 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Sequences: A Benchmark for Atomic Hand-Object Interaction Using a Static RNN Encoder
Dec 10, 2025Reliably predicting human intent in hand-object interactions is an open challenge for computer vision. Our research concentrates on a fundamental sub-problem: the fine-grained classification of atomic interaction states, namely 'approaching', 'grabbing', and 'holding'. To this end, we introduce a structured data engineering process that converts raw videos from the MANIAC dataset into 27,476 statistical-kinematic feature vectors. Each vector encapsulates relational and dynamic properties from a short temporal window of motion. Our initial hypothesis posited that sequential modeling would be critical, leading us to compare static classifiers (MLPs) against temporal models (RNNs). Counter-intuitively, the key discovery occurred when we set the sequence length of a Bidirectional RNN to one (seq_length=1). This modification converted the network's function, compelling it to act as a high-capacity static feature encoder. This architectural change directly led to a significant accuracy improvement, culminating in a final score of 97.60%. Of particular note, our optimized model successfully overcame the most challenging transitional class, 'grabbing', by achieving a balanced F1-score of 0.90. These findings provide a new benchmark for low-level hand-object interaction recognition using structured, interpretable features and lightweight architectures.
Leveraging Foundation Models for Multimodal Graph-Based Action Recognition
May 21, 2025Foundation models have ushered in a new era for multimodal video understanding by enabling the extraction of rich spatiotemporal and semantic representations. In this work, we introduce a novel graph-based framework that integrates a vision-language foundation, leveraging VideoMAE for dynamic visual encoding and BERT for contextual textual embedding, to address the challenge of recognizing fine-grained bimanual manipulation actions. Departing from conventional static graph architectures, our approach constructs an adaptive multimodal graph where nodes represent frames, objects, and textual annotations, and edges encode spatial, temporal, and semantic relationships. These graph structures evolve dynamically based on learned interactions, allowing for flexible and context-aware reasoning. A task-specific attention mechanism within a Graph Attention Network further enhances this reasoning by modulating edge importance based on action semantics. Through extensive evaluations on diverse benchmark datasets, we demonstrate that our method consistently outperforms state-of-the-art baselines, underscoring the strength of combining foundation models with dynamic graph-based reasoning for robust and generalizable action recognition.
Multi Sentence Description of Complex Manipulation Action Videos
Nov 13, 2023



Automatic video description requires the generation of natural language statements about the actions, events, and objects in the video. An important human trait, when we describe a video, is that we are able to do this with variable levels of detail. Different from this, existing approaches for automatic video descriptions are mostly focused on single sentence generation at a fixed level of detail. Instead, here we address video description of manipulation actions where different levels of detail are required for being able to convey information about the hierarchical structure of these actions relevant also for modern approaches of robot learning. We propose one hybrid statistical and one end-to-end framework to address this problem. The hybrid method needs much less data for training, because it models statistically uncertainties within the video clips, while in the end-to-end method, which is more data-heavy, we are directly connecting the visual encoder to the language decoder without any intermediate (statistical) processing step. Both frameworks use LSTM stacks to allow for different levels of description granularity and videos can be described by simple single-sentences or complex multiple-sentence descriptions. In addition, quantitative results demonstrate that these methods produce more realistic descriptions than other competing approaches.
A Hierarchical Graph-based Approach for Recognition and Description Generation of Bimanual Actions in Videos
Oct 01, 2023



Nuanced understanding and the generation of detailed descriptive content for (bimanual) manipulation actions in videos is important for disciplines such as robotics, human-computer interaction, and video content analysis. This study describes a novel method, integrating graph based modeling with layered hierarchical attention mechanisms, resulting in higher precision and better comprehensiveness of video descriptions. To achieve this, we encode, first, the spatio-temporal inter dependencies between objects and actions with scene graphs and we combine this, in a second step, with a novel 3-level architecture creating a hierarchical attention mechanism using Graph Attention Networks (GATs). The 3-level GAT architecture allows recognizing local, but also global contextual elements. This way several descriptions with different semantic complexity can be generated in parallel for the same video clip, enhancing the discriminative accuracy of action recognition and action description. The performance of our approach is empirically tested using several 2D and 3D datasets. By comparing our method to the state of the art we consistently obtain better performance concerning accuracy, precision, and contextual relevance when evaluating action recognition as well as description generation. In a large set of ablation experiments we also assess the role of the different components of our model. With our multi-level approach the system obtains different semantic description depths, often observed in descriptions made by different people, too. Furthermore, better insight into bimanual hand-object interactions as achieved by our model may portend advancements in the field of robotics, enabling the emulation of intricate human actions with heightened precision.
Human and Machine Action Prediction Independent of Object Information
Apr 22, 2020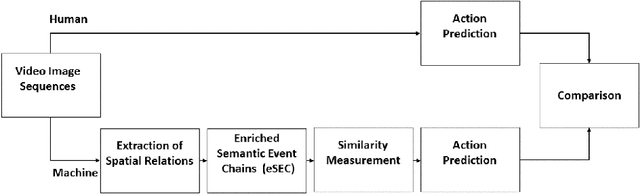
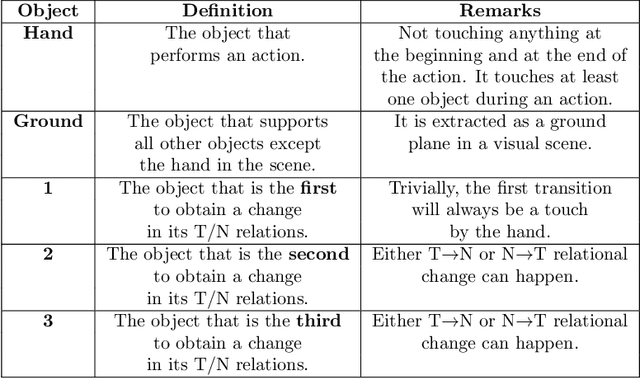

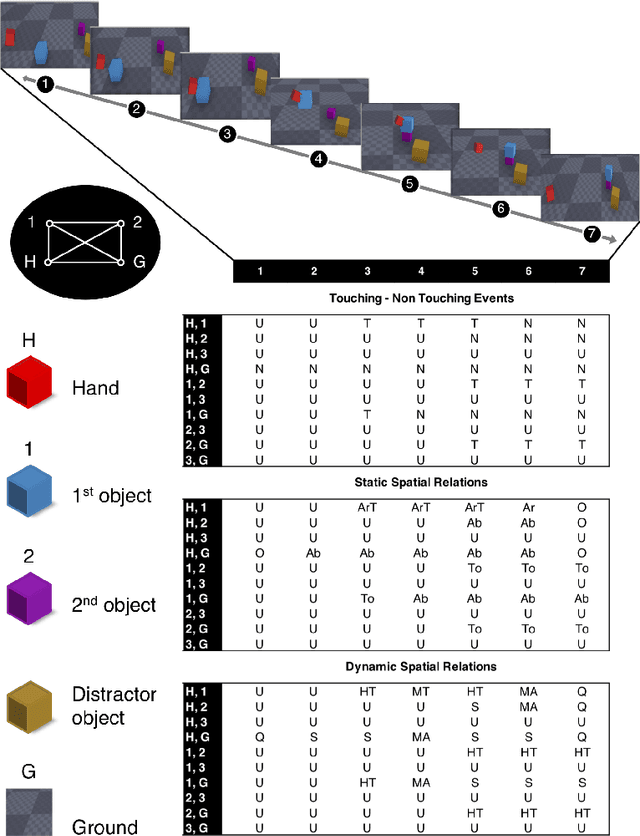
Predicting other people's action is key to successful social interactions, enabling us to adjust our own behavior to the consequence of the others' future actions. Studies on action recognition have focused on the importance of individual visual features of objects involved in an action and its context. Humans, however, recognize actions on unknown objects or even when objects are imagined (pantomime). Other cues must thus compensate the lack of recognizable visual object features. Here, we focus on the role of inter-object relations that change during an action. We designed a virtual reality setup and tested recognition speed for 10 different manipulation actions on 50 subjects. All objects were abstracted by emulated cubes so the actions could not be inferred using object information. Instead, subjects had to rely only on the information that comes from the changes in the spatial relations that occur between those cubes. In spite of these constraints, our results show the subjects were able to predict actions in, on average, less than 64% of the action's duration. We employed a computational model -an enriched Semantic Event Chain (eSEC)- incorporating the information of spatial relations, specifically (a) objects' touching/untouching, (b) static spatial relations between objects and (c) dynamic spatial relations between objects. Trained on the same actions as those observed by subjects, the model successfully predicted actions even better than humans. Information theoretical analysis shows that eSECs optimally use individual cues, whereas humans presumably mostly rely on a mixed-cue strategy, which takes longer until recognition. Providing a better cognitive basis of action recognition may, on one hand improve our understanding of related human pathologies and, on the other hand, also help to build robots for conflict-free human-robot cooperation. Our results open new avenues here.
Action Prediction in Humans and Robots
Jul 03, 2019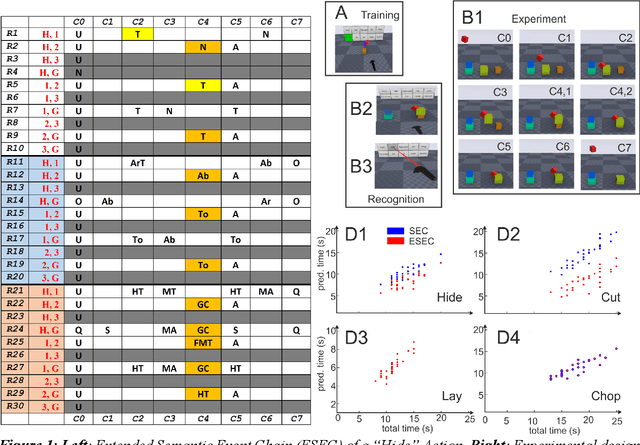
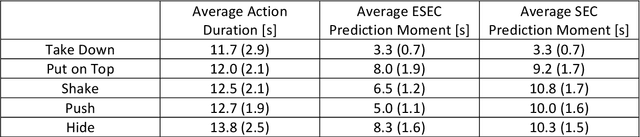
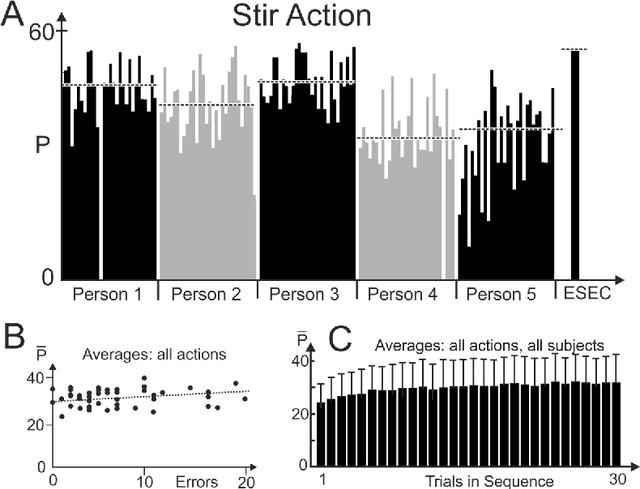
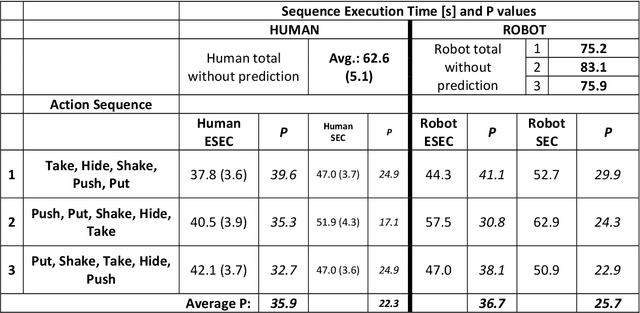
Efficient action prediction is of central importance for the fluent workflow between humans and equally so for human-robot interaction. To achieve prediction, actions can be encoded by a series of events, where every event corresponds to a change in a (static or dynamic) relation between some of the objects in a scene. Manipulation actions and others can be uniquely encoded this way and only, on average, less than 60% of the time series has to pass until an action can be predicted. Using a virtual reality setup and testing ten different manipulation actions, here we show that in most cases humans predict actions at the same event as the algorithm. In addition, we perform an in-depth analysis about the temporal gain resulting from such predictions when chaining actions and show in some robotic experiments that the percentage gain for humans and robots is approximately equal. Thus, if robots use this algorithm then their prediction-moments will be compatible to those of their human interaction partners, which should much benefit natural human-robot collaboration.