 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProjFlow: Projection Sampling with Flow Matching for Zero-Shot Exact Spatial Motion Control
Feb 26, 2026Generating human motion with precise spatial control is a challenging problem. Existing approaches often require task-specific training or slow optimization, and enforcing hard constraints frequently disrupts motion naturalness. Building on the observation that many animation tasks can be formulated as a linear inverse problem, we introduce ProjFlow, a training-free sampler that achieves zero-shot, exact satisfaction of linear spatial constraints while preserving motion realism. Our key advance is a novel kinematics-aware metric that encodes skeletal topology. This metric allows the sampler to enforce hard constraints by distributing corrections coherently across the entire skeleton, avoiding the unnatural artifacts of naive projection. Furthermore, for sparse inputs, such as filling in long gaps between a few keyframes, we introduce a time-varying formulation using pseudo-observations that fade during sampling. Extensive experiments on representative applications, motion inpainting, and 2D-to-3D lifting, demonstrate that ProjFlow achieves exact constraint satisfaction and matches or improves realism over zero-shot baselines, while remaining competitive with training-based controllers.
Causal Motion Diffusion Models for Autoregressive Motion Generation
Feb 26, 2026Recent advances in motion diffusion models have substantially improved the realism of human motion synthesis. However, existing approaches either rely on full-sequence diffusion models with bidirectional generation, which limits temporal causality and real-time applicability, or autoregressive models that suffer from instability and cumulative errors. In this work, we present Causal Motion Diffusion Models (CMDM), a unified framework for autoregressive motion generation based on a causal diffusion transformer that operates in a semantically aligned latent space. CMDM builds upon a Motion-Language-Aligned Causal VAE (MAC-VAE), which encodes motion sequences into temporally causal latent representations. On top of this latent representation, an autoregressive diffusion transformer is trained using causal diffusion forcing to perform temporally ordered denoising across motion frames. To achieve fast inference, we introduce a frame-wise sampling schedule with causal uncertainty, where each subsequent frame is predicted from partially denoised previous frames. The resulting framework supports high-quality text-to-motion generation, streaming synthesis, and long-horizon motion generation at interactive rates. Experiments on HumanML3D and SnapMoGen demonstrate that CMDM outperforms existing diffusion and autoregressive models in both semantic fidelity and temporal smoothness, while substantially reducing inference latency.
Open-Domain Dialogue Quality Evaluation: Deriving Nugget-level Scores from Turn-level Scores
Sep 30, 2023



Existing dialogue quality evaluation systems can return a score for a given system turn from a particular viewpoint, e.g., engagingness. However, to improve dialogue systems by locating exactly where in a system turn potential problems lie, a more fine-grained evaluation may be necessary. We therefore propose an evaluation approach where a turn is decomposed into nuggets (i.e., expressions associated with a dialogue act), and nugget-level evaluation is enabled by leveraging an existing turn-level evaluation system. We demonstrate the potential effectiveness of our evaluation method through a case study.
Constrained Generalized Additive 2 Model with Consideration of High-Order Interactions
Jun 05, 2021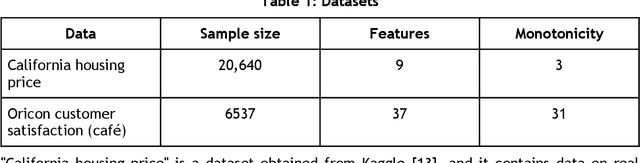
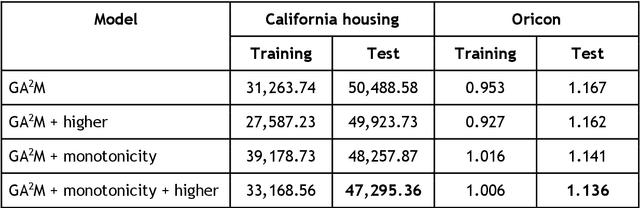
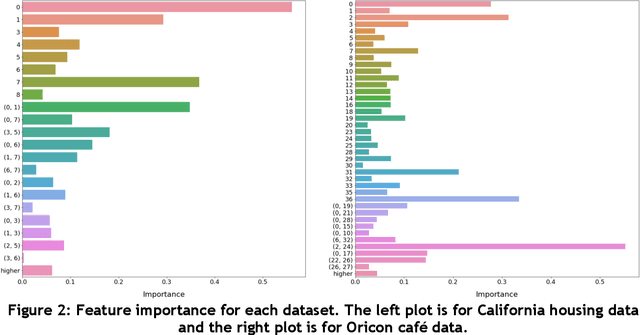
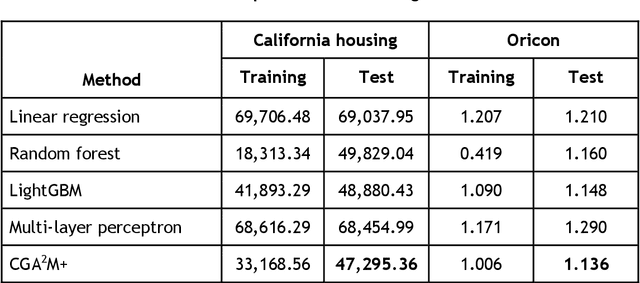
In recent years, machine learning and AI have been introduced in many industrial fields. In fields such as finance, medicine, and autonomous driving, where the inference results of a model may have serious consequences, high interpretability as well as prediction accuracy is required. In this study, we propose CGA2M+, which is based on the Generalized Additive 2 Model (GA2M) and differs from it in two major ways. The first is the introduction of monotonicity. Imposing monotonicity on some functions based on an analyst's knowledge is expected to improve not only interpretability but also generalization performance. The second is the introduction of a higher-order term: given that GA2M considers only second-order interactions, we aim to balance interpretability and prediction accuracy by introducing a higher-order term that can capture higher-order interactions. In this way, we can improve prediction performance without compromising interpretability by applying learning innovation. Numerical experiments showed that the proposed model has high predictive performance and interpretability. Furthermore, we confirmed that generalization performance is improved by introducing monotonicity.