 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSecure Code Generation at Scale with Reflexion
Nov 05, 2025

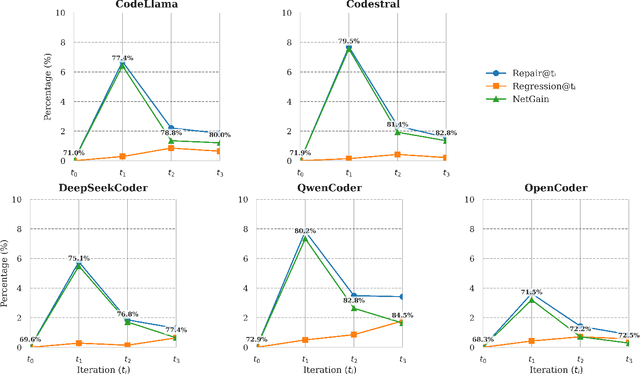

Large language models (LLMs) are now widely used to draft and refactor code, but code that works is not necessarily secure. We evaluate secure code generation using the Instruct Prime, which eliminated compliance-required prompts and cue contamination, and evaluate five instruction-tuned code LLMs using a zero-shot baseline and a three-round reflexion prompting approach. Security is measured using the Insecure Code Detector (ICD), and results are reported by measuring Repair, Regression, and NetGain metrics, considering the programming language and CWE family. Our findings show that insecurity remains common at the first round: roughly 25-33% of programs are insecure at a zero-shot baseline (t0 ). Weak cryptography/config-dependent bugs are the hardest to avoid while templated ones like XSS, code injection, and hard-coded secrets are handled more reliably. Python yields the highest secure rates; C and C# are the lowest, with Java, JS, PHP, and C++ in the middle. Reflexion prompting improves security for all models, improving average accuracy from 70.74% at t0 to 79.43% at t3 , with the largest gains in the first round followed by diminishing returns. The trends with Repair, Regression, and NetGain metrics show that applying one to two rounds produces most of the benefits. A replication package is available at https://doi.org/10.5281/zenodo.17065846.
Improving DeepFake Detection Using Dynamic Face Augmentation
Feb 18, 2021

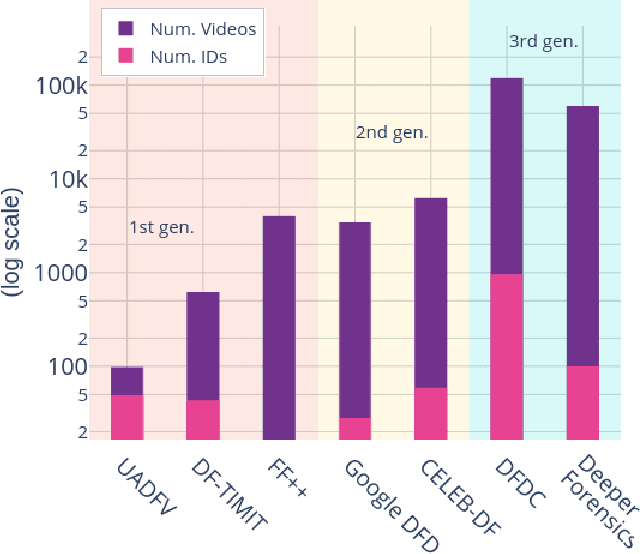
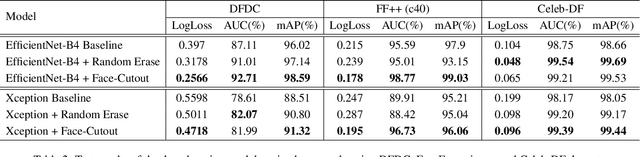
The creation of altered and manipulated faces has become more common due to the improvement of DeepFake generation methods. Simultaneously, we have seen detection models' development for differentiating between a manipulated and original face from image or video content. We have observed that most publicly available DeepFake detection datasets have limited variations, where a single face is used in many videos, resulting in an oversampled training dataset. Due to this, deep neural networks tend to overfit to the facial features instead of learning to detect manipulation features of DeepFake content. As a result, most detection architectures perform poorly when tested on unseen data. In this paper, we provide a quantitative analysis to investigate this problem and present a solution to prevent model overfitting due to the high volume of samples generated from a small number of actors. We introduce Face-Cutout, a data augmentation method for training Convolutional Neural Networks (CNN), to improve DeepFake detection. In this method, training images with various occlusions are dynamically generated using face landmark information irrespective of orientation. Unlike other general-purpose augmentation methods, it focuses on the facial information that is crucial for DeepFake detection. Our method achieves a reduction in LogLoss of 15.2% to 35.3% on different datasets, compared to other occlusion-based augmentation techniques. We show that Face-Cutout can be easily integrated with any CNN-based recognition model and improve detection performance.