 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking Prompt Sensitivity in Large Language Models
Paper and Code

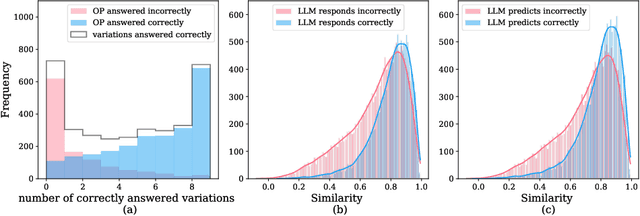
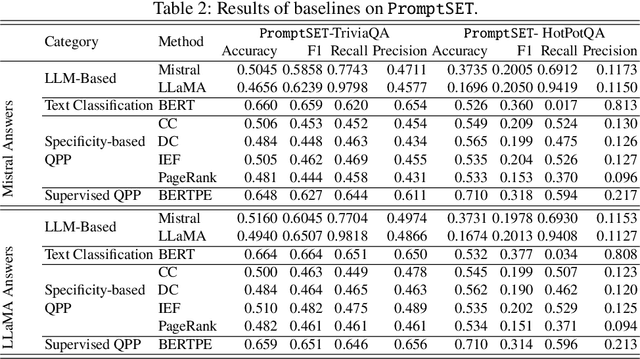
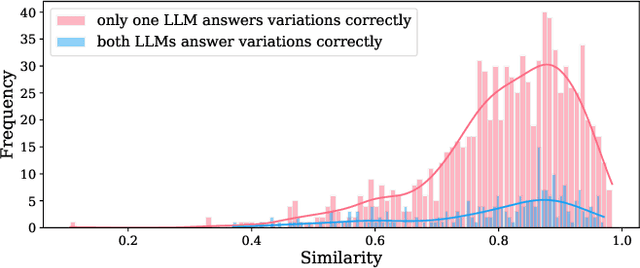
Large language Models (LLMs) are highly sensitive to variations in prompt formulation, which can significantly impact their ability to generate accurate responses. In this paper, we introduce a new task, Prompt Sensitivity Prediction, and a dataset PromptSET designed to investigate the effects of slight prompt variations on LLM performance. Using TriviaQA and HotpotQA datasets as the foundation of our work, we generate prompt variations and evaluate their effectiveness across multiple LLMs. We benchmark the prompt sensitivity prediction task employing state-of-the-art methods from related tasks, including LLM-based self-evaluation, text classification, and query performance prediction techniques. Our findings reveal that existing methods struggle to effectively address prompt sensitivity prediction, underscoring the need to understand how information needs should be phrased for accurate LLM responses.