 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKoopman-based surrogate modeling for reinforcement-learning-control of Rayleigh-Benard convection
Mar 30, 2026Training reinforcement learning (RL) agents to control fluid dynamics systems is computationally expensive due to the high cost of direct numerical simulations (DNS) of the governing equations. Surrogate models offer a promising alternative by approximating the dynamics at a fraction of the computational cost, but their feasibility as training environments for RL is limited by distribution shifts, as policies induce state distributions not covered by the surrogate training data. In this work, we investigate the use of Linear Recurrent Autoencoder Networks (LRANs) for accelerating RL-based control of 2D Rayleigh-Bénard convection. We evaluate two training strategies: a surrogate trained on precomputed data generated with random actions, and a policy-aware surrogate trained iteratively using data collected from an evolving policy. Our results show that while surrogate-only training leads to reduced control performance, combining surrogates with DNS in a pretraining scheme recovers state-of-the-art performance while reducing training time by more than 40%. We demonstrate that policy-aware training mitigates the effects of distribution shift, enabling more accurate predictions in policy-relevant regions of the state space.
Automatic feature identification in least-squares policy iteration using the Koopman operator framework
Mar 27, 2026In this paper, we present a Koopman autoencoder-based least-squares policy iteration (KAE-LSPI) algorithm in reinforcement learning (RL). The KAE-LSPI algorithm is based on reformulating the so-called least-squares fixed-point approximation method in terms of extended dynamic mode decomposition (EDMD), thereby enabling automatic feature learning via the Koopman autoencoder (KAE) framework. The approach is motivated by the lack of a systematic choice of features or kernels in linear RL techniques. We compare the KAE-LSPI algorithm with two previous works, the classical least-squares policy iteration (LSPI) and the kernel-based least-squares policy iteration (KLSPI), using stochastic chain walk and inverted pendulum control problems as examples. Unlike previous works, no features or kernels need to be fixed a priori in our approach. Empirical results show the number of features learned by the KAE technique remains reasonable compared to those fixed in the classical LSPI algorithm. The convergence to an optimal or a near-optimal policy is also comparable to the other two methods.
Plug-and-Play Benchmarking of Reinforcement Learning Algorithms for Large-Scale Flow Control
Jan 21, 2026Reinforcement learning (RL) has shown promising results in active flow control (AFC), yet progress in the field remains difficult to assess as existing studies rely on heterogeneous observation and actuation schemes, numerical setups, and evaluation protocols. Current AFC benchmarks attempt to address these issues but heavily rely on external computational fluid dynamics (CFD) solvers, are not fully differentiable, and provide limited 3D and multi-agent support. To overcome these limitations, we introduce FluidGym, the first standalone, fully differentiable benchmark suite for RL in AFC. Built entirely in PyTorch on top of the GPU-accelerated PICT solver, FluidGym runs in a single Python stack, requires no external CFD software, and provides standardized evaluation protocols. We present baseline results with PPO and SAC and release all environments, datasets, and trained models as public resources. FluidGym enables systematic comparison of control methods, establishes a scalable foundation for future research in learning-based flow control, and is available at https://github.com/safe-autonomous-systems/fluidgym.
Efficient probabilistic surrogate modeling techniques for partially-observed large-scale dynamical systems
Nov 06, 2025This paper is concerned with probabilistic techniques for forecasting dynamical systems described by partial differential equations (such as, for example, the Navier-Stokes equations). In particular, it is investigating and comparing various extensions to the flow matching paradigm that reduce the number of sampling steps. In this regard, it compares direct distillation, progressive distillation, adversarial diffusion distillation, Wasserstein GANs and rectified flows. Moreover, experiments are conducted on a set of challenging systems. In particular, we also address the challenge of directly predicting 2D slices of large-scale 3D simulations, paving the way for efficient inflow generation for solvers.
Bayesian Transfer Operators in Reproducing Kernel Hilbert Spaces
Sep 26, 2025The Koopman operator, as a linear representation of a nonlinear dynamical system, has been attracting attention in many fields of science. Recently, Koopman operator theory has been combined with another concept that is popular in data science: reproducing kernel Hilbert spaces. We follow this thread into Gaussian process methods, and illustrate how these methods can alleviate two pervasive problems with kernel-based Koopman algorithms. The first being sparsity: most kernel methods do not scale well and require an approximation to become practical. We show that not only can the computational demands be reduced, but also demonstrate improved resilience against sensor noise. The second problem involves hyperparameter optimization and dictionary learning to adapt the model to the dynamical system. In summary, the main contribution of this work is the unification of Gaussian process regression and dynamic mode decomposition.
Surrogate Modeling of 3D Rayleigh-Benard Convection with Equivariant Autoencoders
May 19, 2025



The use of machine learning for modeling, understanding, and controlling large-scale physics systems is quickly gaining in popularity, with examples ranging from electromagnetism over nuclear fusion reactors and magneto-hydrodynamics to fluid mechanics and climate modeling. These systems -- governed by partial differential equations -- present unique challenges regarding the large number of degrees of freedom and the complex dynamics over many scales both in space and time, and additional measures to improve accuracy and sample efficiency are highly desirable. We present an end-to-end equivariant surrogate model consisting of an equivariant convolutional autoencoder and an equivariant convolutional LSTM using $G$-steerable kernels. As a case study, we consider the three-dimensional Rayleigh-B\'enard convection, which describes the buoyancy-driven fluid flow between a heated bottom and a cooled top plate. While the system is E(2)-equivariant in the horizontal plane, the boundary conditions break the translational equivariance in the vertical direction. Our architecture leverages vertically stacked layers of $D_4$-steerable kernels, with additional partial kernel sharing in the vertical direction for further efficiency improvement. Our results demonstrate significant gains both in sample and parameter efficiency, as well as a better scaling to more complex dynamics, that is, larger Rayleigh numbers. The accompanying code is available under https://github.com/FynnFromme/equivariant-rb-forecasting.
Control of Rayleigh-Bénard Convection: Effectiveness of Reinforcement Learning in the Turbulent Regime
Apr 16, 2025



Data-driven flow control has significant potential for industry, energy systems, and climate science. In this work, we study the effectiveness of Reinforcement Learning (RL) for reducing convective heat transfer in the 2D Rayleigh-B\'enard Convection (RBC) system under increasing turbulence. We investigate the generalizability of control across varying initial conditions and turbulence levels and introduce a reward shaping technique to accelerate the training. RL agents trained via single-agent Proximal Policy Optimization (PPO) are compared to linear proportional derivative (PD) controllers from classical control theory. The RL agents reduced convection, measured by the Nusselt Number, by up to 33% in moderately turbulent systems and 10% in highly turbulent settings, clearly outperforming PD control in all settings. The agents showed strong generalization performance across different initial conditions and to a significant extent, generalized to higher degrees of turbulence. The reward shaping improved sample efficiency and consistently stabilized the Nusselt Number to higher turbulence levels.
Surrogate-assisted multi-objective design of complex multibody systems
Dec 19, 2024



The optimization of large-scale multibody systems is a numerically challenging task, in particular when considering multiple conflicting criteria at the same time. In this situation, we need to approximate the Pareto set of optimal compromises, which is significantly more expensive than finding a single optimum in single-objective optimization. To prevent large costs, the usage of surrogate models, constructed from a small but informative number of expensive model evaluations, is a very popular and widely studied approach. The central challenge then is to ensure a high quality (that is, near-optimality) of the solutions that were obtained using the surrogate model, which can be hard to guarantee with a single pre-computed surrogate. We present a back-and-forth approach between surrogate modeling and multi-objective optimization to improve the quality of the obtained solutions. Using the example of an expensive-to-evaluate multibody system, we compare different strategies regarding multi-objective optimization, sampling and also surrogate modeling, to identify the most promising approach in terms of computational efficiency and solution quality.
The impact of AI on engineering design procedures for dynamical systems
Dec 16, 2024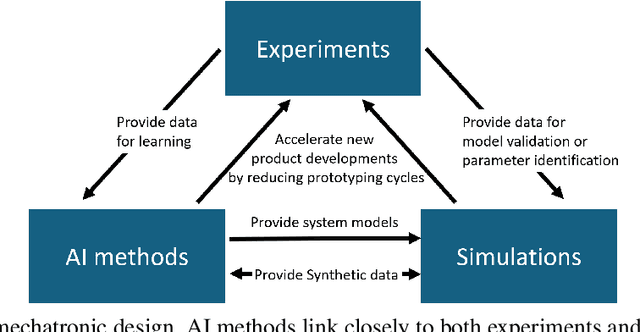



Artificial intelligence (AI) is driving transformative changes across numerous fields, revolutionizing conventional processes and creating new opportunities for innovation. The development of mechatronic systems is undergoing a similar transformation. Over the past decade, modeling, simulation, and optimization techniques have become integral to the design process, paving the way for the adoption of AI-based methods. In this paper, we examine the potential for integrating AI into the engineering design process, using the V-model from the VDI guideline 2206, considered the state-of-the-art in product design, as a foundation. We identify and classify AI methods based on their suitability for specific stages within the engineering product design workflow. Furthermore, we present a series of application examples where AI-assisted design has been successfully implemented by the authors. These examples, drawn from research projects within the DFG Priority Program \emph{SPP~2353: Daring More Intelligence - Design Assistants in Mechanics and Dynamics}, showcase a diverse range of applications across mechanics and mechatronics, including areas such as acoustics and robotics.
Multi-objective Deep Learning: Taxonomy and Survey of the State of the Art
Dec 03, 2024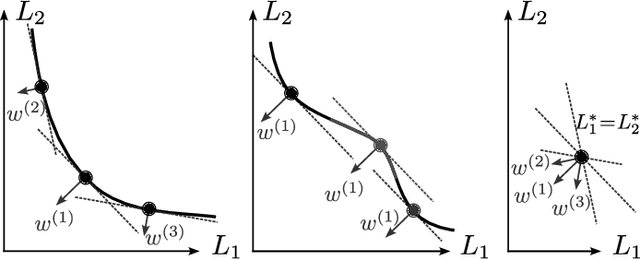
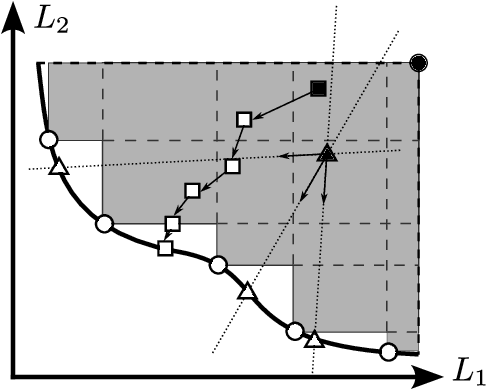
Simultaneously considering multiple objectives in machine learning has been a popular approach for several decades, with various benefits for multi-task learning, the consideration of secondary goals such as sparsity, or multicriteria hyperparameter tuning. However - as multi-objective optimization is significantly more costly than single-objective optimization - the recent focus on deep learning architectures poses considerable additional challenges due to the very large number of parameters, strong nonlinearities and stochasticity. This survey covers recent advancements in the area of multi-objective deep learning. We introduce a taxonomy of existing methods - based on the type of training algorithm as well as the decision maker's needs - before listing recent advancements, and also successful applications. All three main learning paradigms supervised learning, unsupervised learning and reinforcement learning are covered, and we also address the recently very popular area of generative modeling.