 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeexHarmony: Authorship and Citations for Benchmarking the Reviewer Assignment Problem
Feb 11, 2025



The peer review process is crucial for ensuring the quality and reliability of scholarly work, yet assigning suitable reviewers remains a significant challenge. Traditional manual methods are labor-intensive and often ineffective, leading to nonconstructive or biased reviews. This paper introduces the exHarmony (eHarmony but for connecting experts to manuscripts) benchmark, designed to address these challenges by re-imagining the Reviewer Assignment Problem (RAP) as a retrieval task. Utilizing the extensive data from OpenAlex, we propose a novel approach that considers a host of signals from the authors, most similar experts, and the citation relations as potential indicators for a suitable reviewer for a manuscript. This approach allows us to develop a standard benchmark dataset for evaluating the reviewer assignment problem without needing explicit labels. We benchmark various methods, including traditional lexical matching, static neural embeddings, and contextualized neural embeddings, and introduce evaluation metrics that assess both relevance and diversity in the context of RAP. Our results indicate that while traditional methods perform reasonably well, contextualized embeddings trained on scholarly literature show the best performance. The findings underscore the importance of further research to enhance the diversity and effectiveness of reviewer assignments.
Benchmarking Prompt Sensitivity in Large Language Models
Feb 09, 2025
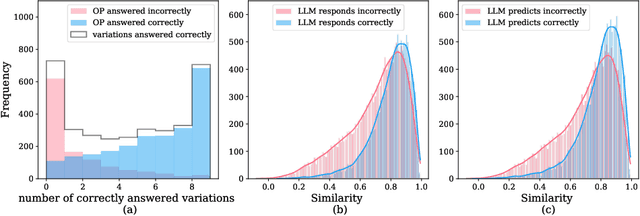
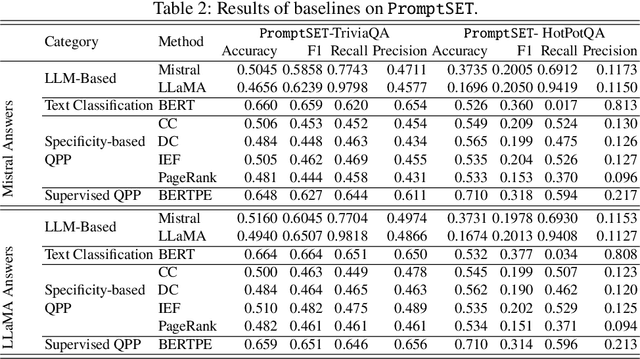
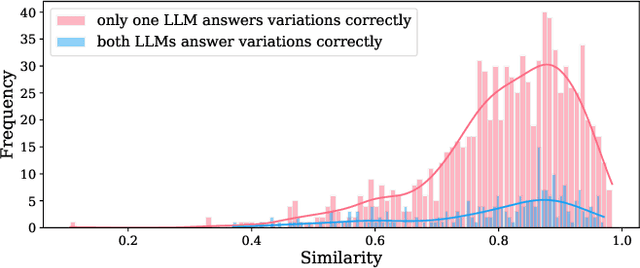
Large language Models (LLMs) are highly sensitive to variations in prompt formulation, which can significantly impact their ability to generate accurate responses. In this paper, we introduce a new task, Prompt Sensitivity Prediction, and a dataset PromptSET designed to investigate the effects of slight prompt variations on LLM performance. Using TriviaQA and HotpotQA datasets as the foundation of our work, we generate prompt variations and evaluate their effectiveness across multiple LLMs. We benchmark the prompt sensitivity prediction task employing state-of-the-art methods from related tasks, including LLM-based self-evaluation, text classification, and query performance prediction techniques. Our findings reveal that existing methods struggle to effectively address prompt sensitivity prediction, underscoring the need to understand how information needs should be phrased for accurate LLM responses.
Text Representation Enrichment Utilizing Graph based Approaches: Stock Market Technical Analysis Case Study
Nov 29, 2022
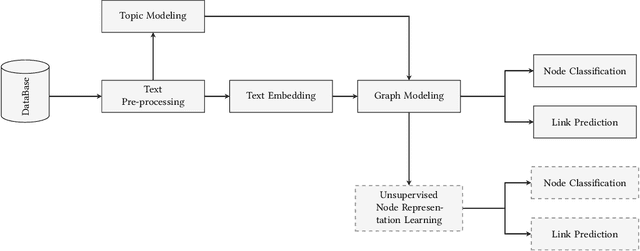


Graph neural networks (GNNs) have been utilized for various natural language processing (NLP) tasks lately. The ability to encode corpus-wide features in graph representation made GNN models popular in various tasks such as document classification. One major shortcoming of such models is that they mainly work on homogeneous graphs, while representing text datasets as graphs requires several node types which leads to a heterogeneous schema. In this paper, we propose a transductive hybrid approach composed of an unsupervised node representation learning model followed by a node classification/edge prediction model. The proposed model is capable of processing heterogeneous graphs to produce unified node embeddings which are then utilized for node classification or link prediction as the downstream task. The proposed model is developed to classify stock market technical analysis reports, which to our knowledge is the first work in this domain. Experiments, which are carried away using a constructed dataset, demonstrate the ability of the model in embedding extraction and the downstream tasks.