 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComparison of marker-less 2D image-based methods for infant pose estimation
Oct 07, 2024There are increasing efforts to automate clinical methods for early diagnosis of developmental disorders, among them the General Movement Assessment (GMA), a video-based tool to classify infant motor functioning. Optimal pose estimation is a crucial part of the automated GMA. In this study we compare the performance of available generic- and infant-pose estimators, and the choice of viewing angle for optimal recordings, i.e., conventional diagonal view used in GMA vs. top-down view. For this study, we used 4500 annotated video-frames from 75 recordings of infant spontaneous motor functions from 4 to 26 weeks. To determine which available pose estimation method and camera angle yield the best pose estimation accuracy on infants in a GMA related setting, the distance to human annotations as well as the percentage of correct key-points (PCK) were computed and compared. The results show that the best performing generic model trained on adults, ViTPose, also performs best on infants. We see no improvement from using specialized infant-pose estimators over the generic pose estimators on our own infant dataset. However, when retraining a generic model on our data, there is a significant improvement in pose estimation accuracy. The pose estimation accuracy obtained from the top-down view is significantly better than that obtained from the diagonal view, especially for the detection of the hip key-points. The results also indicate only limited generalization capabilities of infant-pose estimators to other infant datasets, which hints that one should be careful when choosing infant pose estimators and using them on infant datasets which they were not trained on. While the standard GMA method uses a diagonal view for assessment, pose estimation accuracy significantly improves using a top-down view. This suggests that a top-down view should be included in recording setups for automated GMA research.
Deep learning empowered sensor fusion to improve infant movement classification
Jun 14, 2024There is a recent boom in the development of AI solutions to facilitate and enhance diagnostic procedures for established clinical tools. To assess the integrity of the developing nervous system, the Prechtl general movement assessment (GMA) is recognized for its clinical value in diagnosing neurological impairments in early infancy. GMA has been increasingly augmented through machine learning approaches intending to scale-up its application, circumvent costs in the training of human assessors and further standardize classification of spontaneous motor patterns. Available deep learning tools, all of which are based on single sensor modalities, are however still considerably inferior to that of well-trained human assessors. These approaches are hardly comparable as all models are designed, trained and evaluated on proprietary/silo-data sets. With this study we propose a sensor fusion approach for assessing fidgety movements (FMs) comparing three different sensor modalities (pressure, inertial, and visual sensors). Various combinations and two sensor fusion approaches (late and early fusion) for infant movement classification were tested to evaluate whether a multi-sensor system outperforms single modality assessments. The performance of the three-sensor fusion (classification accuracy of 94.5\%) was significantly higher than that of any single modality evaluated, suggesting the sensor fusion approach is a promising avenue for automated classification of infant motor patterns. The development of a robust sensor fusion system may significantly enhance AI-based early recognition of neurofunctions, ultimately facilitating automated early detection of neurodevelopmental conditions.
Facilitating deep acoustic phenotyping: A basic coding scheme of infant vocalisations preluding computational analysis, machine learning and clinical reasoning
Mar 14, 2023Theoretical background: early verbal development is not yet fully understood, especially in its formative phase. Research question: can a reliable, easy-to-use coding scheme for the classification of early infant vocalizations be defined that is applicable as a basis for further analysis of language development? Methods: in a longitudinal study of 45 neurotypical infants, we analyzed vocalizations of the first 4 months of life. Audio segments were assigned to 5 classes: (1) Voiced and (2) Voiceless vocalizations; (3) Defined signal; (4) Non-target; (5) Nonassignable. Results: Two female coders with different experience achieved high agreement without intensive training. Discussion and Conclusion: The reliable scheme can be used in research and clinical settings for efficient coding of infant vocalizations, as a basis for detailed manual and machine analyses.
Comparison of Motion Encoding Frameworks on Human Manipulation Actions
Nov 23, 2022
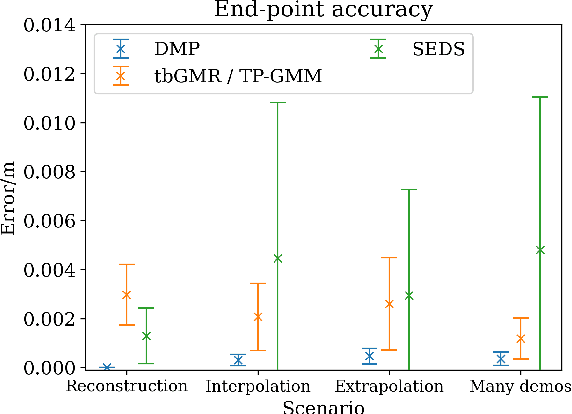
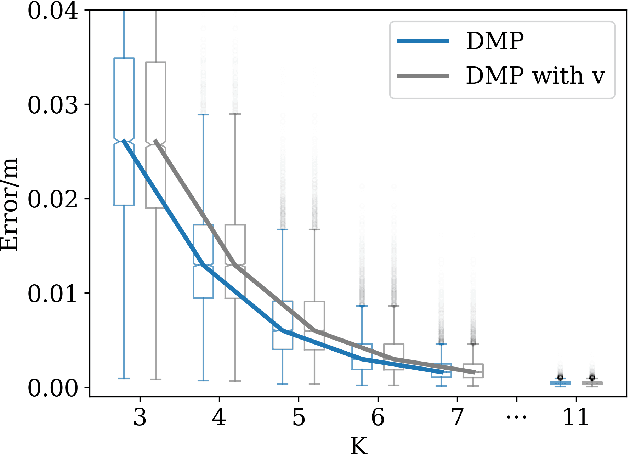
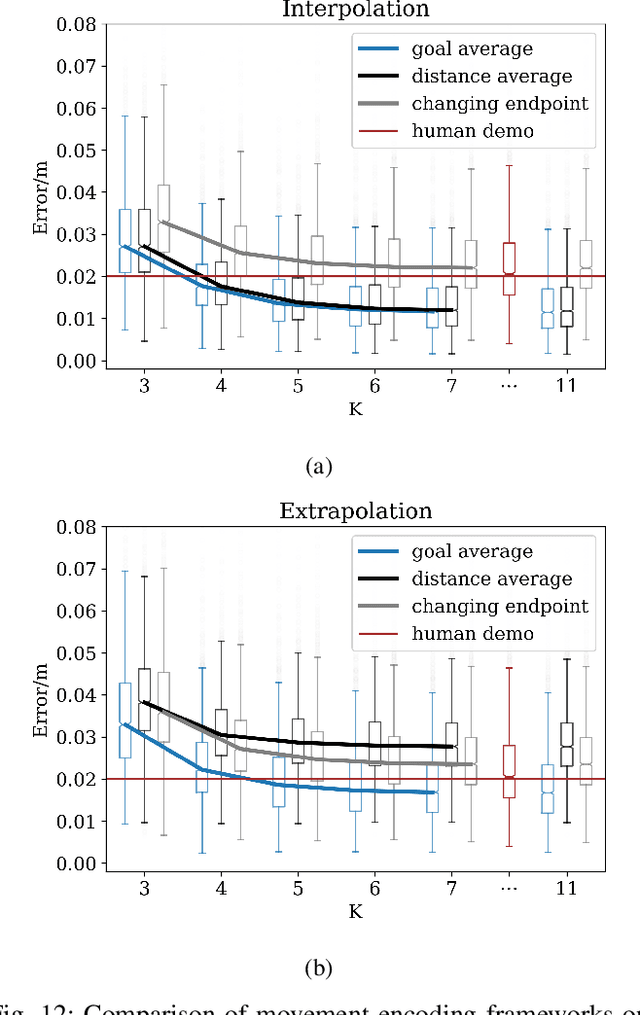
Movement generation, and especially generalisation to unseen situations, plays an important role in robotics. Different types of movement generation methods exist such as spline based methods, dynamical system based methods, and methods based on Gaussian mixture models (GMMs). Using a large, new dataset on human manipulations, in this paper we provide a highly detailed comparison of three most widely used movement encoding and generation frameworks: dynamic movement primitives (DMPs), time based Gaussian mixture regression (tbGMR) and stable estimator of dynamical systems (SEDS). We compare these frameworks with respect to their movement encoding efficiency, reconstruction accuracy, and movement generalisation capabilities. The new dataset consists of nine object manipulation actions performed by 12 humans: pick and place, put on top/take down, put inside/take out, hide/uncover, and push/pull with a total of 7,652 movement examples. Our analysis shows that for movement encoding and reconstruction DMPs are the most efficient framework with respect to the number of parameters and reconstruction accuracy if a sufficient number of kernels is used. In case of movement generalisation to new start- and end-point situations, DMPs and task parameterized GMM (TP-GMM, movement generalisation framework based on tbGMR) lead to similar performance and outperform SEDS. Furthermore we observe that TP-GMM and SEDS suffer from inaccurate convergence to the end-point as compared to DMPs. These different quantitative results will help designing trajectory representations in an improved task-dependent way in future robotic applications.
Simulated Mental Imagery for Robotic Task Planning
Nov 23, 2022



Traditional AI-planning methods for task planning in robotics require symbolically encoded domain description. While powerful in well-defined scenarios, setting this up requires substantial effort. Different from this, most everyday planning tasks are solved by humans intuitively, using mental imagery of the different planning steps. Here we suggest that the same approach can be used for robots, too, in cases which require only limited execution accuracy. In the current study, we propose a novel sub-symbolic method called Simulated Mental Imagery for Planning (SiMIP), which consists of several steps: perception, simulated action, success-checking and re-planning performed on 'imagined' images. We show that it is possible this way to implement mental imagery-based planning in an algorithmically sound way by combining regular convolutional neural networks and generative adversarial networks. With this method, the robot acquires the capability to use the initially existing scene to generate action plans without symbolic domain descriptions, hence, without the need to define an explicit representation of the environment. We create a dataset from real scenes for a packing problem of having to correctly place different objects into different target slots. This way efficiency and success rate of this algorithm could be quantified.
Infant movement classification through pressure distribution analysis -- added value for research and clinical implementation
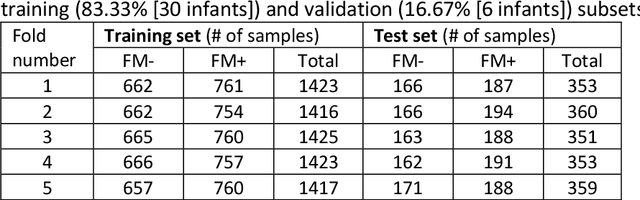
Jul 26, 2022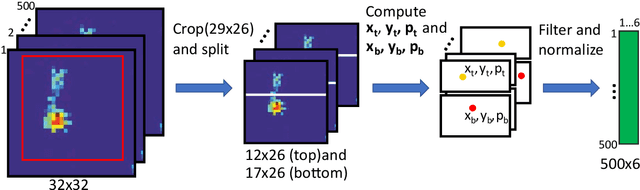
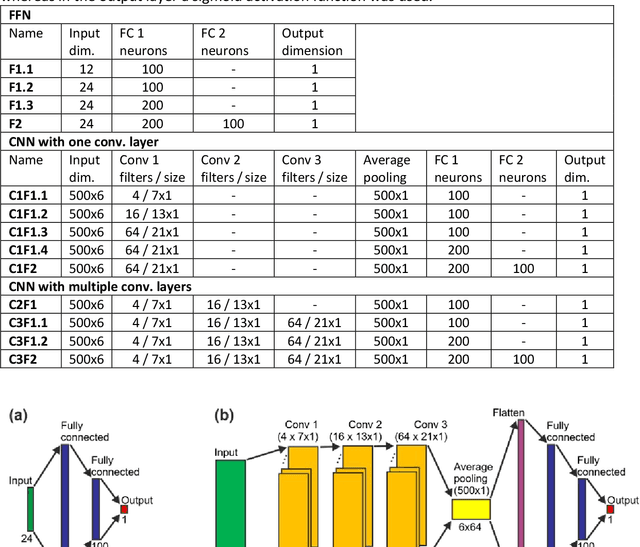
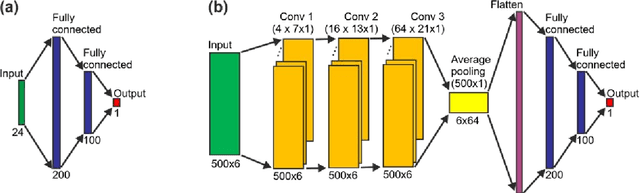
In recent years, numerous automated approaches complementing the human Prechtl's general movements assessment (GMA) were developed. Most approaches utilised RGB or RGB-D cameras to obtain motion data, while a few employed accelerometers or inertial measurement units. In this paper, within a prospective longitudinal infant cohort study applying a multimodal approach for movement tracking and analyses, we examined for the first time the performance of pressure sensors for classifying an infant general movements pattern, the fidgety movements. We developed an algorithm to encode movements with pressure data from a 32x32 grid mat with 1024 sensors. Multiple neural network architectures were investigated to distinguish presence vs. absence of the fidgety movements, including the feed-forward networks (FFNs) with manually defined statistical features and the convolutional neural networks (CNNs) with learned features. The CNN with multiple convolutional layers and learned features outperformed the FFN with manually defined statistical features, with classification accuracy of $81.4\%$ and $75.6\%$, respectively. We compared the pros and cons of the pressure sensing approach to the video-based and inertial motion senor-based approaches for analysing infant movements. The non-intrusive, extremely easy-to-use pressure sensing approach has great potential for efficient large-scaled movement data acquisition across cites and for application in busy daily clinical routines for evaluating infant neuromotor functions. The pressure sensors can be combined with other sensor modalities to enhance infant movement analyses in research and practice, as proposed in our multimodal sensor fusion model.
Open video data sharing in developmental and behavioural science
Jul 22, 2022



Video recording is a widely used method for documenting infant and child behaviours in research and clinical practice. Video data has rarely been shared due to ethical concerns of confidentiality, although the need of shared large-scaled datasets remains increasing. This demand is even more imperative when data-driven computer-based approaches are involved, such as screening tools to complement clinical assessments. To share data while abiding by privacy protection rules, a critical question arises whether efforts at data de-identification reduce data utility? We addressed this question by showcasing the Prechtl's general movements assessment (GMA), an established and globally practised video-based diagnostic tool in early infancy for detecting neurological deficits, such as cerebral palsy. To date, no shared expert-annotated large data repositories for infant movement analyses exist. Such datasets would massively benefit training and recalibration of human assessors and the development of computer-based approaches. In the current study, sequences from a prospective longitudinal infant cohort with a total of 19451 available general movements video snippets were randomly selected for human clinical reasoning and computer-based analysis. We demonstrated for the first time that pseudonymisation by face-blurring video recordings is a viable approach. The video redaction did not affect classification accuracy for either human assessors or computer vision methods, suggesting an adequate and easy-to-apply solution for sharing movement video data. We call for further explorations into efficient and privacy rule-conforming approaches for deidentifying video data in scientific and clinical fields beyond movement assessments. These approaches shall enable sharing and merging stand-alone video datasets into large data pools to advance science and public health.
3D object reconstruction and 6D-pose estimation from 2D shape for robotic grasping of objects
Mar 02, 2022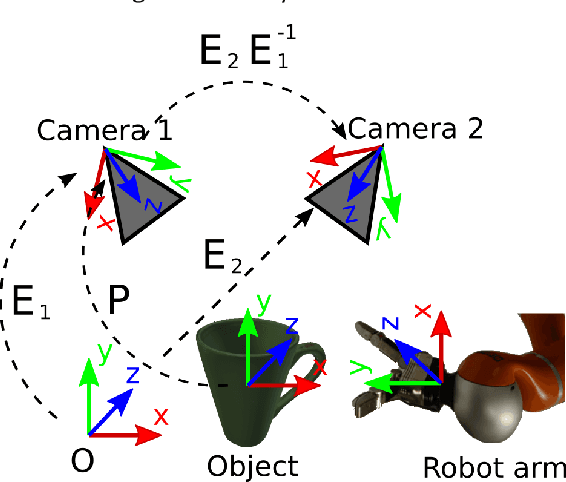

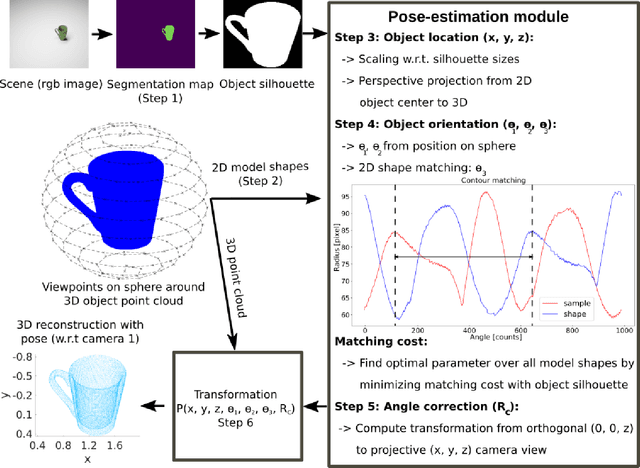
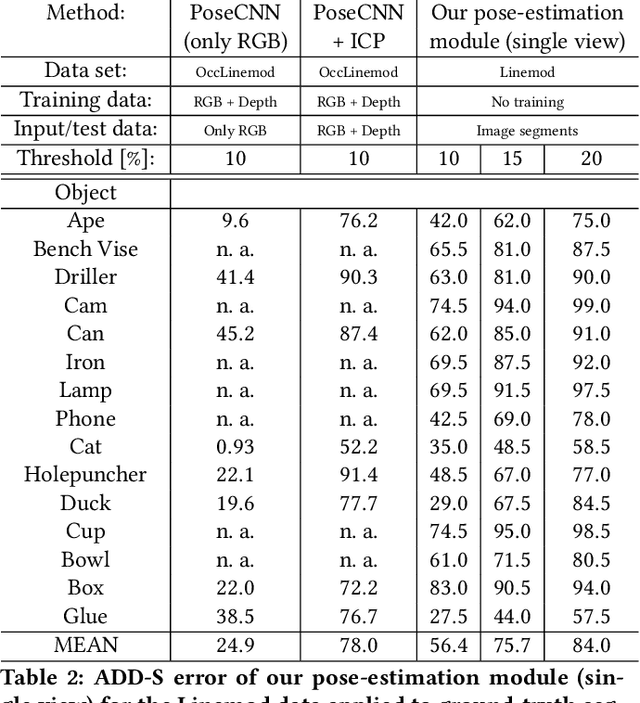
We propose a method for 3D object reconstruction and 6D-pose estimation from 2D images that uses knowledge about object shape as the primary key. In the proposed pipeline, recognition and labeling of objects in 2D images deliver 2D segment silhouettes that are compared with the 2D silhouettes of projections obtained from various views of a 3D model representing the recognized object class. By computing transformation parameters directly from the 2D images, the number of free parameters required during the registration process is reduced, making the approach feasible. Furthermore, 3D transformations and projective geometry are employed to arrive at a full 3D reconstruction of the object in camera space using a calibrated set up. Inclusion of a second camera allows resolving remaining ambiguities. The method is quantitatively evaluated using synthetic data and tested with real data, and additional results for the well-known Linemod data set are shown. In robot experiments, successful grasping of objects demonstrates its usability in real-world environments, and, where possible, a comparison with other methods is provided. The method is applicable to scenarios where 3D object models, e.g., CAD-models or point clouds, are available and precise pixel-wise segmentation maps of 2D images can be obtained. Different from other methods, the method does not use 3D depth for training, widening the domain of application.
Combining optimal path search with task-dependent learning in a neural network
Jan 27, 2022
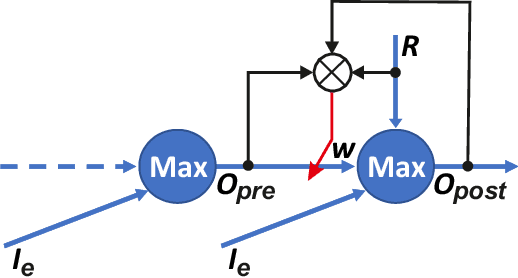


Finding optimal paths in connected graphs requires determining the smallest total cost for traveling along the graph's edges. This problem can be solved by several classical algorithms where, usually, costs are predefined for all edges. Conventional planning methods can, thus, normally not be used when wanting to change costs in an adaptive way following the requirements of some task. Here we show that one can define a neural network representation of path finding problems by transforming cost values into synaptic weights, which allows for online weight adaptation using network learning mechanisms. When starting with an initial activity value of one, activity propagation in this network will lead to solutions, which are identical to those found by the Bellman Ford algorithm. The neural network has the same algorithmic complexity as Bellman Ford and, in addition, we can show that network learning mechanisms (such as Hebbian learning) can adapt the weights in the network augmenting the resulting paths according to some task at hand. We demonstrate this by learning to navigate in an environment with obstacles as well as by learning to follow certain sequences of path nodes. Hence, the here-presented novel algorithm may open up a different regime of applications where path-augmentation (by learning) is directly coupled with path finding in a natural way.
Bootstrapping Concept Formation in Small Neural Networks
Oct 26, 2021


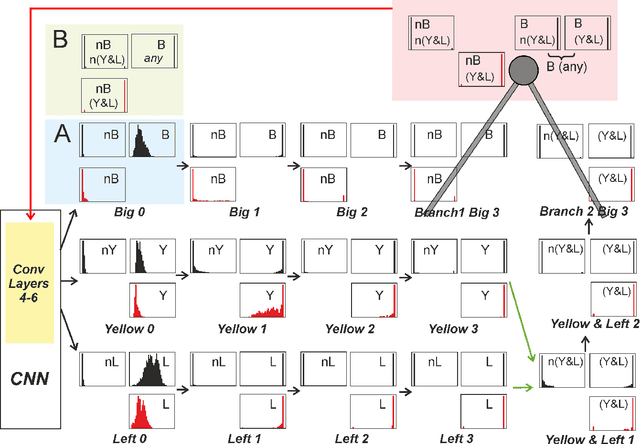
The question how neural systems (of humans) can perform reasoning is still far from being solved. We posit that the process of forming Concepts is a fundamental step required for this. We argue that, first, Concepts are formed as closed representations, which are then consolidated by relating them to each other. Here we present a model system (agent) with a small neural network that uses realistic learning rules and receives only feedback from the environment in which the agent performs virtual actions. First, the actions of the agent are reflexive. In the process of learning, statistical regularities in the input lead to the formation of neuronal pools representing relations between the entities observed by the agent from its artificial world. This information then influences the behavior of the agent via feedback connections replacing the initial reflex by an action driven by these relational representations. We hypothesize that the neuronal pools representing relational information can be considered as primordial Concepts, which may in a similar way be present in some pre-linguistic animals, too. We argue that systems such as this can help formalizing the discussion about what constitutes Concepts and serve as a starting point for constructing artificial cogitating systems.