 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalyzing the effect of prediction accuracy on the distributionally-robust competitive ratio
Jan 11, 2026The field of algorithms with predictions aims to improve algorithm performance by integrating machine learning predictions into algorithm design. A central question in this area is how predictions can improve performance, and a key aspect of this analysis is the role of prediction accuracy. In this context, prediction accuracy is defined as a guaranteed probability that an instance drawn from the distribution belongs to the predicted set. As a performance measure that incorporates prediction accuracy, we focus on the distributionally-robust competitive ratio (DRCR), introduced by Sun et al.~(ICML 2024). The DRCR is defined as the expected ratio between the algorithm's cost and the optimal cost, where the expectation is taken over the worst-case instance distribution that satisfies the given prediction and accuracy requirement. A known structural property is that, for any fixed algorithm, the DRCR decreases linearly as prediction accuracy increases. Building on this result, we establish that the optimal DRCR value (i.e., the infimum over all algorithms) is a monotone and concave function of prediction accuracy. We further generalize the DRCR framework to a multiple-prediction setting and show that monotonicity and concavity are preserved in this setting. Finally, we apply our results to the ski rental problem, a benchmark problem in online optimization, to identify the conditions on prediction accuracies required for the optimal DRCR to attain a target value. Moreover, we provide a method for computing the critical accuracy, defined as the minimum accuracy required for the optimal DRCR to strictly improve upon the performance attainable without any accuracy guarantee.
Online Algorithms for Repeated Optimal Stopping: Achieving Both Competitive Ratio and Regret Bounds
Nov 06, 2025We study the repeated optimal stopping problem, which generalizes the classical optimal stopping problem with an unknown distribution to a setting where the same problem is solved repeatedly over $T$ rounds. In this framework, we aim to design algorithms that guarantee a competitive ratio in each round while also achieving sublinear regret across all rounds. Our primary contribution is a general algorithmic framework that achieves these objectives simultaneously for a wide array of repeated optimal stopping problems. The core idea is to dynamically select an algorithm for each round, choosing between two candidates: (1) an empirically optimal algorithm derived from the history of observations, and (2) a sample-based algorithm with a proven competitive ratio guarantee. Based on this approach, we design an algorithm that performs no worse than the baseline sample-based algorithm in every round, while ensuring that the total regret is bounded by $\tilde{O}(\sqrt{T})$. We demonstrate the broad applicability of our framework to canonical problems, including the prophet inequality, the secretary problem, and their variants under adversarial, random, and i.i.d. input models. For example, for the repeated prophet inequality problem, our method achieves a $1/2$-competitive ratio from the second round on and an $\tilde{O}(\sqrt{T})$ regret. Furthermore, we establish a regret lower bound of $\Omega(\sqrt{T})$ even in the i.i.d. model, confirming that our algorithm's performance is almost optimal with respect to the number of rounds.
Resource Allocation under the Latin Square Constraint
Jan 11, 2025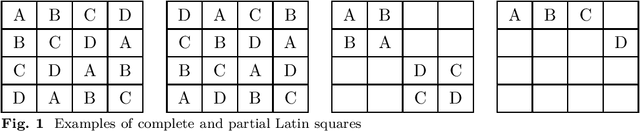
A Latin square is an $n \times n$ matrix filled with $n$ distinct symbols, each of which appears exactly once in each row and exactly once in each column. We introduce a problem of allocating $n$ indivisible items among $n$ agents over $n$ rounds while satisfying the Latin square constraint. This constraint ensures that each agent receives no more than one item per round and receives each item at most once. Each agent has an additive valuation on the item--round pairs. Real-world applications like scheduling, resource management, and experimental design require the Latin square constraint to satisfy fairness or balancedness in allocation. Our goal is to find a partial or complete allocation that maximizes the sum of the agents' valuations (utilitarian social welfare) or the minimum of the agents' valuations (egalitarian social welfare). For the problem of maximizing utilitarian social welfare, we prove NP-hardness even when the valuations are binary additive. We then provide $(1-1/e)$ and $(1-1/e)/4$-approximation algorithms for partial and complete settings, respectively. Additionally, we present fixed-parameter tractable (FPT) algorithms with respect to the order of Latin square and the optimum value for both partial and complete settings. For the problem of maximizing egalitarian social welfare, we establish that deciding whether the optimum value is at most $1$ or at least $2$ is NP-hard for both the partial and complete settings, even when the valuations are binary. Furthermore, we demonstrate that checking the existence of a complete allocation that satisfies each of envy-free, proportional, equitable, envy-free up to any good, proportional up to any good, or equitable up to any good is NP-hard, even when the valuations are identical.
Graph Mining Meets Crowdsourcing: Extracting Experts for Answer Aggregation
May 17, 2019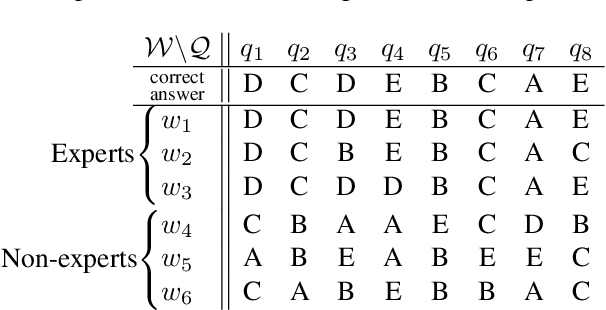
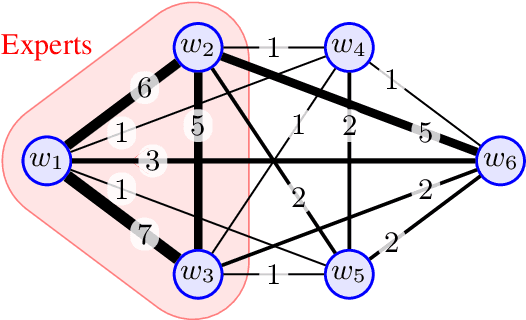
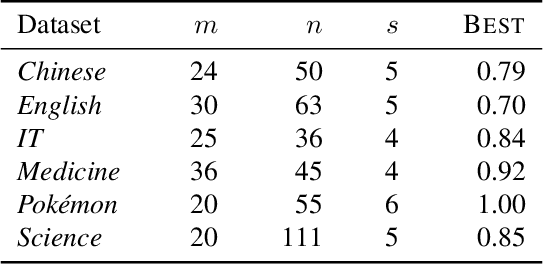
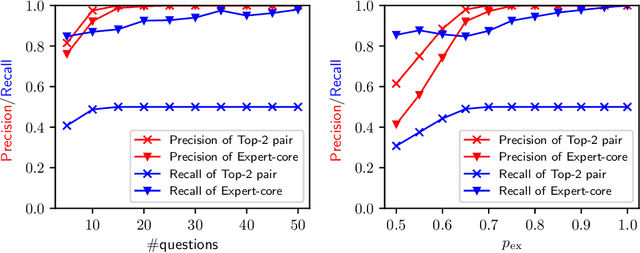
Aggregating responses from crowd workers is a fundamental task in the process of crowdsourcing. In cases where a few experts are overwhelmed by a large number of non-experts, most answer aggregation algorithms such as the majority voting fail to identify the correct answers. Therefore, it is crucial to extract reliable experts from the crowd workers. In this study, we introduce the notion of "expert core", which is a set of workers that is very unlikely to contain a non-expert. We design a graph-mining-based efficient algorithm that exactly computes the expert core. To answer the aggregation task, we propose two types of algorithms. The first one incorporates the expert core into existing answer aggregation algorithms such as the majority voting, whereas the second one utilizes information provided by the expert core extraction algorithm pertaining to the reliability of workers. We then give a theoretical justification for the first type of algorithm. Computational experiments using synthetic and real-world datasets demonstrate that our proposed answer aggregation algorithms outperform state-of-the-art algorithms.