 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline Minimization of Polarization and Disagreement via Low-Rank Matrix Bandits
Oct 01, 2025



We study the problem of minimizing polarization and disagreement in the Friedkin-Johnsen opinion dynamics model under incomplete information. Unlike prior work that assumes a static setting with full knowledge of users' innate opinions, we address the more realistic online setting where innate opinions are unknown and must be learned through sequential observations. This novel setting, which naturally mirrors periodic interventions on social media platforms, is formulated as a regret minimization problem, establishing a key connection between algorithmic interventions on social media platforms and theory of multi-armed bandits. In our formulation, a learner observes only a scalar feedback of the overall polarization and disagreement after an intervention. For this novel bandit problem, we propose a two-stage algorithm based on low-rank matrix bandits. The algorithm first performs subspace estimation to identify an underlying low-dimensional structure, and then employs a linear bandit algorithm within the compact dimensional representation derived from the estimated subspace. We prove that our algorithm achieves an $ \widetilde{O}(\sqrt{T}) $ cumulative regret over any time horizon $T$. Empirical results validate that our algorithm significantly outperforms a linear bandit baseline in terms of both cumulative regret and running time.
Multilayer Correlation Clustering
Apr 25, 2024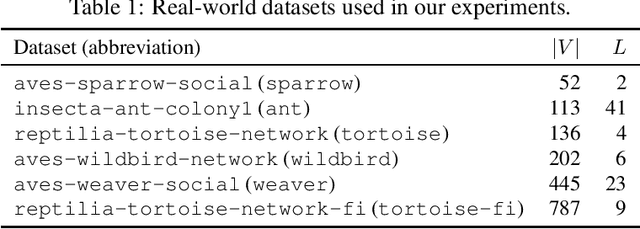
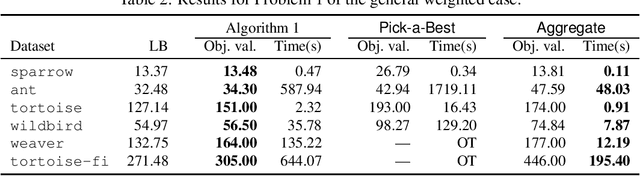

In this paper, we establish Multilayer Correlation Clustering, a novel generalization of Correlation Clustering (Bansal et al., FOCS '02) to the multilayer setting. In this model, we are given a series of inputs of Correlation Clustering (called layers) over the common set $V$. The goal is then to find a clustering of $V$ that minimizes the $\ell_p$-norm ($p\geq 1$) of the disagreements vector, which is defined as the vector (with dimension equal to the number of layers), each element of which represents the disagreements of the clustering on the corresponding layer. For this generalization, we first design an $O(L\log n)$-approximation algorithm, where $L$ is the number of layers, based on the well-known region growing technique. We then study an important special case of our problem, namely the problem with the probability constraint. For this case, we first give an $(\alpha+2)$-approximation algorithm, where $\alpha$ is any possible approximation ratio for the single-layer counterpart. For instance, we can take $\alpha=2.5$ in general (Ailon et al., JACM '08) and $\alpha=1.73+\epsilon$ for the unweighted case (Cohen-Addad et al., FOCS '23). Furthermore, we design a $4$-approximation algorithm, which improves the above approximation ratio of $\alpha+2=4.5$ for the general probability-constraint case. Computational experiments using real-world datasets demonstrate the effectiveness of our proposed algorithms.
Bandits with Abstention under Expert Advice
Feb 22, 2024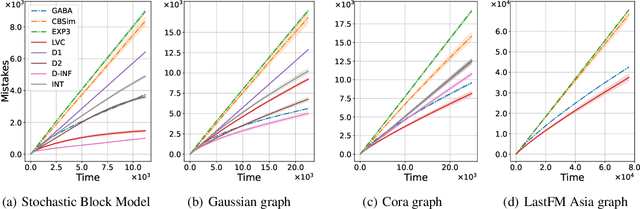
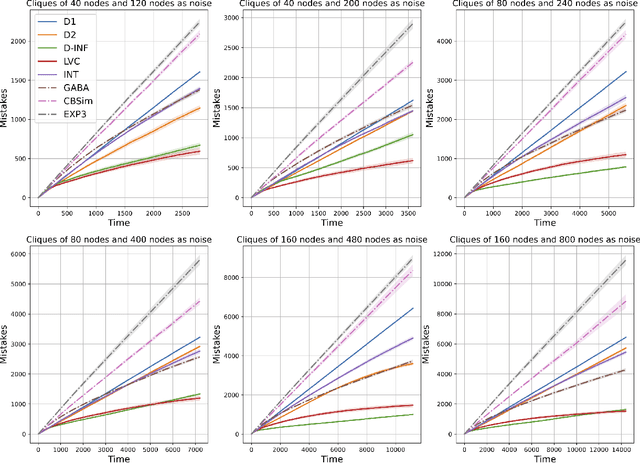
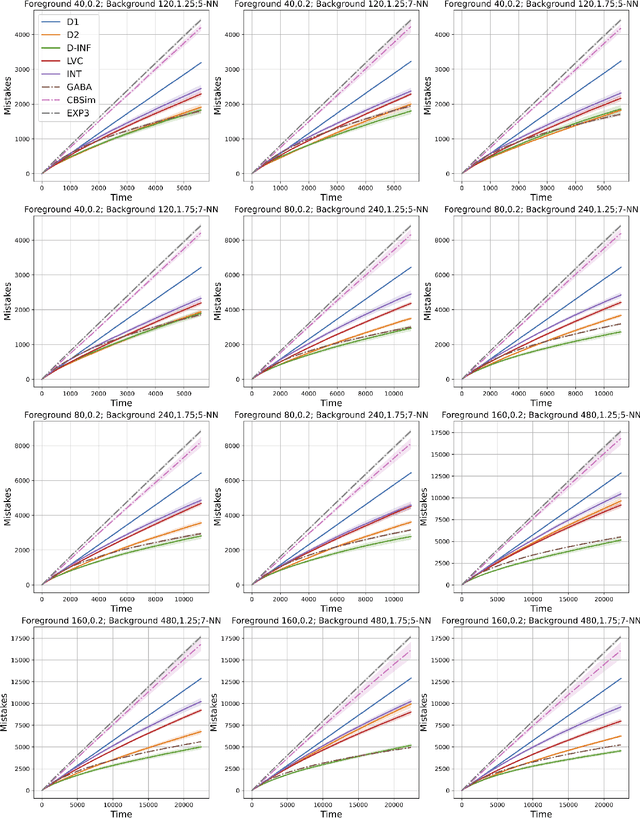
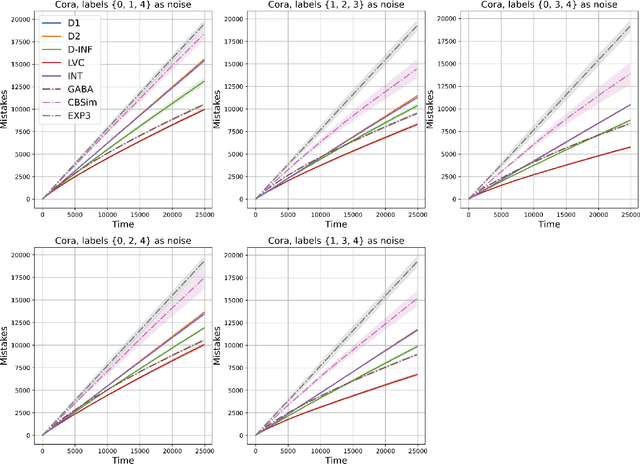
We study the classic problem of prediction with expert advice under bandit feedback. Our model assumes that one action, corresponding to the learner's abstention from play, has no reward or loss on every trial. We propose the CBA algorithm, which exploits this assumption to obtain reward bounds that can significantly improve those of the classical Exp4 algorithm. We can view our problem as the aggregation of confidence-rated predictors when the learner has the option of abstention from play. Importantly, we are the first to achieve bounds on the expected cumulative reward for general confidence-rated predictors. In the special case of specialists we achieve a novel reward bound, significantly improving previous bounds of SpecialistExp (treating abstention as another action). As an example application, we discuss learning unions of balls in a finite metric space. In this contextual setting, we devise an efficient implementation of CBA, reducing the runtime from quadratic to almost linear in the number of contexts. Preliminary experiments show that CBA improves over existing bandit algorithms.
Query-Efficient Correlation Clustering with Noisy Oracle
Feb 02, 2024



We study a general clustering setting in which we have $n$ elements to be clustered, and we aim to perform as few queries as possible to an oracle that returns a noisy sample of the similarity between two elements. Our setting encompasses many application domains in which the similarity function is costly to compute and inherently noisy. We propose two novel formulations of online learning problems rooted in the paradigm of Pure Exploration in Combinatorial Multi-Armed Bandits (PE-CMAB): fixed confidence and fixed budget settings. For both settings, we design algorithms that combine a sampling strategy with a classic approximation algorithm for correlation clustering and study their theoretical guarantees. Our results are the first examples of polynomial-time algorithms that work for the case of PE-CMAB in which the underlying offline optimization problem is NP-hard.
A Survey on the Densest Subgraph Problem and its Variants
Mar 25, 2023The Densest Subgraph Problem requires to find, in a given graph, a subset of vertices whose induced subgraph maximizes a measure of density. The problem has received a great deal of attention in the algorithmic literature over the last five decades, with many variants proposed and many applications built on top of this basic definition. Recent years have witnessed a revival of research interest on this problem with several interesting contributions, including some groundbreaking results, published in 2022 and 2023. This survey provides a deep overview of the fundamental results and an exhaustive coverage of the many variants proposed in the literature, with a special attention on the most recent results. The survey also presents a comprehensive overview of applications and discusses some interesting open problems for this evergreen research topic.
Online Dense Subgraph Discovery via Blurred-Graph Feedback
Jun 24, 2020
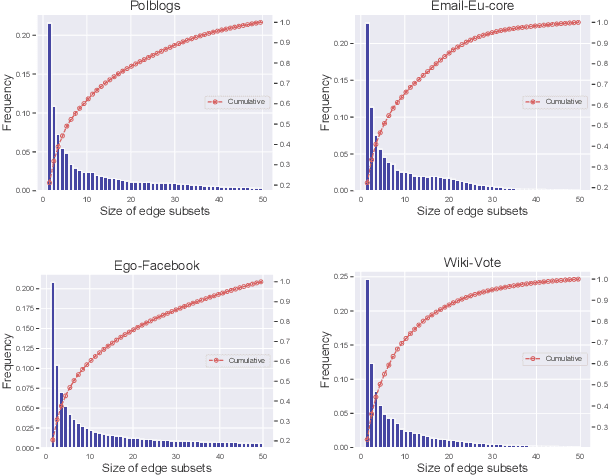


Dense subgraph discovery aims to find a dense component in edge-weighted graphs. This is a fundamental graph-mining task with a variety of applications and thus has received much attention recently. Although most existing methods assume that each individual edge weight is easily obtained, such an assumption is not necessarily valid in practice. In this paper, we introduce a novel learning problem for dense subgraph discovery in which a learner queries edge subsets rather than only single edges and observes a noisy sum of edge weights in a queried subset. For this problem, we first propose a polynomial-time algorithm that obtains a nearly-optimal solution with high probability. Moreover, to deal with large-sized graphs, we design a more scalable algorithm with a theoretical guarantee. Computational experiments using real-world graphs demonstrate the effectiveness of our algorithms.
Hypergraph Clustering Based on PageRank
Jun 15, 2020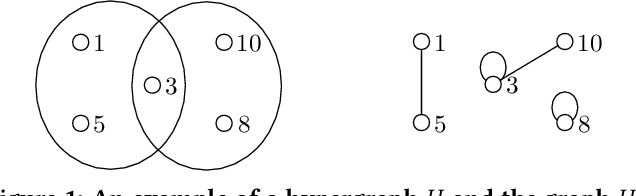
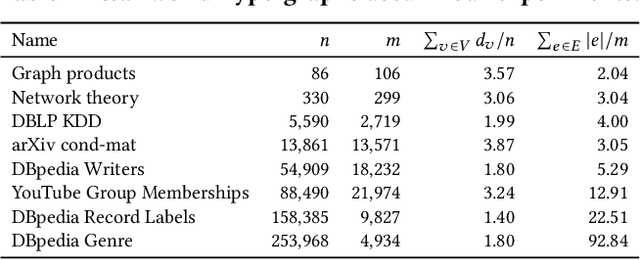
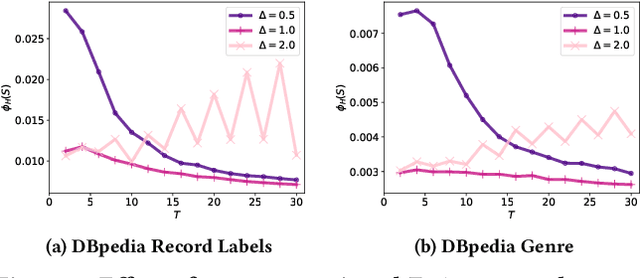
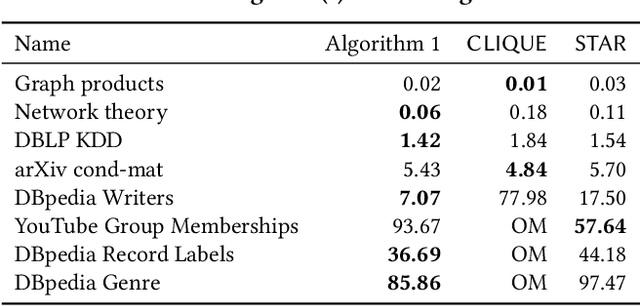
A hypergraph is a useful combinatorial object to model ternary or higher-order relations among entities. Clustering hypergraphs is a fundamental task in network analysis. In this study, we develop two clustering algorithms based on personalized PageRank on hypergraphs. The first one is local in the sense that its goal is to find a tightly connected vertex set with a bounded volume including a specified vertex. The second one is global in the sense that its goal is to find a tightly connected vertex set. For both algorithms, we discuss theoretical guarantees on the conductance of the output vertex set. Also, we experimentally demonstrate that our clustering algorithms outperform existing methods in terms of both the solution quality and running time. To the best of our knowledge, ours are the first practical algorithms for hypergraphs with theoretical guarantees on the conductance of the output set.
Graph Mining Meets Crowdsourcing: Extracting Experts for Answer Aggregation
May 17, 2019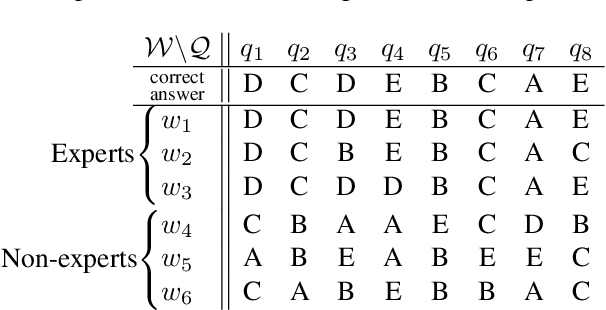
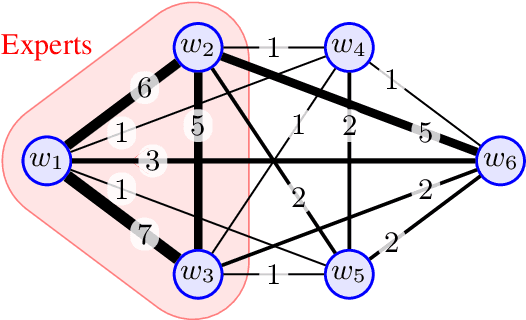
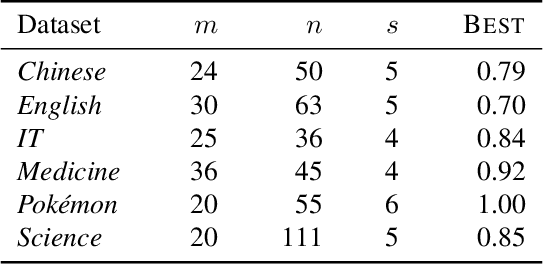
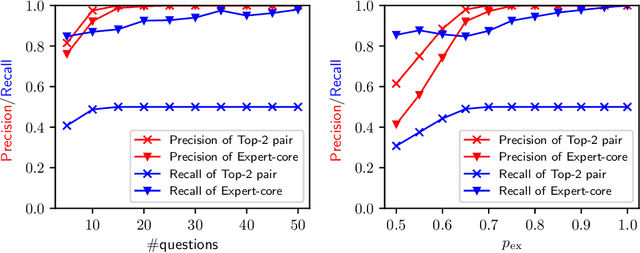
Aggregating responses from crowd workers is a fundamental task in the process of crowdsourcing. In cases where a few experts are overwhelmed by a large number of non-experts, most answer aggregation algorithms such as the majority voting fail to identify the correct answers. Therefore, it is crucial to extract reliable experts from the crowd workers. In this study, we introduce the notion of "expert core", which is a set of workers that is very unlikely to contain a non-expert. We design a graph-mining-based efficient algorithm that exactly computes the expert core. To answer the aggregation task, we propose two types of algorithms. The first one incorporates the expert core into existing answer aggregation algorithms such as the majority voting, whereas the second one utilizes information provided by the expert core extraction algorithm pertaining to the reliability of workers. We then give a theoretical justification for the first type of algorithm. Computational experiments using synthetic and real-world datasets demonstrate that our proposed answer aggregation algorithms outperform state-of-the-art algorithms.
Polynomial-time Algorithms for Combinatorial Pure Exploration with Full-bandit Feedback
Feb 27, 2019



We study the problem of stochastic combinatorial pure exploration (CPE), where an agent sequentially pulls a set of single arms (a.k.a. a super arm) and tries to find the best super arm. Among a variety of problem settings of the CPE, we focus on the full-bandit setting, where we cannot observe the reward of each single arm, but only the sum of the rewards. Although we can regard the CPE with full-bandit feedback as a special case of pure exploration in linear bandits, an approach based on linear bandits is not computationally feasible since the number of super arms may be exponential. In this paper, we first propose a polynomial-time bandit algorithm for the CPE under general combinatorial constraints and provide an upper bound of the sample complexity. Second, we design an approximation algorithm for the 0-1 quadratic maximization problem, which arises in many bandit algorithms with confidence ellipsoids. Based on our approximation algorithm, we propose novel bandit algorithms for the top-k selection problem, and prove that our algorithms run in polynomial time. Finally, we conduct experiments on synthetic and real-world datasets, and confirm the validity of our theoretical analysis in terms of both the computation time and the sample complexity.