 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman and Machine Action Prediction Independent of Object Information
Apr 22, 2020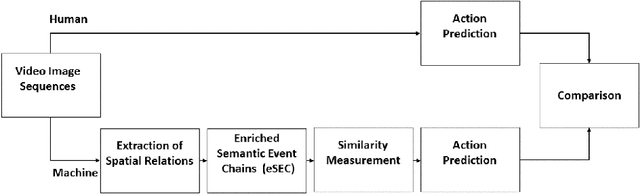
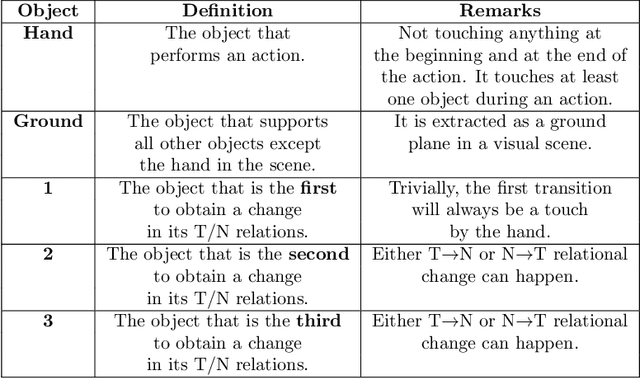

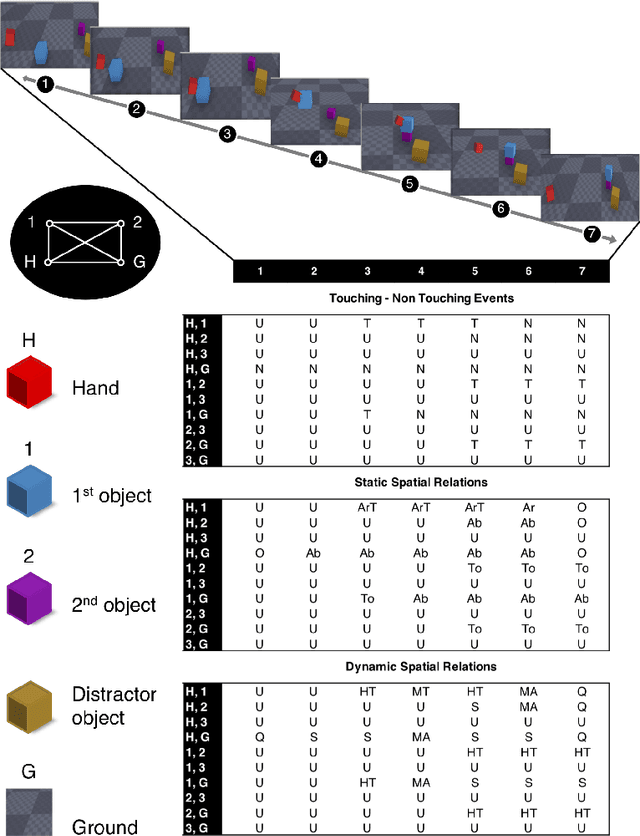
Predicting other people's action is key to successful social interactions, enabling us to adjust our own behavior to the consequence of the others' future actions. Studies on action recognition have focused on the importance of individual visual features of objects involved in an action and its context. Humans, however, recognize actions on unknown objects or even when objects are imagined (pantomime). Other cues must thus compensate the lack of recognizable visual object features. Here, we focus on the role of inter-object relations that change during an action. We designed a virtual reality setup and tested recognition speed for 10 different manipulation actions on 50 subjects. All objects were abstracted by emulated cubes so the actions could not be inferred using object information. Instead, subjects had to rely only on the information that comes from the changes in the spatial relations that occur between those cubes. In spite of these constraints, our results show the subjects were able to predict actions in, on average, less than 64% of the action's duration. We employed a computational model -an enriched Semantic Event Chain (eSEC)- incorporating the information of spatial relations, specifically (a) objects' touching/untouching, (b) static spatial relations between objects and (c) dynamic spatial relations between objects. Trained on the same actions as those observed by subjects, the model successfully predicted actions even better than humans. Information theoretical analysis shows that eSECs optimally use individual cues, whereas humans presumably mostly rely on a mixed-cue strategy, which takes longer until recognition. Providing a better cognitive basis of action recognition may, on one hand improve our understanding of related human pathologies and, on the other hand, also help to build robots for conflict-free human-robot cooperation. Our results open new avenues here.
Action Prediction in Humans and Robots
Jul 03, 2019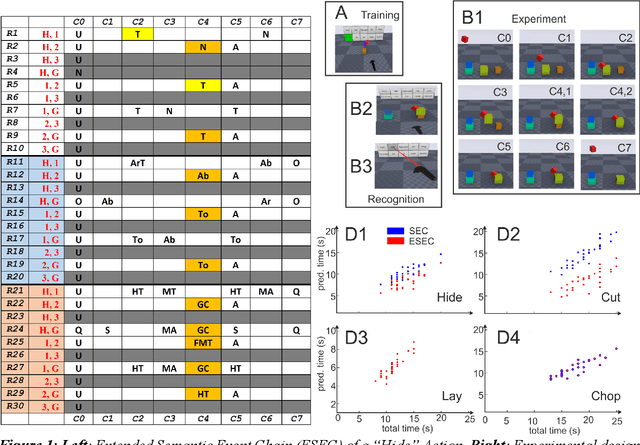
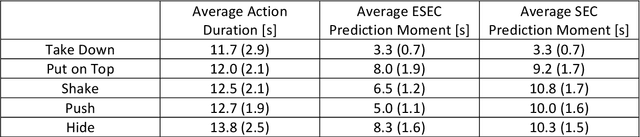
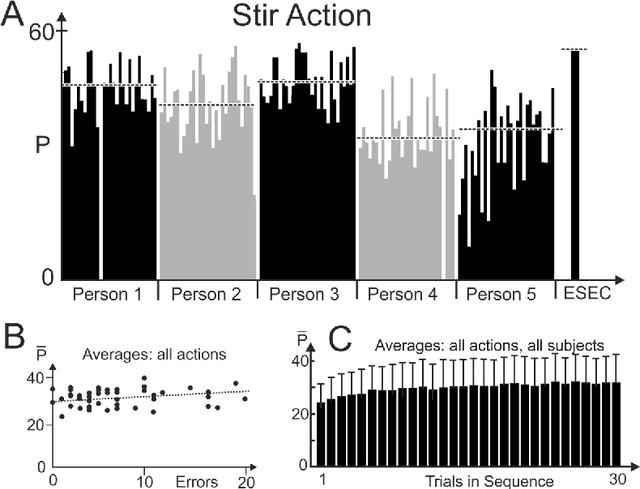
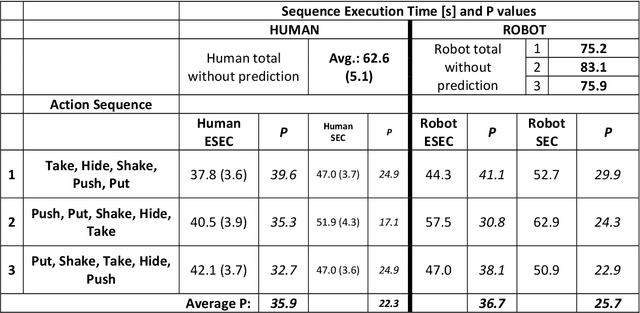
Efficient action prediction is of central importance for the fluent workflow between humans and equally so for human-robot interaction. To achieve prediction, actions can be encoded by a series of events, where every event corresponds to a change in a (static or dynamic) relation between some of the objects in a scene. Manipulation actions and others can be uniquely encoded this way and only, on average, less than 60% of the time series has to pass until an action can be predicted. Using a virtual reality setup and testing ten different manipulation actions, here we show that in most cases humans predict actions at the same event as the algorithm. In addition, we perform an in-depth analysis about the temporal gain resulting from such predictions when chaining actions and show in some robotic experiments that the percentage gain for humans and robots is approximately equal. Thus, if robots use this algorithm then their prediction-moments will be compatible to those of their human interaction partners, which should much benefit natural human-robot collaboration.