 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Sub-structured Knowledge Distillation
Paper and Code
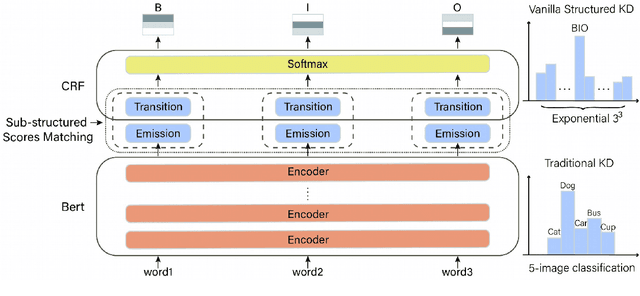
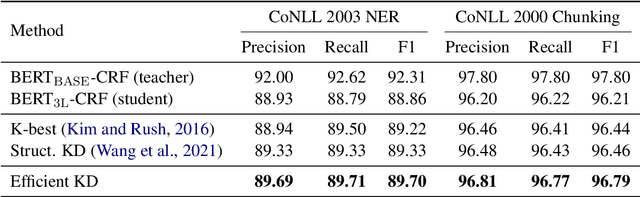

Structured prediction models aim at solving a type of problem where the output is a complex structure, rather than a single variable. Performing knowledge distillation for such models is not trivial due to their exponentially large output space. In this work, we propose an approach that is much simpler in its formulation and far more efficient for training than existing approaches. Specifically, we transfer the knowledge from a teacher model to its student model by locally matching their predictions on all sub-structures, instead of the whole output space. In this manner, we avoid adopting some time-consuming techniques like dynamic programming (DP) for decoding output structures, which permits parallel computation and makes the training process even faster in practice. Besides, it encourages the student model to better mimic the internal behavior of the teacher model. Experiments on two structured prediction tasks demonstrate that our approach outperforms previous methods and halves the time cost for one training epoch.