 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Robotic Knee Arthroscopy: Multi-Scale Network for Tissue-Tool Segmentation
Oct 06, 2021
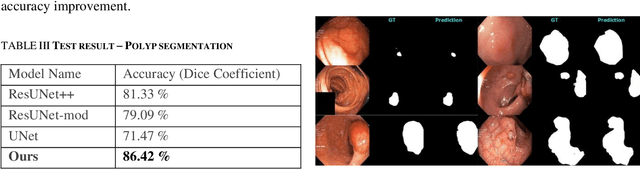
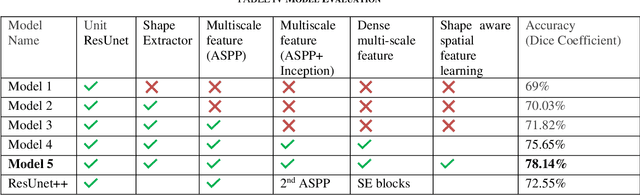
Tissue awareness has a great demand to improve surgical accuracy in minimally invasive procedures. In arthroscopy, it is one of the challenging tasks due to surgical sites exhibit limited features and textures. Moreover, arthroscopic surgical video shows high intra-class variations. Arthroscopic videos are recorded with endoscope known as arthroscope which records tissue structures at proximity, therefore, frames contain minimal joint structure. As consequences, fully conventional network-based segmentation model suffers from long- and short- term dependency problems. In this study, we present a densely connected shape aware multi-scale segmentation model which captures multi-scale features and integrates shape features to achieve tissue-tool segmentations. The model has been evaluated with three distinct datasets. Moreover, with the publicly available polyp dataset our proposed model achieved 5.09 % accuracy improvement.
Surgery Scene Restoration for Robot Assisted Minimally Invasive Surgery
Sep 06, 2021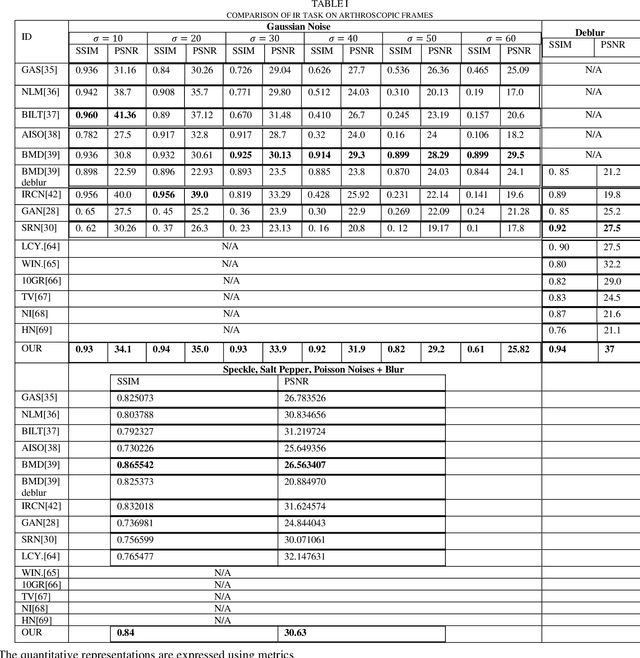
Minimally invasive surgery (MIS) offers several advantages including minimum tissue injury and blood loss, and quick recovery time, however, it imposes some limitations on surgeons ability. Among others such as lack of tactile or haptic feedback, poor visualization of the surgical site is one of the most acknowledged factors that exhibits several surgical drawbacks including unintentional tissue damage. To the context of robot assisted surgery, lack of frame contextual details makes vision task challenging when it comes to tracking tissue and tools, segmenting scene, and estimating pose and depth. In MIS the acquired frames are compromised by different noises and get blurred caused by motions from different sources. Moreover, when underwater environment is considered for instance knee arthroscopy, mostly visible noises and blur effects are originated from the environment, poor control on illuminations and imaging conditions. Additionally, in MIS, procedure like automatic white balancing and transformation between the raw color information to its standard RGB color space are often absent due to the hardware miniaturization. There is a high demand of an online preprocessing framework that can circumvent these drawbacks. Our proposed method is able to restore a latent clean and sharp image in standard RGB color space from its noisy, blur and raw observation in a single preprocessing stage.
3D Semantic Mapping from Arthroscopy using Out-of-distribution Pose and Depth and In-distribution Segmentation Training
Jun 10, 2021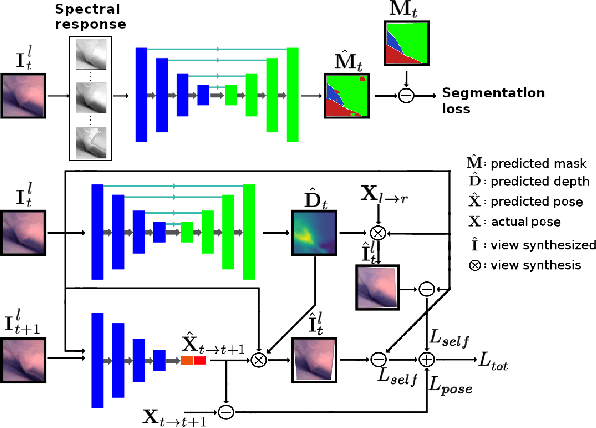
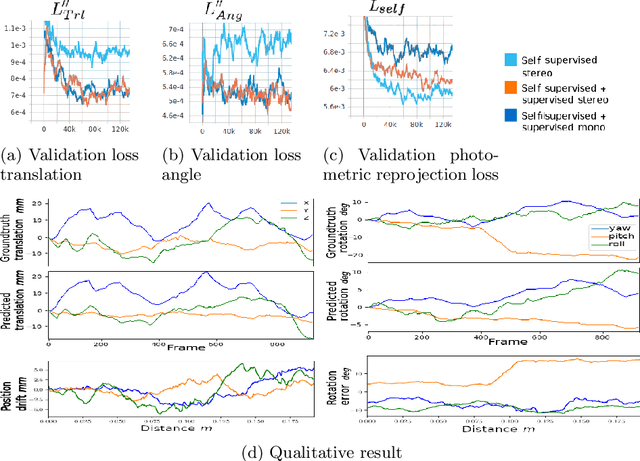
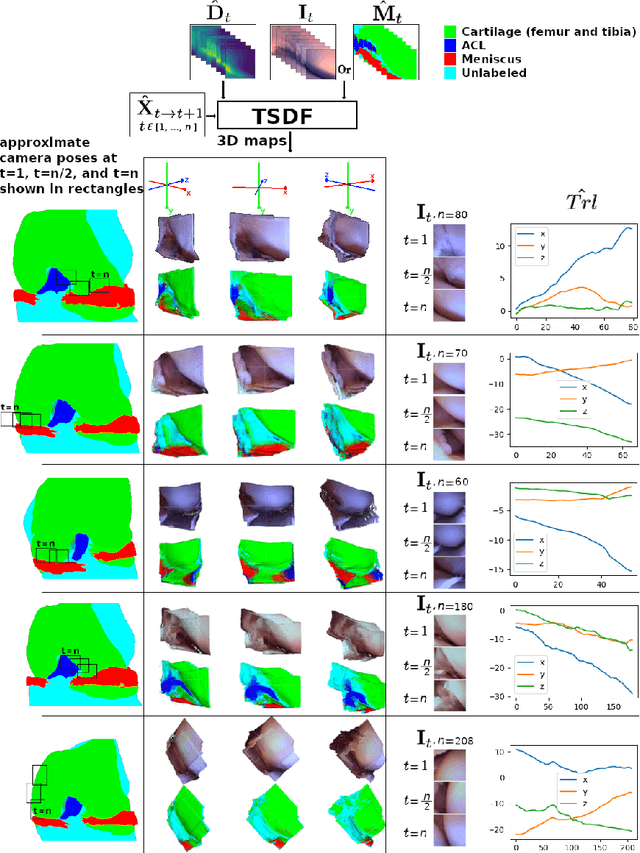
Minimally invasive surgery (MIS) has many documented advantages, but the surgeon's limited visual contact with the scene can be problematic. Hence, systems that can help surgeons navigate, such as a method that can produce a 3D semantic map, can compensate for the limitation above. In theory, we can borrow 3D semantic mapping techniques developed for robotics, but this requires finding solutions to the following challenges in MIS: 1) semantic segmentation, 2) depth estimation, and 3) pose estimation. In this paper, we propose the first 3D semantic mapping system from knee arthroscopy that solves the three challenges above. Using out-of-distribution non-human datasets, where pose could be labeled, we jointly train depth+pose estimators using selfsupervised and supervised losses. Using an in-distribution human knee dataset, we train a fully-supervised semantic segmentation system to label arthroscopic image pixels into femur, ACL, and meniscus. Taking testing images from human knees, we combine the results from these two systems to automatically create 3D semantic maps of the human knee. The result of this work opens the pathway to the generation of intraoperative 3D semantic mapping, registration with pre-operative data, and robotic-assisted arthroscopy
Arthroscopic Multi-Spectral Scene Segmentation Using Deep Learning
Mar 03, 2021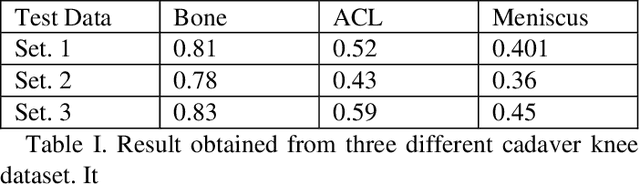
Knee arthroscopy is a minimally invasive surgical (MIS) procedure which is performed to treat knee-joint ailment. Lack of visual information of the surgical site obtained from miniaturized cameras make this surgical procedure more complex. Knee cavity is a very confined space; therefore, surgical scenes are captured at close proximity. Insignificant context of knee atlas often makes them unrecognizable as a consequence unintentional tissue damage often occurred and shows a long learning curve to train new surgeons. Automatic context awareness through labeling of the surgical site can be an alternative to mitigate these drawbacks. However, from the previous studies, it is confirmed that the surgical site exhibits several limitations, among others, lack of discriminative contextual information such as texture and features which drastically limits this vision task. Additionally, poor imaging conditions and lack of accurate ground-truth labels are also limiting the accuracy. To mitigate these limitations of knee arthroscopy, in this work we proposed a scene segmentation method that successfully segments multi structures.