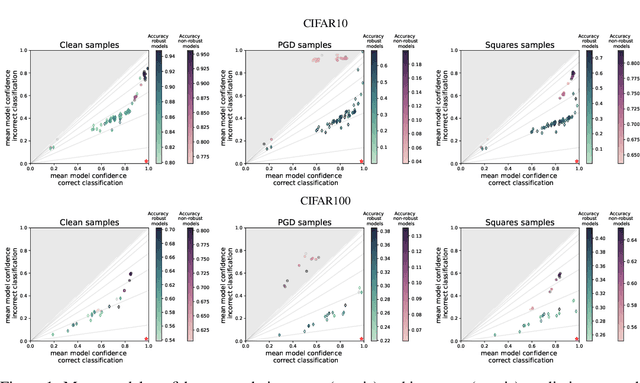

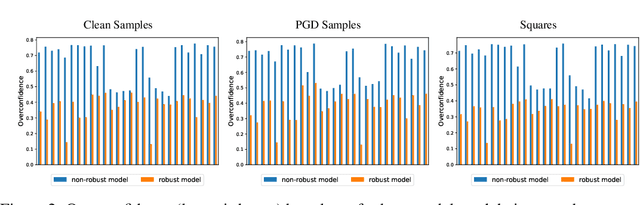

Despite the success of convolutional neural networks (CNNs) in many academic benchmarks for computer vision tasks, their application in the real-world is still facing fundamental challenges. One of these open problems is the inherent lack of robustness, unveiled by the striking effectiveness of adversarial attacks. Current attack methods are able to manipulate the network's prediction by adding specific but small amounts of noise to the input. In turn, adversarial training (AT) aims to achieve robustness against such attacks and ideally a better model generalization ability by including adversarial samples in the trainingset. However, an in-depth analysis of the resulting robust models beyond adversarial robustness is still pending. In this paper, we empirically analyze a variety of adversarially trained models that achieve high robust accuracies when facing state-of-the-art attacks and we show that AT has an interesting side-effect: it leads to models that are significantly less overconfident with their decisions, even on clean data than non-robust models. Further, our analysis of robust models shows that not only AT but also the model's building blocks (like activation functions and pooling) have a strong influence on the models' prediction confidences. Data & Project website: https://github.com/GeJulia/robustness_confidences_evaluation
FrequencyLowCut Pooling -- Plug & Play against Catastrophic Overfitting
Apr 01, 2022

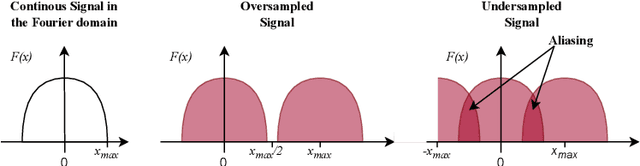
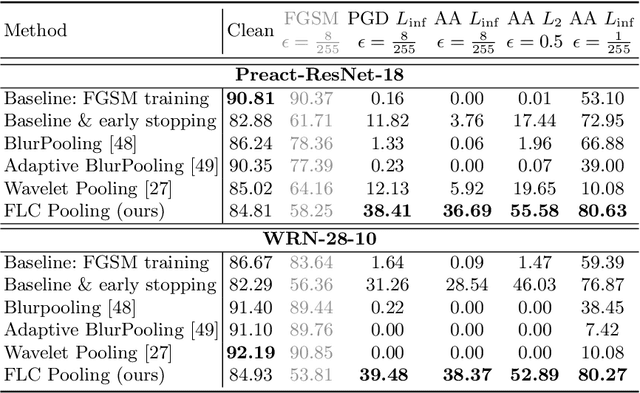
Over the last years, Convolutional Neural Networks (CNNs) have been the dominating neural architecture in a wide range of computer vision tasks. From an image and signal processing point of view, this success might be a bit surprising as the inherent spatial pyramid design of most CNNs is apparently violating basic signal processing laws, i.e. Sampling Theorem in their down-sampling operations. However, since poor sampling appeared not to affect model accuracy, this issue has been broadly neglected until model robustness started to receive more attention. Recent work [17] in the context of adversarial attacks and distribution shifts, showed after all, that there is a strong correlation between the vulnerability of CNNs and aliasing artifacts induced by poor down-sampling operations. This paper builds on these findings and introduces an aliasing free down-sampling operation which can easily be plugged into any CNN architecture: FrequencyLowCut pooling. Our experiments show, that in combination with simple and fast FGSM adversarial training, our hyper-parameter free operator significantly improves model robustness and avoids catastrophic overfitting.