 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman Preferences as Dueling Bandits
Paper and Code

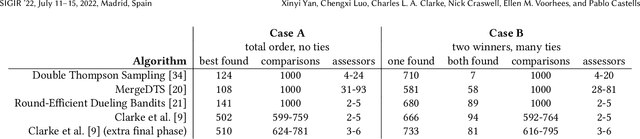
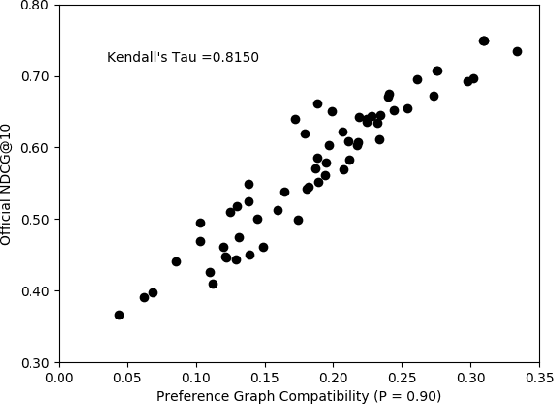
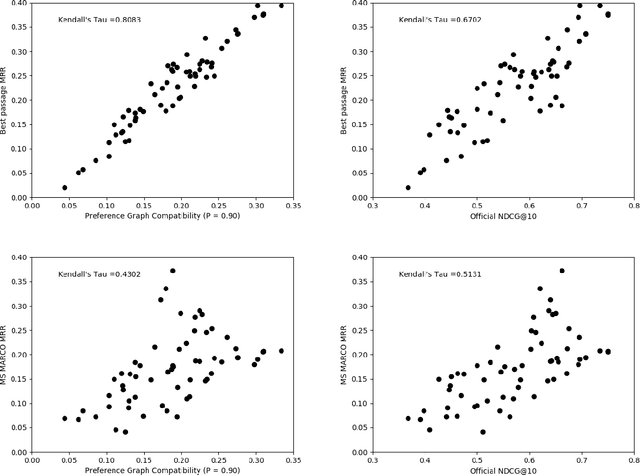
The dramatic improvements in core information retrieval tasks engendered by neural rankers create a need for novel evaluation methods. If every ranker returns highly relevant items in the top ranks, it becomes difficult to recognize meaningful differences between them and to build reusable test collections. Several recent papers explore pairwise preference judgments as an alternative to traditional graded relevance assessments. Rather than viewing items one at a time, assessors view items side-by-side and indicate the one that provides the better response to a query, allowing fine-grained distinctions. If we employ preference judgments to identify the probably best items for each query, we can measure rankers by their ability to place these items as high as possible. We frame the problem of finding best items as a dueling bandits problem. While many papers explore dueling bandits for online ranker evaluation via interleaving, they have not been considered as a framework for offline evaluation via human preference judgments. We review the literature for possible solutions. For human preference judgments, any usable algorithm must tolerate ties, since two items may appear nearly equal to assessors, and it must minimize the number of judgments required for any specific pair, since each such comparison requires an independent assessor. Since the theoretical guarantees provided by most algorithms depend on assumptions that are not satisfied by human preference judgments, we simulate selected algorithms on representative test cases to provide insight into their practical utility. Based on these simulations, one algorithm stands out for its potential. Our simulations suggest modifications to further improve its performance. Using the modified algorithm, we collect over 10,000 preference judgments for submissions to the TREC 2021 Deep Learning Track, confirming its suitability.