Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePQuAD: A Persian Question Answering Dataset
Paper and Code
Feb 13, 2022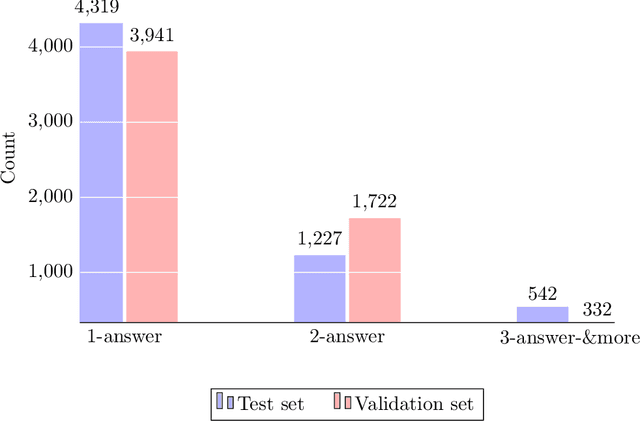
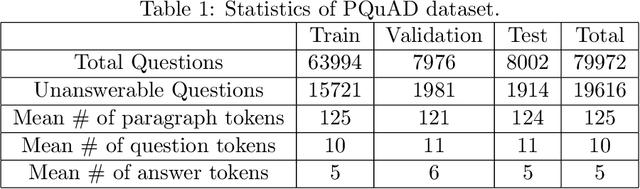
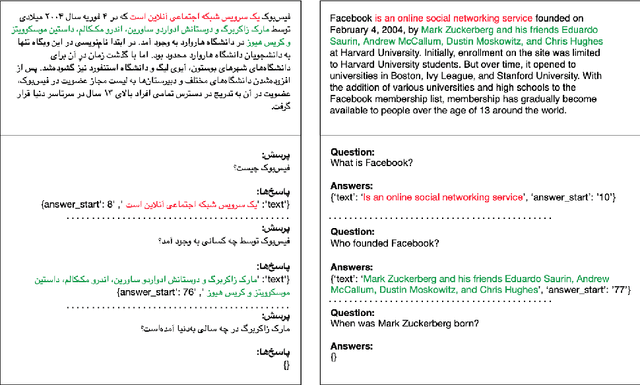
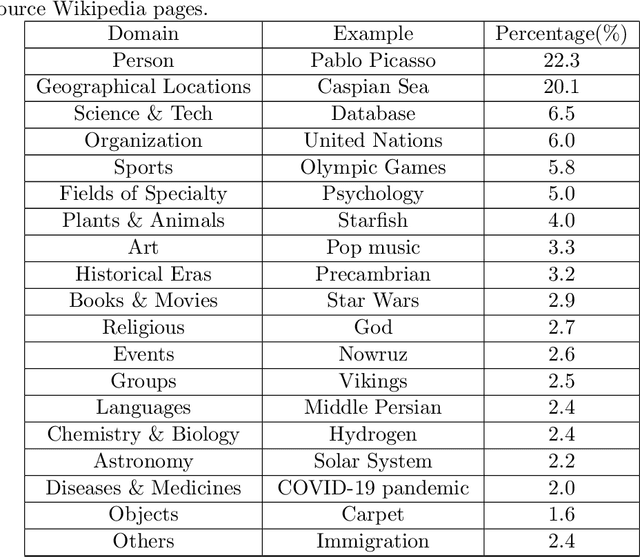
We present Persian Question Answering Dataset (PQuAD), a crowdsourced reading comprehension dataset on Persian Wikipedia articles. It includes 80,000 questions along with their answers, with 25% of the questions being adversarially unanswerable. We examine various properties of the dataset to show the diversity and the level of its difficulty as an MRC benchmark. By releasing this dataset, we aim to ease research on Persian reading comprehension and development of Persian question answering systems. Our experiments on different state-of-the-art pre-trained contextualized language models show 74.8% Exact Match (EM) and 87.6% F1-score that can be used as the baseline results for further research on Persian QA.
View paper on