 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Mixture Autoregressive Image Generative Model on Quadtree Regions for Gaussian Noise Removal via Variational Bayes and Gradient Methods
May 12, 2026This paper addresses the problem of image denoising for grayscale images. We propose a probabilistic image generative model that combines a quadtree region-partitioning model with a mixture autoregressive model, and propose a framework that reduces MAP (maximum a posteriori)-estimation-based denoising to the maximization of a variational lower bound. To maximize this lower bound, we develop an algorithm that alternately applies variational Bayes and gradient methods. We particularly demonstrate that the gradient-based update rule can be computed analytically without numerical computation or approximation. We carried out some experiments to verify that the proposed algorithm actually removes image noise and to identify directions for future improvement.
Variable Splitting Binary Tree Models Based on Bayesian Context Tree Models for Time Series Segmentation
Jan 22, 2026We propose a variable splitting binary tree (VSBT) model based on Bayesian context tree (BCT) models for time series segmentation. Unlike previous applications of BCT models, the tree structure in our model represents interval partitioning on the time domain. Moreover, interval partitioning is represented by recursive logistic regression models. By adjusting logistic regression coefficients, our model can represent split positions at arbitrary locations within each interval. This enables more compact tree representations. For simultaneous estimation of both split positions and tree depth, we develop an effective inference algorithm that combines local variational approximation for logistic regression with the context tree weighting (CTW) algorithm. We present numerical examples on synthetic data demonstrating the effectiveness of our model and algorithm.
Soft Bayesian Context Tree Models for Real-Valued Time Series
Jan 16, 2026This paper proposes the soft Bayesian context tree model (Soft-BCT), which is a novel BCT model for real-valued time series. The Soft-BCT considers soft (probabilistic) splits of the context space, instead of hard (deterministic) splits of the context space as in the previous BCT for real-valued time series. A learning algorithm of the Soft-BCT is proposed based on the variational inference. For some real-world datasets, the Soft-BCT demonstrates almost the same or superior performance to the previous BCT.
CatCMA with Margin: Stochastic Optimization for Continuous, Integer, and Categorical Variables
Apr 10, 2025This study focuses on mixed-variable black-box optimization (MV-BBO), addressing continuous, integer, and categorical variables. Many real-world MV-BBO problems involve dependencies among these different types of variables, requiring efficient methods to optimize them simultaneously. Recently, stochastic optimization methods leveraging the mechanism of the covariance matrix adaptation evolution strategy have shown promising results in mixed-integer or mixed-category optimization. However, such methods cannot handle the three types of variables simultaneously. In this study, we propose CatCMA with Margin (CatCMAwM), a stochastic optimization method for MV-BBO that jointly optimizes continuous, integer, and categorical variables. CatCMAwM is developed by incorporating a novel integer handling into CatCMA, a mixed-category black-box optimization method employing a joint distribution of multivariate Gaussian and categorical distributions. The proposed integer handling is carefully designed by reviewing existing integer handlings and following the design principles of CatCMA. Even when applied to mixed-integer problems, it stabilizes the marginal probability and improves the convergence performance of continuous variables. Numerical experiments show that CatCMAwM effectively handles the three types of variables, outperforming state-of-the-art Bayesian optimization methods and baselines that simply incorporate existing integer handlings into CatCMA.
CMA-ES for Discrete and Mixed-Variable Optimization on Sets of Points
Aug 23, 2024Discrete and mixed-variable optimization problems have appeared in several real-world applications. Most of the research on mixed-variable optimization considers a mixture of integer and continuous variables, and several integer handlings have been developed to inherit the optimization performance of the continuous optimization methods to mixed-integer optimization. In some applications, acceptable solutions are given by selecting possible points in the disjoint subspaces. This paper focuses on the optimization on sets of points and proposes an optimization method by extending the covariance matrix adaptation evolution strategy (CMA-ES), termed the CMA-ES on sets of points (CMA-ES-SoP). The CMA-ES-SoP incorporates margin correction that maintains the generation probability of neighboring points to prevent premature convergence to a specific non-optimal point, which is an effective integer-handling technique for CMA-ES. In addition, because margin correction with a fixed margin value tends to increase the marginal probabilities for a portion of neighboring points more than necessary, the CMA-ES-SoP updates the target margin value adaptively to make the average of the marginal probabilities close to a predefined target probability. Numerical simulations demonstrated that the CMA-ES-SoP successfully optimized the optimization problems on sets of points, whereas the naive CMA-ES failed to optimize them due to premature convergence.
CMA-ES for Safe Optimization
May 17, 2024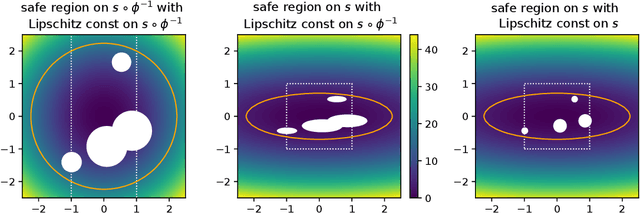
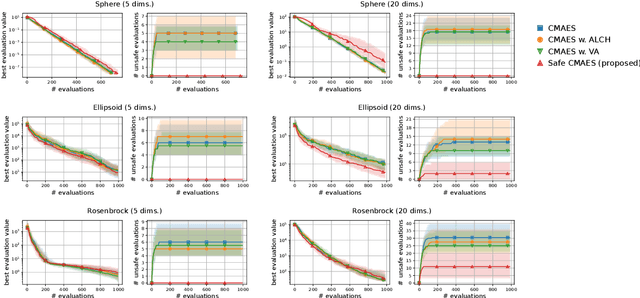
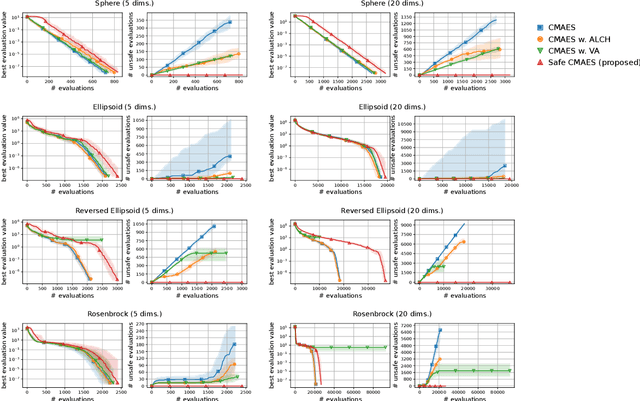
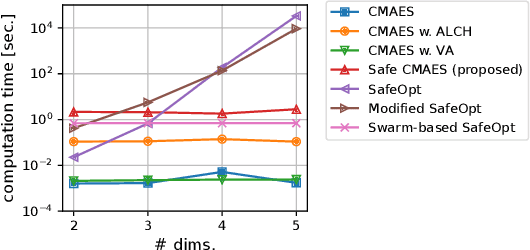
In several real-world applications in medical and control engineering, there are unsafe solutions whose evaluations involve inherent risk. This optimization setting is known as safe optimization and formulated as a specialized type of constrained optimization problem with constraints for safety functions. Safe optimization requires performing efficient optimization without evaluating unsafe solutions. A few studies have proposed the optimization methods for safe optimization based on Bayesian optimization and the evolutionary algorithm. However, Bayesian optimization-based methods often struggle to achieve superior solutions, and the evolutionary algorithm-based method fails to effectively reduce unsafe evaluations. This study focuses on CMA-ES as an efficient evolutionary algorithm and proposes an optimization method termed safe CMA-ES. The safe CMA-ES is designed to achieve both safety and efficiency in safe optimization. The safe CMA-ES estimates the Lipschitz constants of safety functions transformed with the distribution parameters using the maximum norm of the gradient in Gaussian process regression. Subsequently, the safe CMA-ES projects the samples to the nearest point in the safe region constructed with the estimated Lipschitz constants. The numerical simulation using the benchmark functions shows that the safe CMA-ES successfully performs optimization, suppressing the unsafe evaluations, while the existing methods struggle to significantly reduce the unsafe evaluations.
CatCMA : Stochastic Optimization for Mixed-Category Problems
May 16, 2024Black-box optimization problems often require simultaneously optimizing different types of variables, such as continuous, integer, and categorical variables. Unlike integer variables, categorical variables do not necessarily have a meaningful order, and the discretization approach of continuous variables does not work well. Although several Bayesian optimization methods can deal with mixed-category black-box optimization (MC-BBO), they suffer from a lack of scalability to high-dimensional problems and internal computational cost. This paper proposes CatCMA, a stochastic optimization method for MC-BBO problems, which employs the joint probability distribution of multivariate Gaussian and categorical distributions as the search distribution. CatCMA updates the parameters of the joint probability distribution in the natural gradient direction. CatCMA also incorporates the acceleration techniques used in the covariance matrix adaptation evolution strategy (CMA-ES) and the stochastic natural gradient method, such as step-size adaptation and learning rate adaptation. In addition, we restrict the ranges of the categorical distribution parameters by margin to prevent premature convergence and analytically derive a promising margin setting. Numerical experiments show that the performance of CatCMA is superior and more robust to problem dimensions compared to state-of-the-art Bayesian optimization algorithms.
Bandits with Abstention under Expert Advice
Feb 22, 2024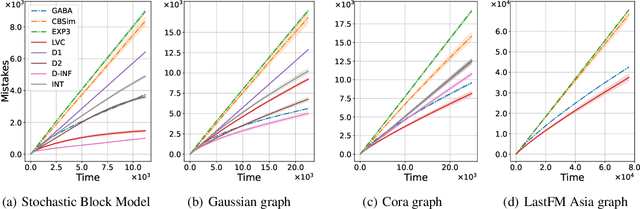
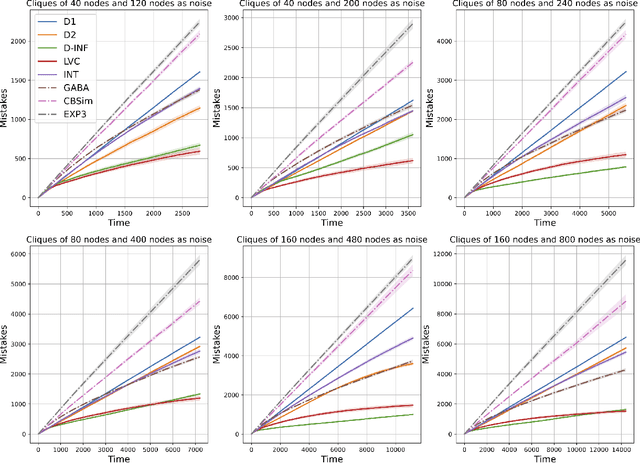
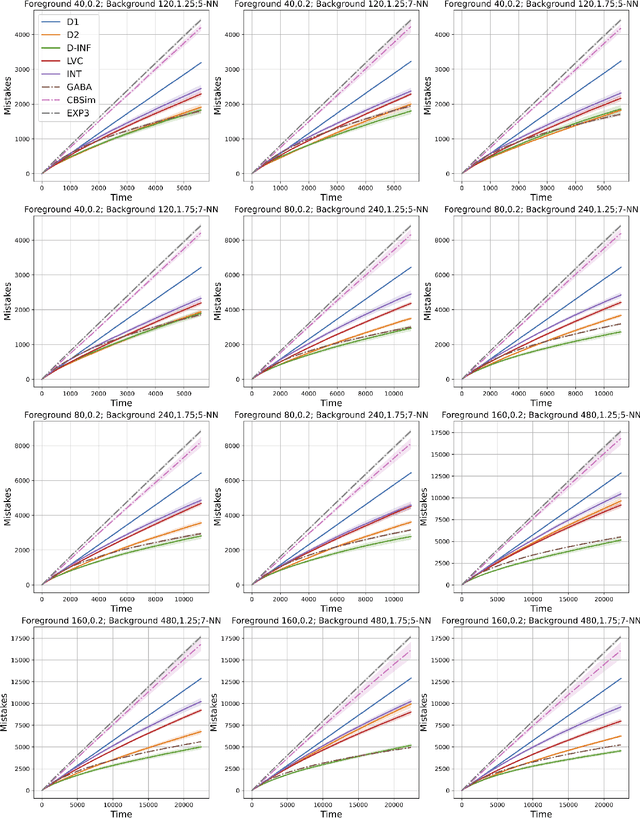
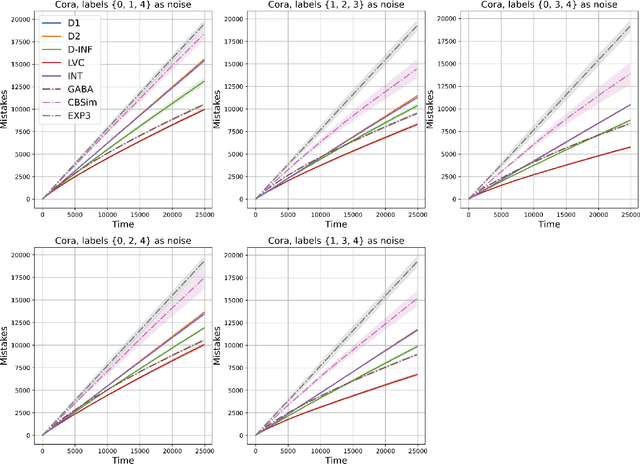
We study the classic problem of prediction with expert advice under bandit feedback. Our model assumes that one action, corresponding to the learner's abstention from play, has no reward or loss on every trial. We propose the CBA algorithm, which exploits this assumption to obtain reward bounds that can significantly improve those of the classical Exp4 algorithm. We can view our problem as the aggregation of confidence-rated predictors when the learner has the option of abstention from play. Importantly, we are the first to achieve bounds on the expected cumulative reward for general confidence-rated predictors. In the special case of specialists we achieve a novel reward bound, significantly improving previous bounds of SpecialistExp (treating abstention as another action). As an example application, we discuss learning unions of balls in a finite metric space. In this contextual setting, we devise an efficient implementation of CBA, reducing the runtime from quadratic to almost linear in the number of contexts. Preliminary experiments show that CBA improves over existing bandit algorithms.
Multi-class Graph Clustering via Approximated Effective $p$-Resistance
Jun 14, 2023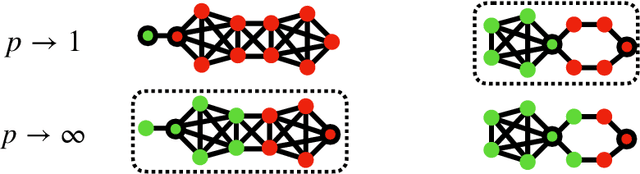
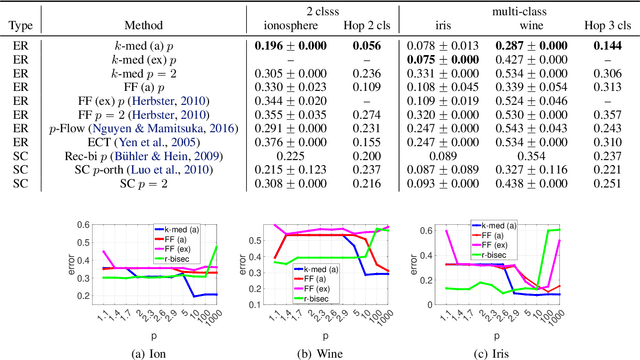
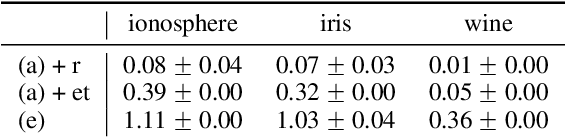
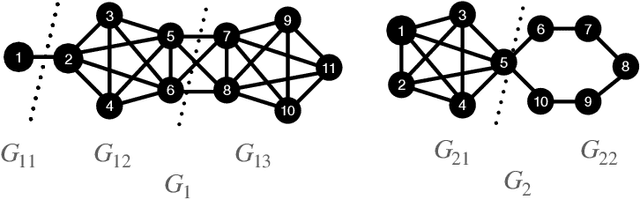
This paper develops an approximation to the (effective) $p$-resistance and applies it to multi-class clustering. Spectral methods based on the graph Laplacian and its generalization to the graph $p$-Laplacian have been a backbone of non-euclidean clustering techniques. The advantage of the $p$-Laplacian is that the parameter $p$ induces a controllable bias on cluster structure. The drawback of $p$-Laplacian eigenvector based methods is that the third and higher eigenvectors are difficult to compute. Thus, instead, we are motivated to use the $p$-resistance induced by the $p$-Laplacian for clustering. For $p$-resistance, small $p$ biases towards clusters with high internal connectivity while large $p$ biases towards clusters of small ``extent,'' that is a preference for smaller shortest-path distances between vertices in the cluster. However, the $p$-resistance is expensive to compute. We overcome this by developing an approximation to the $p$-resistance. We prove upper and lower bounds on this approximation and observe that it is exact when the graph is a tree. We also provide theoretical justification for the use of $p$-resistance for clustering. Finally, we provide experiments comparing our approximated $p$-resistance clustering to other $p$-Laplacian based methods.
Prediction Algorithms Achieving Bayesian Decision Theoretical Optimality Based on Decision Trees as Data Observation Processes
Jun 12, 2023In the field of decision trees, most previous studies have difficulty ensuring the statistical optimality of a prediction of new data and suffer from overfitting because trees are usually used only to represent prediction functions to be constructed from given data. In contrast, some studies, including this paper, used the trees to represent stochastic data observation processes behind given data. Moreover, they derived the statistically optimal prediction, which is robust against overfitting, based on the Bayesian decision theory by assuming a prior distribution for the trees. However, these studies still have a problem in computing this Bayes optimal prediction because it involves an infeasible summation for all division patterns of a feature space, which is represented by the trees and some parameters. In particular, an open problem is a summation with respect to combinations of division axes, i.e., the assignment of features to inner nodes of the tree. We solve this by a Markov chain Monte Carlo method, whose step size is adaptively tuned according to a posterior distribution for the trees.