 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContent-Aware Ad Banner Layout Generation with Two-Stage Chain-of-Thought in Vision Language Models
Dec 14, 2025In this paper, we propose a method for generating layouts for image-based advertisements by leveraging a Vision-Language Model (VLM). Conventional advertisement layout techniques have predominantly relied on saliency mapping to detect salient regions within a background image, but such approaches often fail to fully account for the image's detailed composition and semantic content. To overcome this limitation, our method harnesses a VLM to recognize the products and other elements depicted in the background and to inform the placement of text and logos. The proposed layout-generation pipeline consists of two steps. In the first step, the VLM analyzes the image to identify object types and their spatial relationships, then produces a text-based "placement plan" based on this analysis. In the second step, that plan is rendered into the final layout by generating HTML-format code. We validated the effectiveness of our approach through evaluation experiments, conducting both quantitative and qualitative comparisons against existing methods. The results demonstrate that by explicitly considering the background image's content, our method produces noticeably higher-quality advertisement layouts.
Interior-Point Vanishing Problem in Semidefinite Relaxations for Neural Network Verification
Jun 12, 2025Semidefinite programming (SDP) relaxation has emerged as a promising approach for neural network verification, offering tighter bounds than other convex relaxation methods for deep neural networks (DNNs) with ReLU activations. However, we identify a critical limitation in the SDP relaxation when applied to deep networks: interior-point vanishing, which leads to the loss of strict feasibility -- a crucial condition for the numerical stability and optimality of SDP. Through rigorous theoretical and empirical analysis, we demonstrate that as the depth of DNNs increases, the strict feasibility is likely to be lost, creating a fundamental barrier to scaling SDP-based verification. To address the interior-point vanishing, we design and investigate five solutions to enhance the feasibility conditions of the verification problem. Our methods can successfully solve 88% of the problems that could not be solved by existing methods, accounting for 41% of the total. Our analysis also reveals that the valid constraints for the lower and upper bounds for each ReLU unit are traditionally inherited from prior work without solid reasons, but are actually not only unbeneficial but also even harmful to the problem's feasibility. This work provides valuable insights into the fundamental challenges of SDP-based DNN verification and offers practical solutions to improve its applicability to deeper neural networks, contributing to the development of more reliable and secure systems with DNNs.
Towards Assessing and Benchmarking Risk-Return Tradeoff of Off-Policy Evaluation
Dec 04, 2023
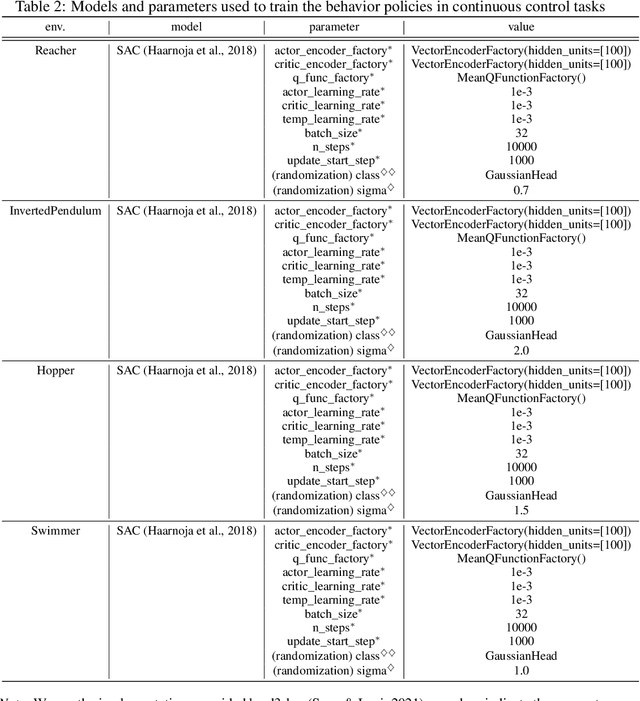
Off-Policy Evaluation (OPE) aims to assess the effectiveness of counterfactual policies using only offline logged data and is often used to identify the top-k promising policies for deployment in online A/B tests. Existing evaluation metrics for OPE estimators primarily focus on the "accuracy" of OPE or that of downstream policy selection, neglecting risk-return tradeoff in the subsequent online policy deployment. To address this issue, we draw inspiration from portfolio evaluation in finance and develop a new metric, called SharpeRatio@k, which measures the risk-return tradeoff of policy portfolios formed by an OPE estimator under varying online evaluation budgets (k). We validate our metric in two example scenarios, demonstrating its ability to effectively distinguish between low-risk and high-risk estimators and to accurately identify the most efficient estimator. This efficient estimator is characterized by its capability to form the most advantageous policy portfolios, maximizing returns while minimizing risks during online deployment, a nuance that existing metrics typically overlook. To facilitate a quick, accurate, and consistent evaluation of OPE via SharpeRatio@k, we have also integrated this metric into an open-source software, SCOPE-RL. Employing SharpeRatio@k and SCOPE-RL, we conduct comprehensive benchmarking experiments on various estimators and RL tasks, focusing on their risk-return tradeoff. These experiments offer several interesting directions and suggestions for future OPE research.
SCOPE-RL: A Python Library for Offline Reinforcement Learning and Off-Policy Evaluation
Dec 04, 2023
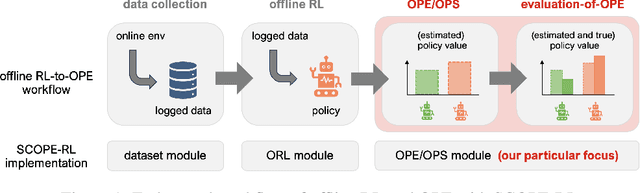
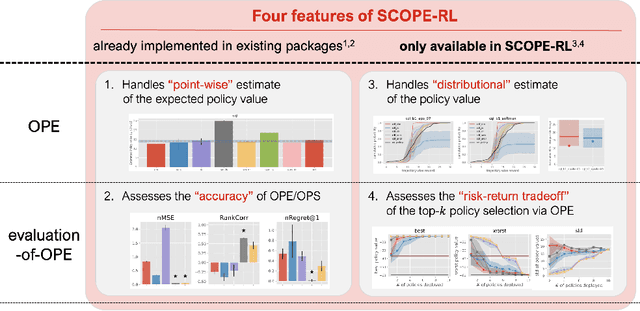

This paper introduces SCOPE-RL, a comprehensive open-source Python software designed for offline reinforcement learning (offline RL), off-policy evaluation (OPE), and selection (OPS). Unlike most existing libraries that focus solely on either policy learning or evaluation, SCOPE-RL seamlessly integrates these two key aspects, facilitating flexible and complete implementations of both offline RL and OPE processes. SCOPE-RL put particular emphasis on its OPE modules, offering a range of OPE estimators and robust evaluation-of-OPE protocols. This approach enables more in-depth and reliable OPE compared to other packages. For instance, SCOPE-RL enhances OPE by estimating the entire reward distribution under a policy rather than its mere point-wise expected value. Additionally, SCOPE-RL provides a more thorough evaluation-of-OPE by presenting the risk-return tradeoff in OPE results, extending beyond mere accuracy evaluations in existing OPE literature. SCOPE-RL is designed with user accessibility in mind. Its user-friendly APIs, comprehensive documentation, and a variety of easy-to-follow examples assist researchers and practitioners in efficiently implementing and experimenting with various offline RL methods and OPE estimators, tailored to their specific problem contexts. The documentation of SCOPE-RL is available at https://scope-rl.readthedocs.io/en/latest/.
An IPW-based Unbiased Ranking Metric in Two-sided Markets
Jul 14, 2023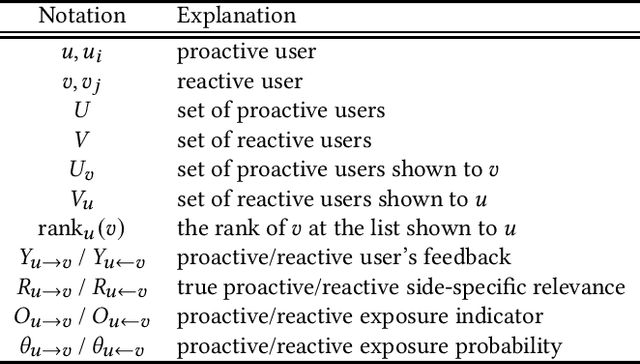
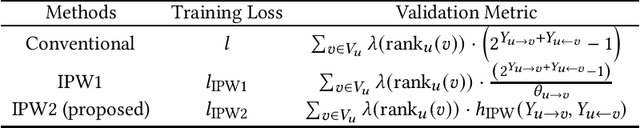


In modern recommendation systems, unbiased learning-to-rank (LTR) is crucial for prioritizing items from biased implicit user feedback, such as click data. Several techniques, such as Inverse Propensity Weighting (IPW), have been proposed for single-sided markets. However, less attention has been paid to two-sided markets, such as job platforms or dating services, where successful conversions require matching preferences from both users. This paper addresses the complex interaction of biases between users in two-sided markets and proposes a tailored LTR approach. We first present a formulation of feedback mechanisms in two-sided matching platforms and point out that their implicit feedback may include position bias from both user groups. On the basis of this observation, we extend the IPW estimator and propose a new estimator, named two-sided IPW, to address the position bases in two-sided markets. We prove that the proposed estimator satisfies the unbiasedness for the ground-truth ranking metric. We conducted numerical experiments on real-world two-sided platforms and demonstrated the effectiveness of our proposed method in terms of both precision and robustness. Our experiments showed that our method outperformed baselines especially when handling rare items, which are less frequently observed in the training data.
Solving Large Break Minimization Problems in a Mirrored Double Round-robin Tournament Using Quantum Annealing
Oct 18, 2021
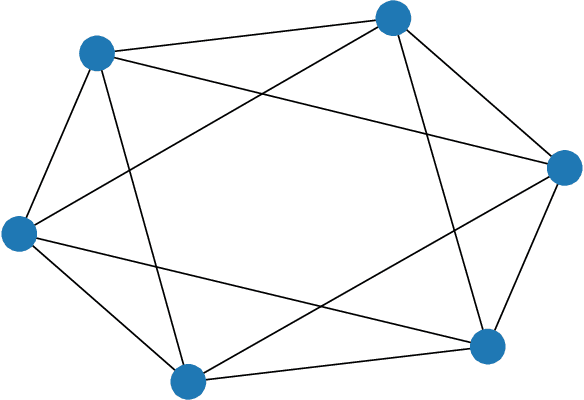
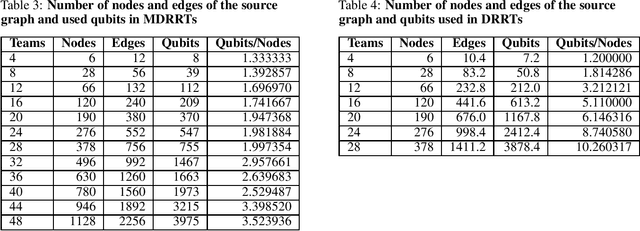
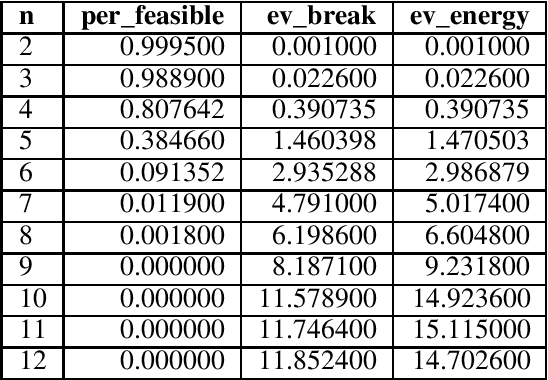
Quantum annealing (QA) has gained considerable attention because it can be applied to combinatorial optimization problems, which have numerous applications in logistics, scheduling, and finance. In recent years, research on solving practical combinatorial optimization problems using them has accelerated. However, researchers struggle to find practical combinatorial optimization problems, for which quantum annealers outperform other mathematical optimization solvers. Moreover, there are only a few studies that compare the performance of quantum annealers with one of the most sophisticated mathematical optimization solvers, such as Gurobi and CPLEX. In our study, we determine that QA demonstrates better performance than the solvers in the break minimization problem in a mirrored double round-robin tournament (MDRRT). We also explain the desirable performance of QA for the sparse interaction between variables and a problem without constraints. In this process, we demonstrate that the break minimization problem in an MDRRT can be expressed as a 4-regular graph. Through computational experiments, we solve this problem using our QA approach and two-integer programming approaches, which were performed using the latest quantum annealer D-Wave Advantage, and the sophisticated mathematical optimization solver, Gurobi, respectively. Further, we compare the quality of the solutions and the computational time. QA was able to determine the exact solution in 0.05 seconds for problems with 20 teams, which is a practical size. In the case of 36 teams, it took 84.8 s for the integer programming method to reach the objective function value, which was obtained by the quantum annealer in 0.05 s. These results not only present the break minimization problem in an MDRRT as an example of applying QA to practical optimization problems, but also contribute to find problems that can be effectively solved by QA.
Online Trading Models in the Forex Market Considering Transaction Costs
Jun 06, 2021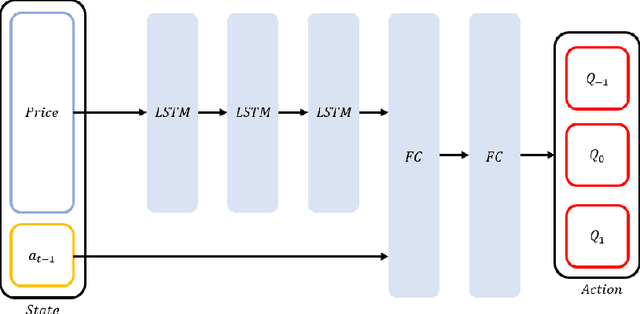
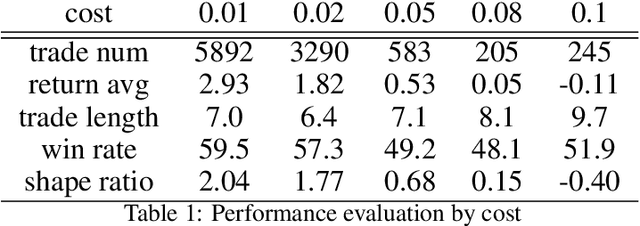
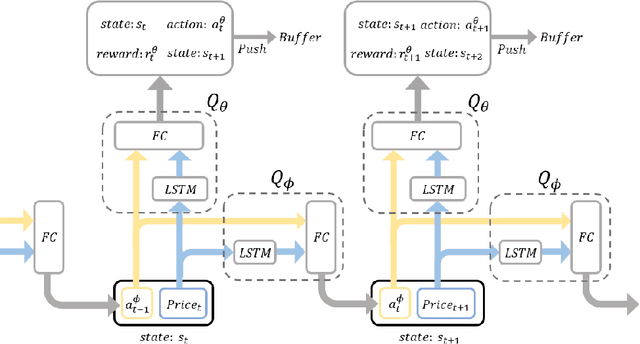

In recent years, a wide range of investment models have been created using artificial intelligence. Automatic trading by artificial intelligence can expand the range of trading methods, such as by conferring the ability to operate 24 hours a day and the ability to trade with high frequency. Automatic trading can also be expected to trade with more information than is available to humans if it can sufficiently consider past data. In this paper, we propose an investment agent based on a deep reinforcement learning model, which is an artificial intelligence model. The model considers the transaction costs involved in actual trading and creates a framework for trading over a long period of time so that it can make a large profit on a single trade. In doing so, it can maximize the profit while keeping transaction costs low. In addition, in consideration of actual operations, we use online learning so that the system can continue to learn by constantly updating the latest online data instead of learning with static data. This makes it possible to trade in non-stationary financial markets by always incorporating current market trend information.
Constrained Generalized Additive 2 Model with Consideration of High-Order Interactions
Jun 05, 2021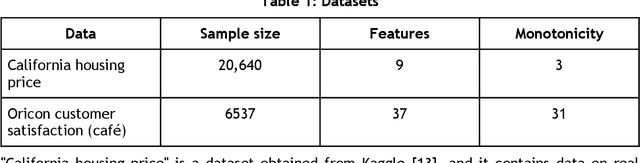
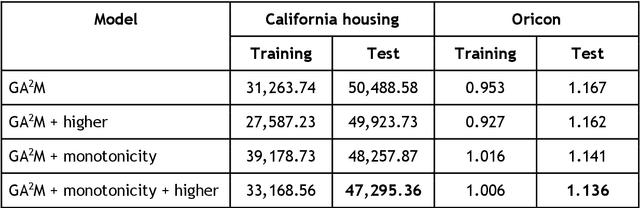
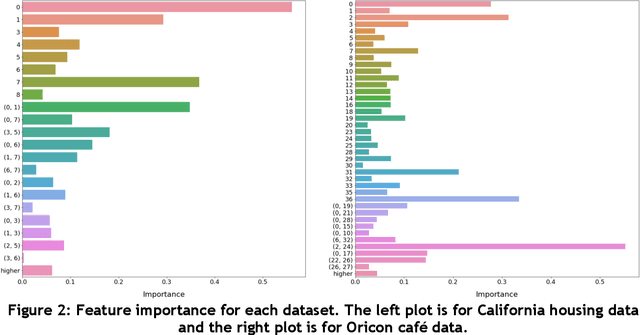
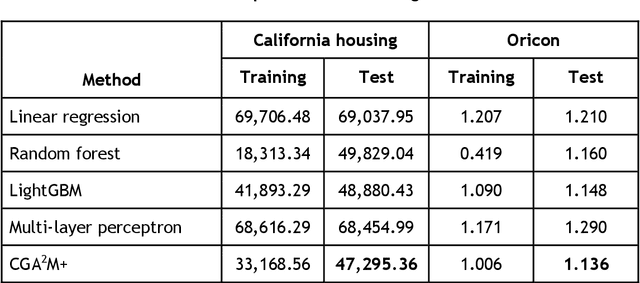
In recent years, machine learning and AI have been introduced in many industrial fields. In fields such as finance, medicine, and autonomous driving, where the inference results of a model may have serious consequences, high interpretability as well as prediction accuracy is required. In this study, we propose CGA2M+, which is based on the Generalized Additive 2 Model (GA2M) and differs from it in two major ways. The first is the introduction of monotonicity. Imposing monotonicity on some functions based on an analyst's knowledge is expected to improve not only interpretability but also generalization performance. The second is the introduction of a higher-order term: given that GA2M considers only second-order interactions, we aim to balance interpretability and prediction accuracy by introducing a higher-order term that can capture higher-order interactions. In this way, we can improve prediction performance without compromising interpretability by applying learning innovation. Numerical experiments showed that the proposed model has high predictive performance and interpretability. Furthermore, we confirmed that generalization performance is improved by introducing monotonicity.
Technical Progress Analysis Using a Dynamic Topic Model for Technical Terms to Revise Patent Classification Codes
Dec 18, 2020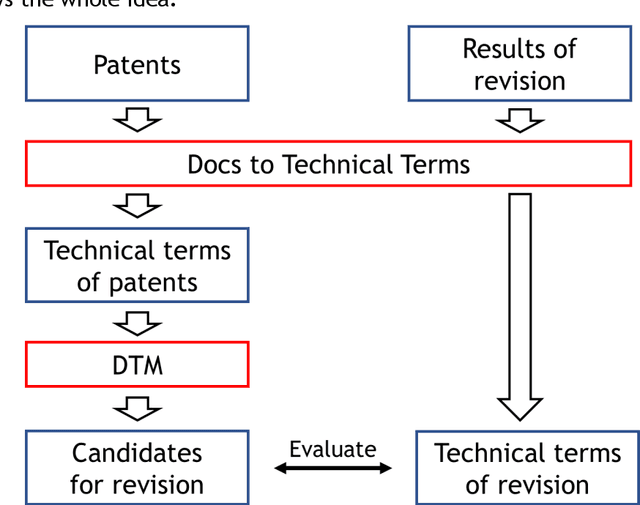
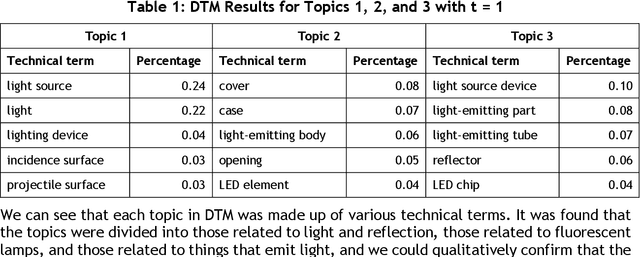
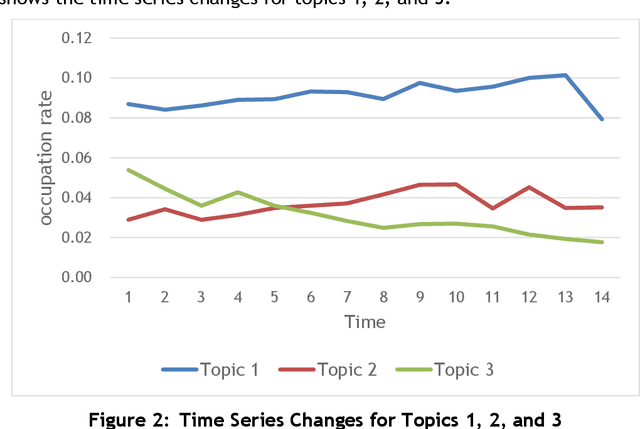
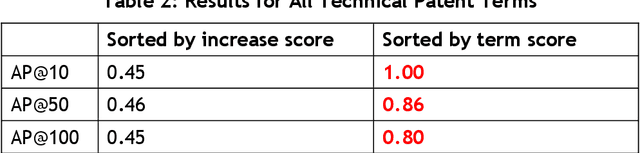
Japanese patents are assigned a patent classification code, FI (File Index), that is unique to Japan. FI is a subdivision of the IPC, an international patent classification code, that is related to Japanese technology. FIs are revised to keep up with technological developments. These revisions have already established more than 30,000 new FIs since 2006. However, these revisions require a lot of time and workload. Moreover, these revisions are not automated and are thus inefficient. Therefore, using machine learning to assist in the revision of patent classification codes (FI) will lead to improved accuracy and efficiency. This study analyzes patent documents from this new perspective of assisting in the revision of patent classification codes with machine learning. To analyze time-series changes in patents, we used the dynamic topic model (DTM), which is an extension of the latent Dirichlet allocation (LDA). Also, unlike English, the Japanese language requires morphological analysis. Patents contain many technical words that are not used in everyday life, so morphological analysis using a common dictionary is not sufficient. Therefore, we used a technique for extracting technical terms from text. After extracting technical terms, we applied them to DTM. In this study, we determined the technological progress of the lighting class F21 for 14 years and compared it with the actual revision of patent classification codes. In other words, we extracted technical terms from Japanese patents and applied DTM to determine the progress of Japanese technology. Then, we analyzed the results from the new perspective of revising patent classification codes with machine learning. As a result, it was found that those whose topics were on the rise were judged to be new technologies.
Relevance Matrix Factorization
Sep 09, 2019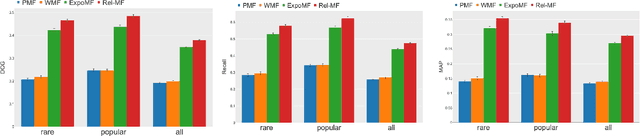
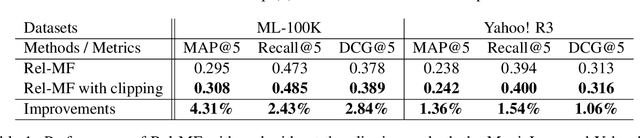
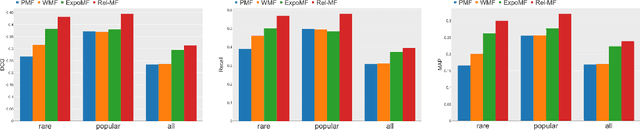
Implicit feedback plays a critical role to construct recommender systems because this type of feedback is prevalent in the real-world. However, effectively utilizing implicit feedback is challenging because of positive-unlabeled or missing-not-at-random problems. To tackle these challenges, in this paper, we first show that existing approaches are biased toward the true metric. Subsequently, we provide a theoretically principled approach to handle the problems inspired by estimation methods in causal inference. In particular, we propose an unbiased estimator for the true metric of interest solving the above problems simultaneously. Experiments on two standard real-world datasets demonstrate the superiority of the proposed approach against state-of-the-art recommendation algorithms.