 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient data selection employing Semantic Similarity-based Graph Structures for model training
Paper and Code
Feb 22, 2024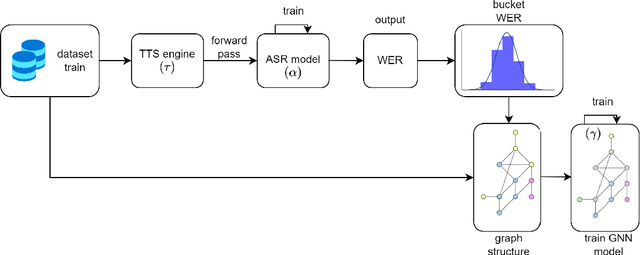
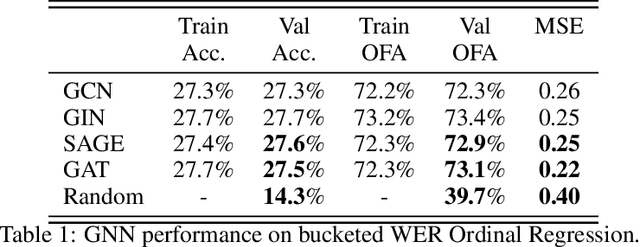
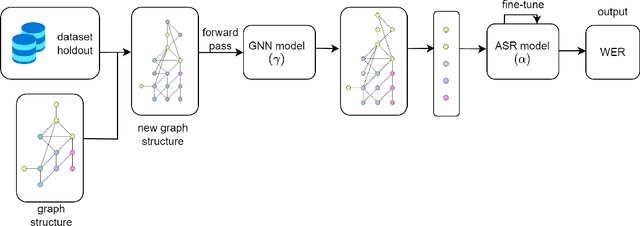
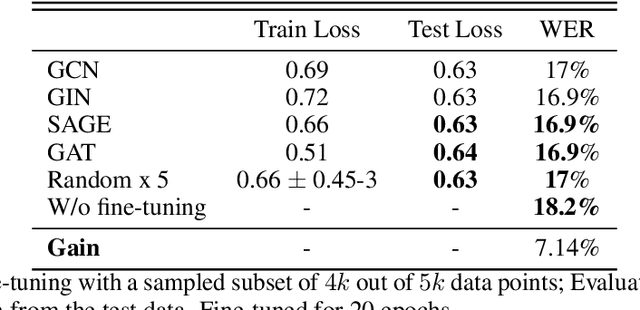
Recent developments in natural language processing (NLP) have highlighted the need for substantial amounts of data for models to capture textual information accurately. This raises concerns regarding the computational resources and time required for training such models. This paper introduces Semantics for data SAliency in Model performance Estimation (SeSaME). It is an efficient data sampling mechanism solely based on textual information without passing the data through a compute-heavy model or other intensive pre-processing transformations. The application of this approach is demonstrated in the use case of low-resource automated speech recognition (ASR) models, which excessively rely on text-to-speech (TTS) calls when using augmented data. SeSaME learns to categorize new incoming data points into speech recognition difficulty buckets by employing semantic similarity-based graph structures and discrete ASR information from homophilous neighbourhoods through message passing. The results indicate reliable projections of ASR performance, with a 93% accuracy increase when using the proposed method compared to random predictions, bringing non-trivial information on the impact of textual representations in speech models. Furthermore, a series of experiments show both the benefits and challenges of using the ASR information on incoming data to fine-tune the model. We report a 7% drop in validation loss compared to random sampling, 7% WER drop with non-local aggregation when evaluating against a highly difficult dataset, and 1.8% WER drop with local aggregation and high semantic similarity between datasets.