 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAs large as it gets: Learning infinitely large Filters via Neural Implicit Functions in the Fourier Domain
Paper and Code
Jul 19, 2023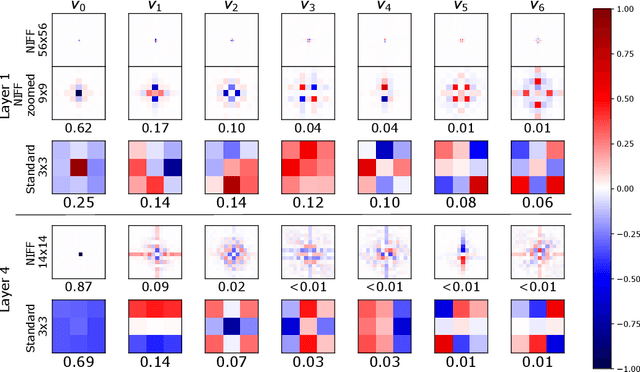

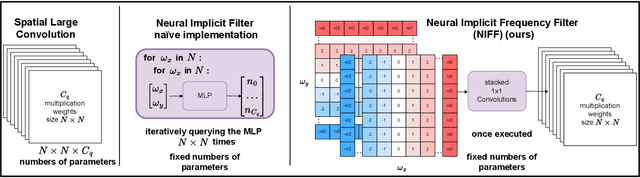
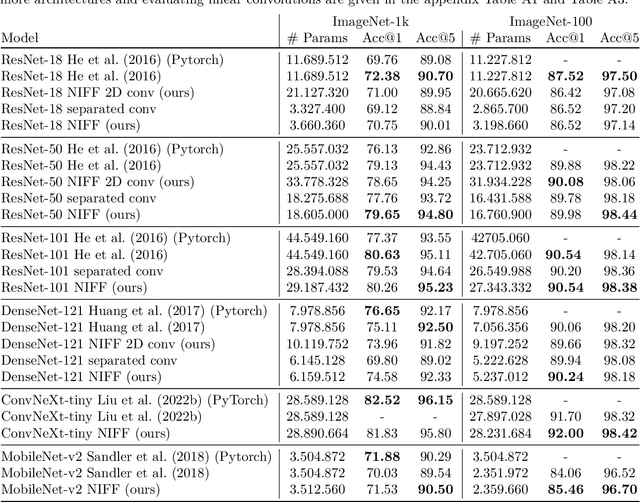
Motivated by the recent trend towards the usage of larger receptive fields for more context-aware neural networks in vision applications, we aim to investigate how large these receptive fields really need to be. To facilitate such study, several challenges need to be addressed, most importantly: (i) We need to provide an effective way for models to learn large filters (potentially as large as the input data) without increasing their memory consumption during training or inference, (ii) the study of filter sizes has to be decoupled from other effects such as the network width or number of learnable parameters, and (iii) the employed convolution operation should be a plug-and-play module that can replace any conventional convolution in a Convolutional Neural Network (CNN) and allow for an efficient implementation in current frameworks. To facilitate such models, we propose to learn not spatial but frequency representations of filter weights as neural implicit functions, such that even infinitely large filters can be parameterized by only a few learnable weights. The resulting neural implicit frequency CNNs are the first models to achieve results on par with the state-of-the-art on large image classification benchmarks while executing convolutions solely in the frequency domain and can be employed within any CNN architecture. They allow us to provide an extensive analysis of the learned receptive fields. Interestingly, our analysis shows that, although the proposed networks could learn very large convolution kernels, the learned filters practically translate into well-localized and relatively small convolution kernels in the spatial domain.