 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTechnical Progress Analysis Using a Dynamic Topic Model for Technical Terms to Revise Patent Classification Codes
Paper and Code
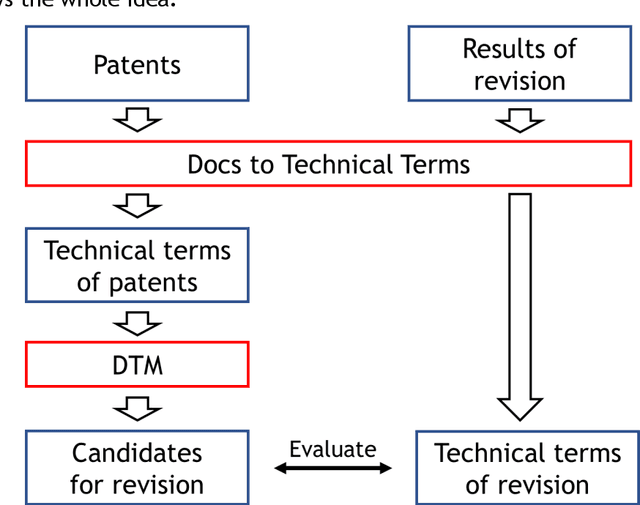
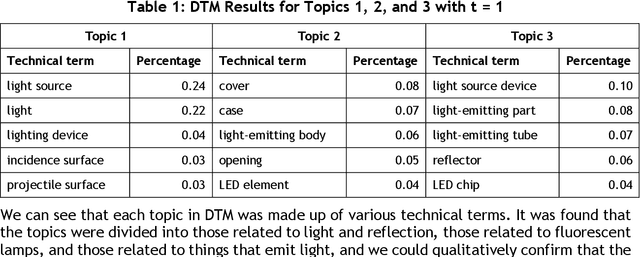
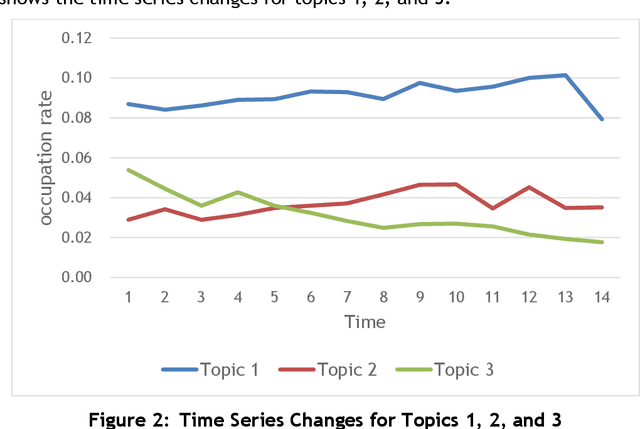
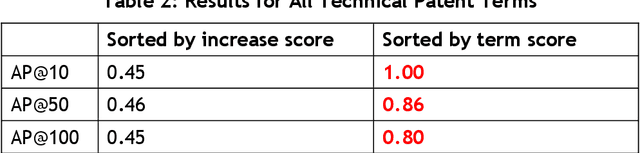
Japanese patents are assigned a patent classification code, FI (File Index), that is unique to Japan. FI is a subdivision of the IPC, an international patent classification code, that is related to Japanese technology. FIs are revised to keep up with technological developments. These revisions have already established more than 30,000 new FIs since 2006. However, these revisions require a lot of time and workload. Moreover, these revisions are not automated and are thus inefficient. Therefore, using machine learning to assist in the revision of patent classification codes (FI) will lead to improved accuracy and efficiency. This study analyzes patent documents from this new perspective of assisting in the revision of patent classification codes with machine learning. To analyze time-series changes in patents, we used the dynamic topic model (DTM), which is an extension of the latent Dirichlet allocation (LDA). Also, unlike English, the Japanese language requires morphological analysis. Patents contain many technical words that are not used in everyday life, so morphological analysis using a common dictionary is not sufficient. Therefore, we used a technique for extracting technical terms from text. After extracting technical terms, we applied them to DTM. In this study, we determined the technological progress of the lighting class F21 for 14 years and compared it with the actual revision of patent classification codes. In other words, we extracted technical terms from Japanese patents and applied DTM to determine the progress of Japanese technology. Then, we analyzed the results from the new perspective of revising patent classification codes with machine learning. As a result, it was found that those whose topics were on the rise were judged to be new technologies.