 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D object reconstruction and 6D-pose estimation from 2D shape for robotic grasping of objects
Mar 02, 2022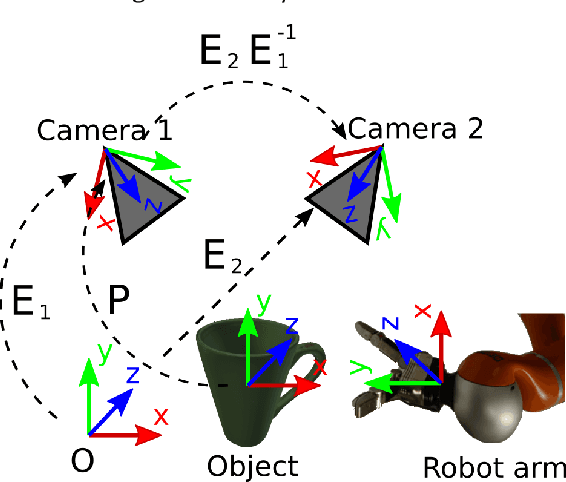

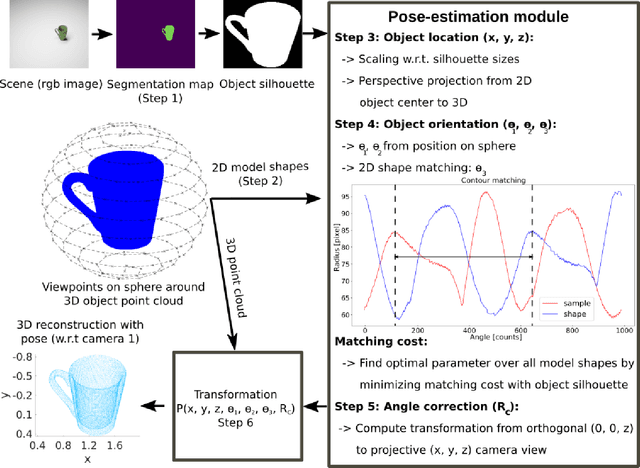
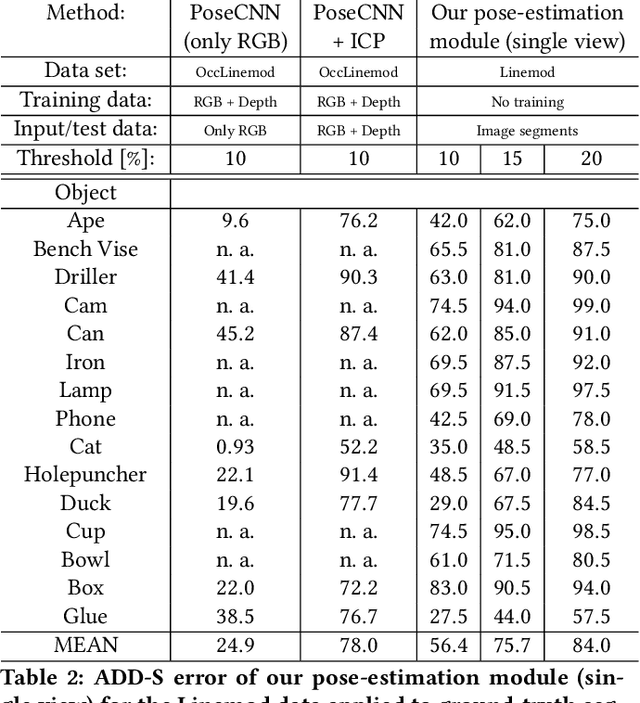
We propose a method for 3D object reconstruction and 6D-pose estimation from 2D images that uses knowledge about object shape as the primary key. In the proposed pipeline, recognition and labeling of objects in 2D images deliver 2D segment silhouettes that are compared with the 2D silhouettes of projections obtained from various views of a 3D model representing the recognized object class. By computing transformation parameters directly from the 2D images, the number of free parameters required during the registration process is reduced, making the approach feasible. Furthermore, 3D transformations and projective geometry are employed to arrive at a full 3D reconstruction of the object in camera space using a calibrated set up. Inclusion of a second camera allows resolving remaining ambiguities. The method is quantitatively evaluated using synthetic data and tested with real data, and additional results for the well-known Linemod data set are shown. In robot experiments, successful grasping of objects demonstrates its usability in real-world environments, and, where possible, a comparison with other methods is provided. The method is applicable to scenarios where 3D object models, e.g., CAD-models or point clouds, are available and precise pixel-wise segmentation maps of 2D images can be obtained. Different from other methods, the method does not use 3D depth for training, widening the domain of application.
Action Prediction in Humans and Robots
Jul 03, 2019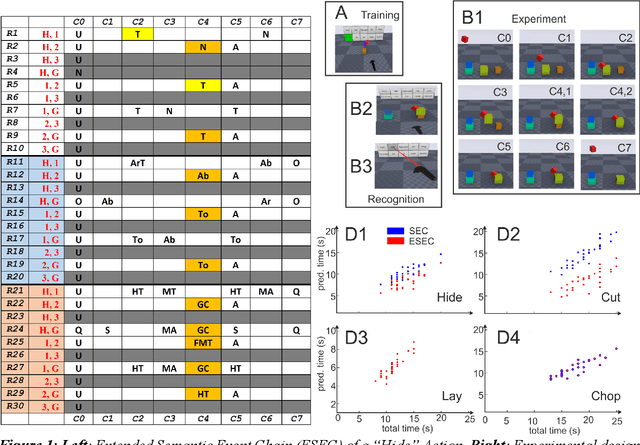
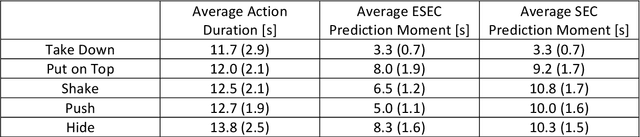
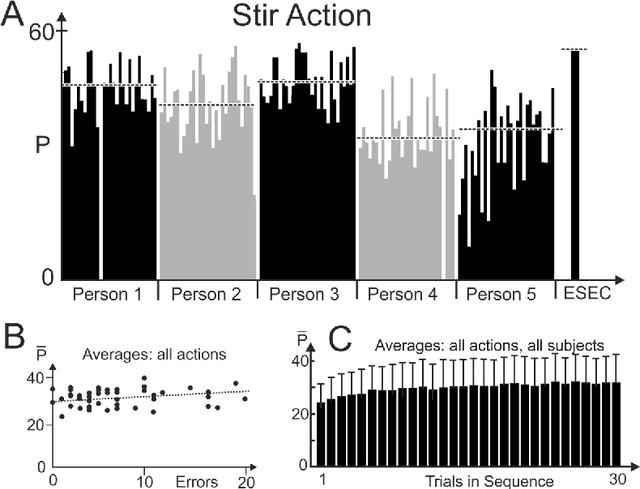
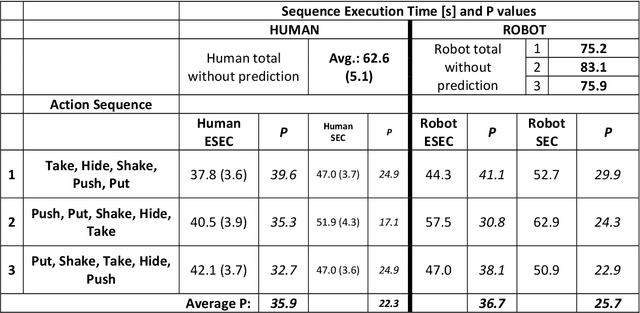
Efficient action prediction is of central importance for the fluent workflow between humans and equally so for human-robot interaction. To achieve prediction, actions can be encoded by a series of events, where every event corresponds to a change in a (static or dynamic) relation between some of the objects in a scene. Manipulation actions and others can be uniquely encoded this way and only, on average, less than 60% of the time series has to pass until an action can be predicted. Using a virtual reality setup and testing ten different manipulation actions, here we show that in most cases humans predict actions at the same event as the algorithm. In addition, we perform an in-depth analysis about the temporal gain resulting from such predictions when chaining actions and show in some robotic experiments that the percentage gain for humans and robots is approximately equal. Thus, if robots use this algorithm then their prediction-moments will be compatible to those of their human interaction partners, which should much benefit natural human-robot collaboration.