 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards a Foundation Model for Communication Systems
May 20, 2025
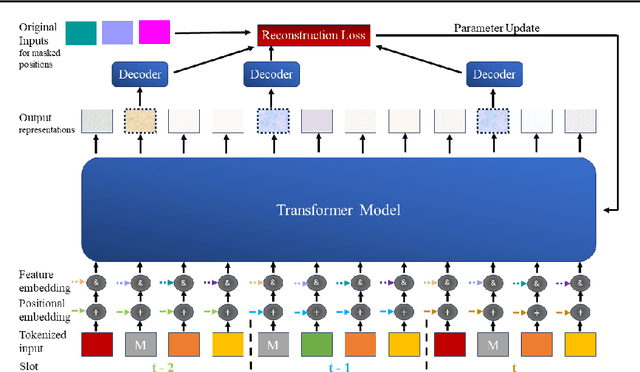
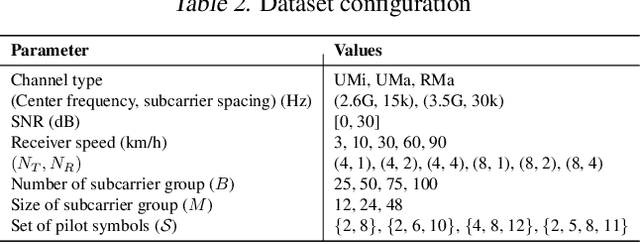
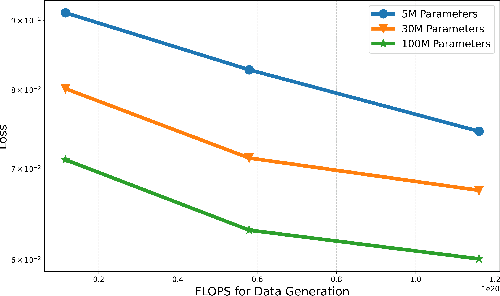
Artificial Intelligence (AI) has demonstrated unprecedented performance across various domains, and its application to communication systems is an active area of research. While current methods focus on task-specific solutions, the broader trend in AI is shifting toward large general models capable of supporting multiple applications. In this work, we take a step toward a foundation model for communication data--a transformer-based, multi-modal model designed to operate directly on communication data. We propose methodologies to address key challenges, including tokenization, positional embedding, multimodality, variable feature sizes, and normalization. Furthermore, we empirically demonstrate that such a model can successfully estimate multiple features, including transmission rank, selected precoder, Doppler spread, and delay profile.
GPT4GEO: How a Language Model Sees the World's Geography
May 30, 2023
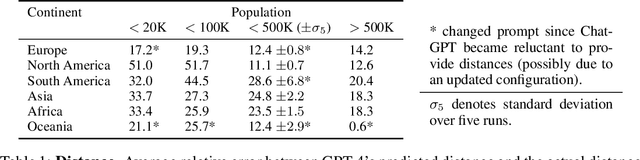
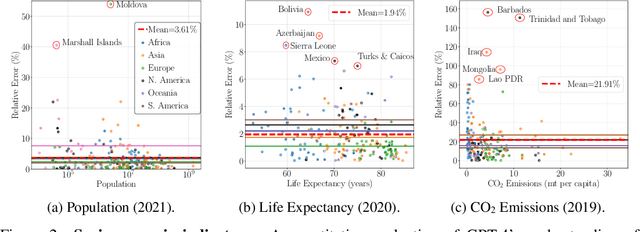
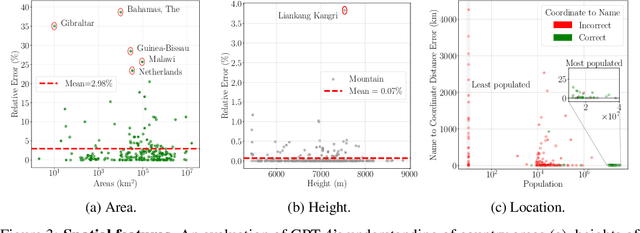
Large language models (LLMs) have shown remarkable capabilities across a broad range of tasks involving question answering and the generation of coherent text and code. Comprehensively understanding the strengths and weaknesses of LLMs is beneficial for safety, downstream applications and improving performance. In this work, we investigate the degree to which GPT-4 has acquired factual geographic knowledge and is capable of using this knowledge for interpretative reasoning, which is especially important for applications that involve geographic data, such as geospatial analysis, supply chain management, and disaster response. To this end, we design and conduct a series of diverse experiments, starting from factual tasks such as location, distance and elevation estimation to more complex questions such as generating country outlines and travel networks, route finding under constraints and supply chain analysis. We provide a broad characterisation of what GPT-4 (without plugins or Internet access) knows about the world, highlighting both potentially surprising capabilities but also limitations.
GCA-Net : Utilizing Gated Context Attention for Improving Image Forgery Localization and Detection
Dec 08, 2021


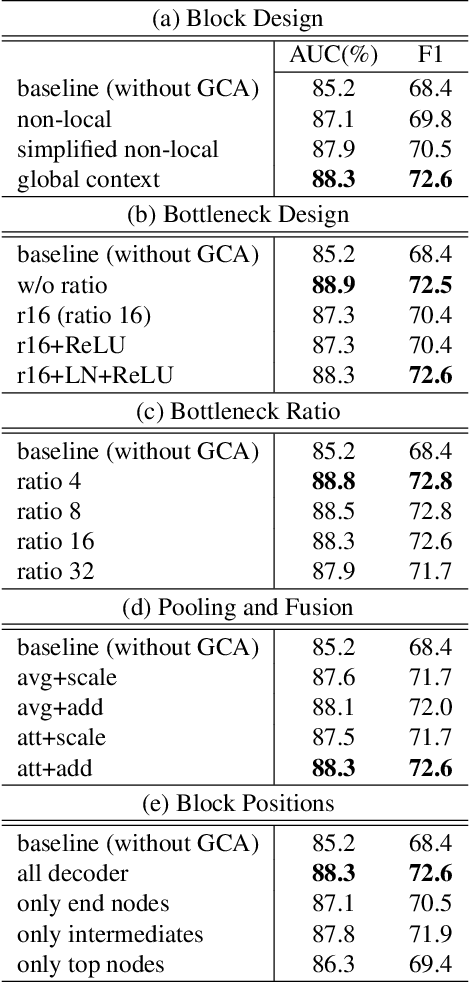
Forensic analysis depends on the identification of hidden traces from manipulated images. Traditional neural networks fail in this task because of their inability in handling feature attenuation and reliance on the dominant spatial features. In this work we propose a novel Gated Context Attention Network (GCA-Net) that utilizes the non-local attention block for global context learning. Additionally, we utilize a gated attention mechanism in conjunction with a dense decoder network to direct the flow of relevant features during the decoding phase, allowing for precise localization. The proposed attention framework allows the network to focus on relevant regions by filtering the coarse features. Furthermore, by utilizing multi-scale feature fusion and efficient learning strategies, GCA-Net can better handle the scale variation of manipulated regions. We show that our method outperforms state-of-the-art networks by an average of 4.2%-5.4% AUC on multiple benchmark datasets. Lastly, we also conduct extensive ablation experiments to demonstrate the method's robustness for image forensics.
Improving DeepFake Detection Using Dynamic Face Augmentation
Feb 18, 2021

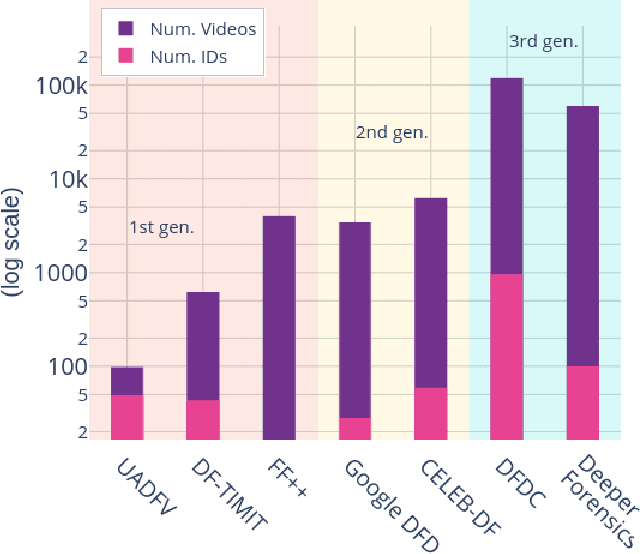
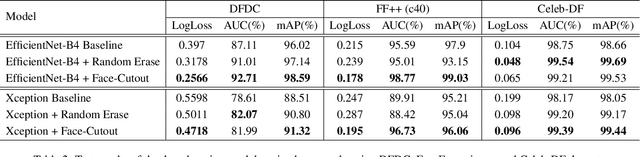
The creation of altered and manipulated faces has become more common due to the improvement of DeepFake generation methods. Simultaneously, we have seen detection models' development for differentiating between a manipulated and original face from image or video content. We have observed that most publicly available DeepFake detection datasets have limited variations, where a single face is used in many videos, resulting in an oversampled training dataset. Due to this, deep neural networks tend to overfit to the facial features instead of learning to detect manipulation features of DeepFake content. As a result, most detection architectures perform poorly when tested on unseen data. In this paper, we provide a quantitative analysis to investigate this problem and present a solution to prevent model overfitting due to the high volume of samples generated from a small number of actors. We introduce Face-Cutout, a data augmentation method for training Convolutional Neural Networks (CNN), to improve DeepFake detection. In this method, training images with various occlusions are dynamically generated using face landmark information irrespective of orientation. Unlike other general-purpose augmentation methods, it focuses on the facial information that is crucial for DeepFake detection. Our method achieves a reduction in LogLoss of 15.2% to 35.3% on different datasets, compared to other occlusion-based augmentation techniques. We show that Face-Cutout can be easily integrated with any CNN-based recognition model and improve detection performance.