 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-objective Deep Learning: Taxonomy and Survey of the State of the Art
Dec 03, 2024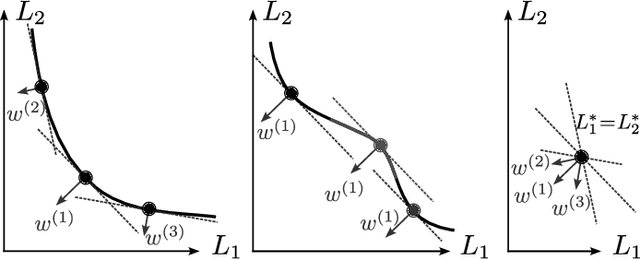
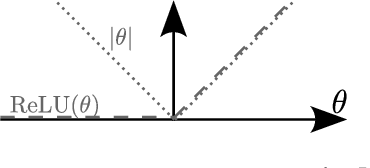
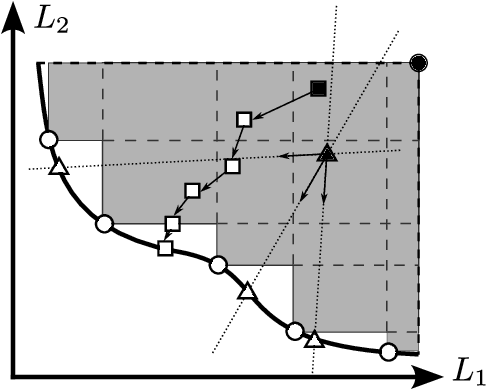
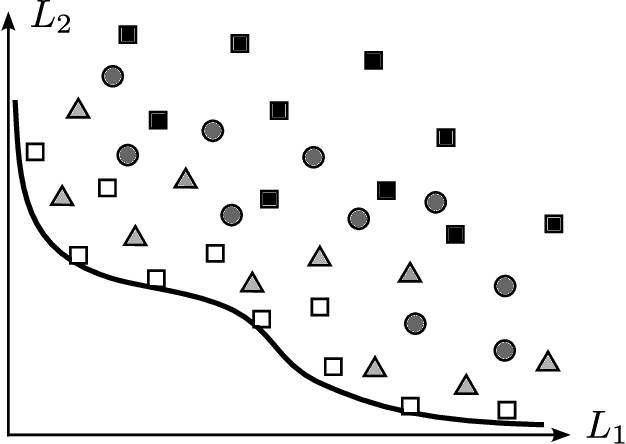
Simultaneously considering multiple objectives in machine learning has been a popular approach for several decades, with various benefits for multi-task learning, the consideration of secondary goals such as sparsity, or multicriteria hyperparameter tuning. However - as multi-objective optimization is significantly more costly than single-objective optimization - the recent focus on deep learning architectures poses considerable additional challenges due to the very large number of parameters, strong nonlinearities and stochasticity. This survey covers recent advancements in the area of multi-objective deep learning. We introduce a taxonomy of existing methods - based on the type of training algorithm as well as the decision maker's needs - before listing recent advancements, and also successful applications. All three main learning paradigms supervised learning, unsupervised learning and reinforcement learning are covered, and we also address the recently very popular area of generative modeling.
MOREL: Enhancing Adversarial Robustness through Multi-Objective Representation Learning
Oct 02, 2024Extensive research has shown that deep neural networks (DNNs) are vulnerable to slight adversarial perturbations$-$small changes to the input data that appear insignificant but cause the model to produce drastically different outputs. In addition to augmenting training data with adversarial examples generated from a specific attack method, most of the current defense strategies necessitate modifying the original model architecture components to improve robustness or performing test-time data purification to handle adversarial attacks. In this work, we demonstrate that strong feature representation learning during training can significantly enhance the original model's robustness. We propose MOREL, a multi-objective feature representation learning approach, encouraging classification models to produce similar features for inputs within the same class, despite perturbations. Our training method involves an embedding space where cosine similarity loss and multi-positive contrastive loss are used to align natural and adversarial features from the model encoder and ensure tight clustering. Concurrently, the classifier is motivated to achieve accurate predictions. Through extensive experiments, we demonstrate that our approach significantly enhances the robustness of DNNs against white-box and black-box adversarial attacks, outperforming other methods that similarly require no architectural changes or test-time data purification. Our code is available at https://github.com/salomonhotegni/MOREL