 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing Decision Tree as Local Interpretable Model in Autoencoder-based LIME
Paper and Code
Apr 07, 2022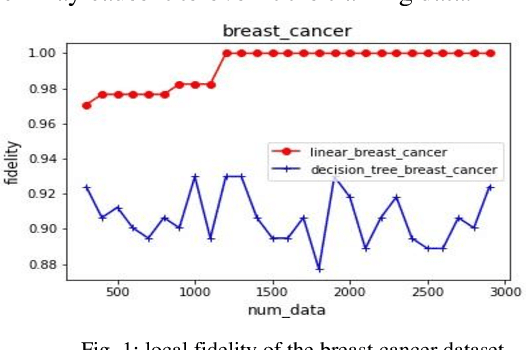
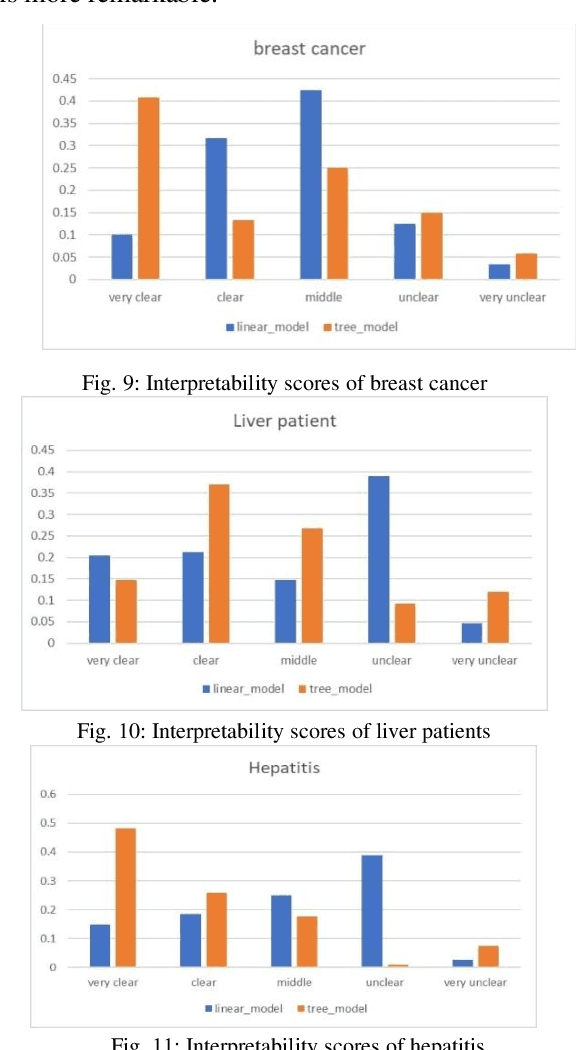
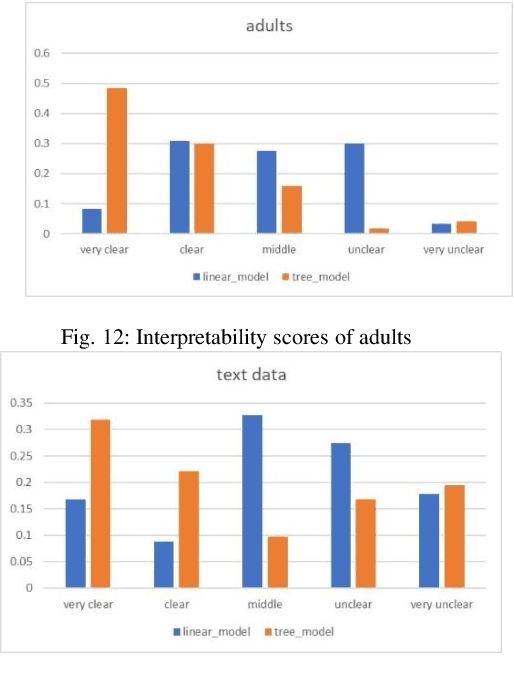
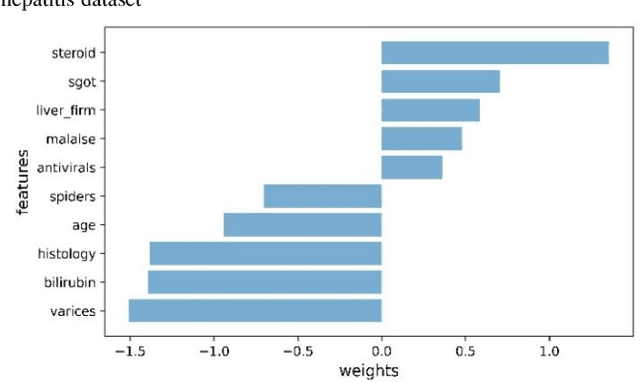
Nowadays, deep neural networks are being used in many domains because of their high accuracy results. However, they are considered as "black box", means that they are not explainable for humans. On the other hand, in some tasks such as medical, economic, and self-driving cars, users want the model to be interpretable to decide if they can trust these results or not. In this work, we present a modified version of an autoencoder-based approach for local interpretability called ALIME. The ALIME itself is inspired by a famous method called Local Interpretable Model-agnostic Explanations (LIME). LIME generates a single instance level explanation by generating new data around the instance and training a local linear interpretable model. ALIME uses an autoencoder to weigh the new data around the sample. Nevertheless, the ALIME uses a linear model as the interpretable model to be trained locally, just like the LIME. This work proposes a new approach, which uses a decision tree instead of the linear model, as the interpretable model. We evaluate the proposed model in case of stability, local fidelity, and interpretability on different datasets. Compared to ALIME, the experiments show significant results on stability and local fidelity and improved results on interpretability.