 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMachine Learning-Based Self-Localization Using Internal Sensors for Automating Bulldozers
Jun 08, 2025Self-localization is an important technology for automating bulldozers. Conventional bulldozer self-localization systems rely on RTK-GNSS (Real Time Kinematic-Global Navigation Satellite Systems). However, RTK-GNSS signals are sometimes lost in certain mining conditions. Therefore, self-localization methods that do not depend on RTK-GNSS are required. In this paper, we propose a machine learning-based self-localization method for bulldozers. The proposed method consists of two steps: estimating local velocities using a machine learning model from internal sensors, and incorporating these estimates into an Extended Kalman Filter (EKF) for global localization. We also created a novel dataset for bulldozer odometry and conducted experiments across various driving scenarios, including slalom, excavation, and driving on slopes. The result demonstrated that the proposed self-localization method suppressed the accumulation of position errors compared to kinematics-based methods, especially when slip occurred. Furthermore, this study showed that bulldozer-specific sensors, such as blade position sensors and hydraulic pressure sensors, contributed to improving self-localization accuracy.
CatCMA with Margin: Stochastic Optimization for Continuous, Integer, and Categorical Variables
Apr 10, 2025This study focuses on mixed-variable black-box optimization (MV-BBO), addressing continuous, integer, and categorical variables. Many real-world MV-BBO problems involve dependencies among these different types of variables, requiring efficient methods to optimize them simultaneously. Recently, stochastic optimization methods leveraging the mechanism of the covariance matrix adaptation evolution strategy have shown promising results in mixed-integer or mixed-category optimization. However, such methods cannot handle the three types of variables simultaneously. In this study, we propose CatCMA with Margin (CatCMAwM), a stochastic optimization method for MV-BBO that jointly optimizes continuous, integer, and categorical variables. CatCMAwM is developed by incorporating a novel integer handling into CatCMA, a mixed-category black-box optimization method employing a joint distribution of multivariate Gaussian and categorical distributions. The proposed integer handling is carefully designed by reviewing existing integer handlings and following the design principles of CatCMA. Even when applied to mixed-integer problems, it stabilizes the marginal probability and improves the convergence performance of continuous variables. Numerical experiments show that CatCMAwM effectively handles the three types of variables, outperforming state-of-the-art Bayesian optimization methods and baselines that simply incorporate existing integer handlings into CatCMA.
Bandit-Based Prompt Design Strategy Selection Improves Prompt Optimizers
Mar 03, 2025Prompt optimization aims to search for effective prompts that enhance the performance of large language models (LLMs). Although existing prompt optimization methods have discovered effective prompts, they often differ from sophisticated prompts carefully designed by human experts. Prompt design strategies, representing best practices for improving prompt performance, can be key to improving prompt optimization. Recently, a method termed the Autonomous Prompt Engineering Toolbox (APET) has incorporated various prompt design strategies into the prompt optimization process. In APET, the LLM is needed to implicitly select and apply the appropriate strategies because prompt design strategies can have negative effects. This implicit selection may be suboptimal due to the limited optimization capabilities of LLMs. This paper introduces Optimizing Prompts with sTrategy Selection (OPTS), which implements explicit selection mechanisms for prompt design. We propose three mechanisms, including a Thompson sampling-based approach, and integrate them into EvoPrompt, a well-known prompt optimizer. Experiments optimizing prompts for two LLMs, Llama-3-8B-Instruct and GPT-4o mini, were conducted using BIG-Bench Hard. Our results show that the selection of prompt design strategies improves the performance of EvoPrompt, and the Thompson sampling-based mechanism achieves the best overall results. Our experimental code is provided at https://github.com/shiralab/OPTS .
Warm Starting of CMA-ES for Contextual Optimization Problems
Feb 18, 2025Several practical applications of evolutionary computation possess objective functions that receive the design variables and externally given parameters. Such problems are termed contextual optimization problems. These problems require finding the optimal solutions corresponding to the given context vectors. Existing contextual optimization methods train a policy model to predict the optimal solution from context vectors. However, the performance of such models is limited by their representation ability. By contrast, warm starting methods have been used to initialize evolutionary algorithms on a given problem using the optimization results on similar problems. Because warm starting methods do not consider the context vectors, their performances can be improved on contextual optimization problems. Herein, we propose a covariance matrix adaptation evolution strategy with contextual warm starting (CMA-ES-CWS) to efficiently optimize the contextual optimization problem with a given context vector. The CMA-ES-CWS utilizes the optimization results of past context vectors to train the multivariate Gaussian process regression. Subsequently, the CMA-ES-CWS performs warm starting for a given context vector by initializing the search distribution using posterior distribution of the Gaussian process regression. The results of the numerical simulation suggest that CMA-ES-CWS outperforms the existing contextual optimization and warm starting methods.
CMA-ES for Discrete and Mixed-Variable Optimization on Sets of Points
Aug 23, 2024Discrete and mixed-variable optimization problems have appeared in several real-world applications. Most of the research on mixed-variable optimization considers a mixture of integer and continuous variables, and several integer handlings have been developed to inherit the optimization performance of the continuous optimization methods to mixed-integer optimization. In some applications, acceptable solutions are given by selecting possible points in the disjoint subspaces. This paper focuses on the optimization on sets of points and proposes an optimization method by extending the covariance matrix adaptation evolution strategy (CMA-ES), termed the CMA-ES on sets of points (CMA-ES-SoP). The CMA-ES-SoP incorporates margin correction that maintains the generation probability of neighboring points to prevent premature convergence to a specific non-optimal point, which is an effective integer-handling technique for CMA-ES. In addition, because margin correction with a fixed margin value tends to increase the marginal probabilities for a portion of neighboring points more than necessary, the CMA-ES-SoP updates the target margin value adaptively to make the average of the marginal probabilities close to a predefined target probability. Numerical simulations demonstrated that the CMA-ES-SoP successfully optimized the optimization problems on sets of points, whereas the naive CMA-ES failed to optimize them due to premature convergence.
Tail Bounds on the Runtime of Categorical Compact Genetic Algorithm
Jul 10, 2024

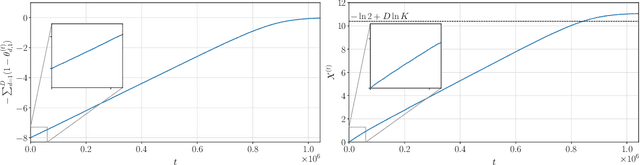

The majority of theoretical analyses of evolutionary algorithms in the discrete domain focus on binary optimization algorithms, even though black-box optimization on the categorical domain has a lot of practical applications. In this paper, we consider a probabilistic model-based algorithm using the family of categorical distributions as its underlying distribution and set the sample size as two. We term this specific algorithm the categorical compact genetic algorithm (ccGA). The ccGA can be considered as an extension of the compact genetic algorithm (cGA), which is an efficient binary optimization algorithm. We theoretically analyze the dependency of the number of possible categories $K$, the number of dimensions $D$, and the learning rate $\eta$ on the runtime. We investigate the tail bound of the runtime on two typical linear functions on the categorical domain: categorical OneMax (COM) and KVal. We derive that the runtimes on COM and KVal are $O(\sqrt{D} \ln (DK) / \eta)$ and $\Theta(D \ln K/ \eta)$ with high probability, respectively. Our analysis is a generalization for that of the cGA on the binary domain.
Natural Gradient Interpretation of Rank-One Update in CMA-ES
Jun 24, 2024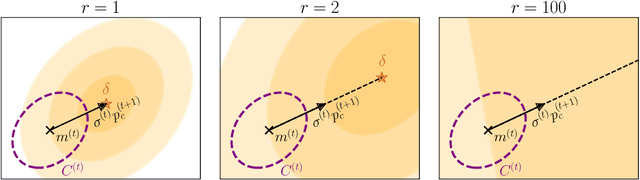

The covariance matrix adaptation evolution strategy (CMA-ES) is a stochastic search algorithm using a multivariate normal distribution for continuous black-box optimization. In addition to strong empirical results, part of the CMA-ES can be described by a stochastic natural gradient method and can be derived from information geometric optimization (IGO) framework. However, there are some components of the CMA-ES, such as the rank-one update, for which the theoretical understanding is limited. While the rank-one update makes the covariance matrix to increase the likelihood of generating a solution in the direction of the evolution path, this idea has been difficult to formulate and interpret as a natural gradient method unlike the rank-$\mu$ update. In this work, we provide a new interpretation of the rank-one update in the CMA-ES from the perspective of the natural gradient with prior distribution. First, we propose maximum a posteriori IGO (MAP-IGO), which is the IGO framework extended to incorporate a prior distribution. Then, we derive the rank-one update from the MAP-IGO by setting the prior distribution based on the idea that the promising mean vector should exist in the direction of the evolution path. Moreover, the newly derived rank-one update is extensible, where an additional term appears in the update for the mean vector. We empirically investigate the properties of the additional term using various benchmark functions.
CMA-ES with Adaptive Reevaluation for Multiplicative Noise
May 19, 2024The covariance matrix adaptation evolution strategy (CMA-ES) is a powerful optimization method for continuous black-box optimization problems. Several noise-handling methods have been proposed to bring out the optimization performance of the CMA-ES on noisy objective functions. The adaptations of the population size and the learning rate are two major approaches that perform well under additive Gaussian noise. The reevaluation technique is another technique that evaluates each solution multiple times. In this paper, we discuss the difference between those methods from the perspective of stochastic relaxation that considers the maximization of the expected utility function. We derive that the set of maximizers of the noise-independent utility, which is used in the reevaluation technique, certainly contains the optimal solution, while the noise-dependent utility, which is used in the population size and leaning rate adaptations, does not satisfy it under multiplicative noise. Based on the discussion, we develop the reevaluation adaptation CMA-ES (RA-CMA-ES), which computes two update directions using half of the evaluations and adapts the number of reevaluations based on the estimated correlation of those two update directions. The numerical simulation shows that the RA-CMA-ES outperforms the comparative method under multiplicative noise, maintaining competitive performance under additive noise.
CMA-ES for Safe Optimization
May 17, 2024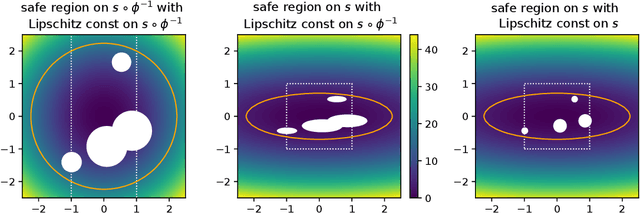
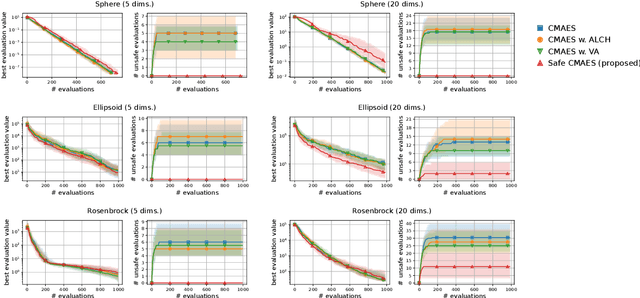
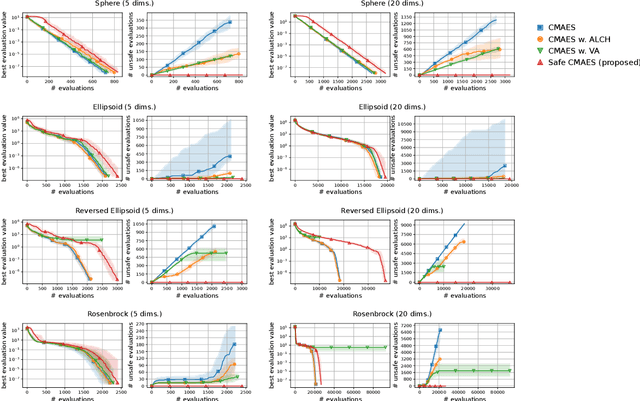
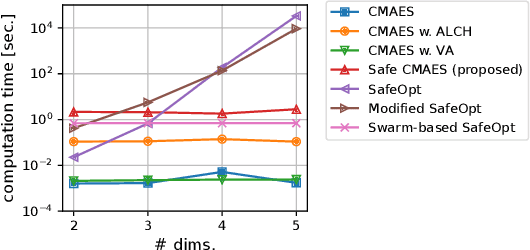
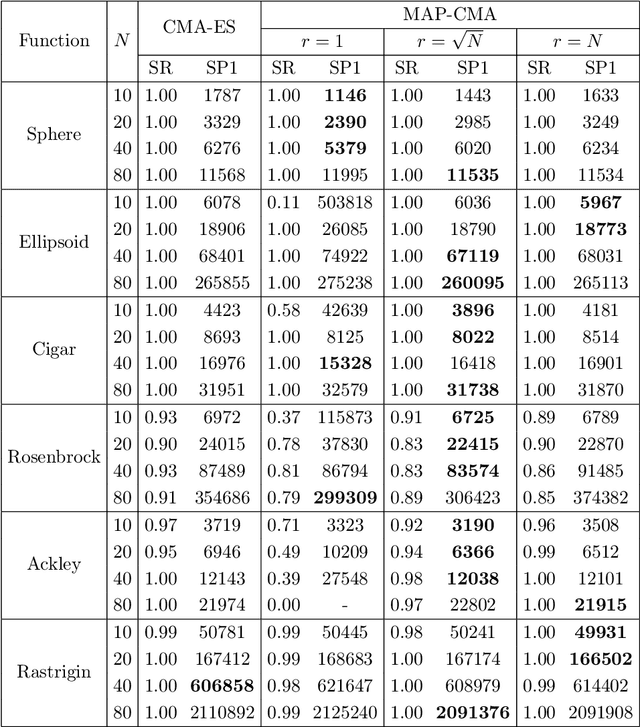
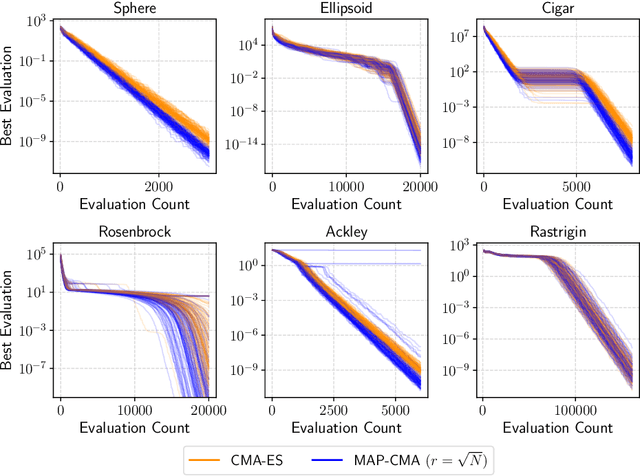
In several real-world applications in medical and control engineering, there are unsafe solutions whose evaluations involve inherent risk. This optimization setting is known as safe optimization and formulated as a specialized type of constrained optimization problem with constraints for safety functions. Safe optimization requires performing efficient optimization without evaluating unsafe solutions. A few studies have proposed the optimization methods for safe optimization based on Bayesian optimization and the evolutionary algorithm. However, Bayesian optimization-based methods often struggle to achieve superior solutions, and the evolutionary algorithm-based method fails to effectively reduce unsafe evaluations. This study focuses on CMA-ES as an efficient evolutionary algorithm and proposes an optimization method termed safe CMA-ES. The safe CMA-ES is designed to achieve both safety and efficiency in safe optimization. The safe CMA-ES estimates the Lipschitz constants of safety functions transformed with the distribution parameters using the maximum norm of the gradient in Gaussian process regression. Subsequently, the safe CMA-ES projects the samples to the nearest point in the safe region constructed with the estimated Lipschitz constants. The numerical simulation using the benchmark functions shows that the safe CMA-ES successfully performs optimization, suppressing the unsafe evaluations, while the existing methods struggle to significantly reduce the unsafe evaluations.
CatCMA : Stochastic Optimization for Mixed-Category Problems
May 16, 2024Black-box optimization problems often require simultaneously optimizing different types of variables, such as continuous, integer, and categorical variables. Unlike integer variables, categorical variables do not necessarily have a meaningful order, and the discretization approach of continuous variables does not work well. Although several Bayesian optimization methods can deal with mixed-category black-box optimization (MC-BBO), they suffer from a lack of scalability to high-dimensional problems and internal computational cost. This paper proposes CatCMA, a stochastic optimization method for MC-BBO problems, which employs the joint probability distribution of multivariate Gaussian and categorical distributions as the search distribution. CatCMA updates the parameters of the joint probability distribution in the natural gradient direction. CatCMA also incorporates the acceleration techniques used in the covariance matrix adaptation evolution strategy (CMA-ES) and the stochastic natural gradient method, such as step-size adaptation and learning rate adaptation. In addition, we restrict the ranges of the categorical distribution parameters by margin to prevent premature convergence and analytically derive a promising margin setting. Numerical experiments show that the performance of CatCMA is superior and more robust to problem dimensions compared to state-of-the-art Bayesian optimization algorithms.