 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecomposition of Equivariant Maps via Invariant Maps: Application to Universal Approximation under Symmetry
Sep 25, 2024In this paper, we develop a theory about the relationship between invariant and equivariant maps with regard to a group $G$. We then leverage this theory in the context of deep neural networks with group symmetries in order to obtain novel insight into their mechanisms. More precisely, we establish a one-to-one relationship between equivariant maps and certain invariant maps. This allows us to reduce arguments for equivariant maps to those for invariant maps and vice versa. As an application, we propose a construction of universal equivariant architectures built from universal invariant networks. We, in turn, explain how the universal architectures arising from our construction differ from standard equivariant architectures known to be universal. Furthermore, we explore the complexity, in terms of the number of free parameters, of our models, and discuss the relation between invariant and equivariant networks' complexity. Finally, we also give an approximation rate for G-equivariant deep neural networks with ReLU activation functions for finite group G.
On the Number of Linear Functions Composing Deep Neural Network: Towards a Refined Definition of Neural Networks Complexity
Oct 23, 2020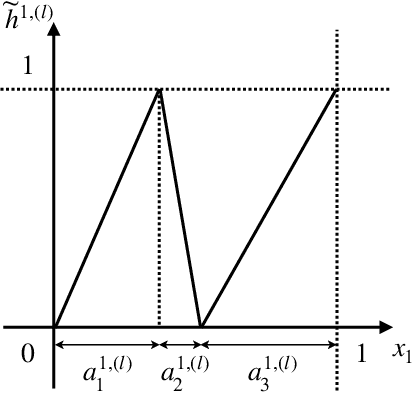
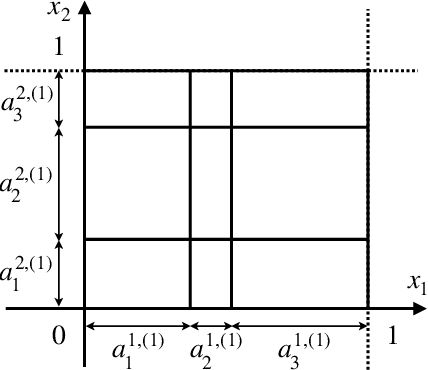
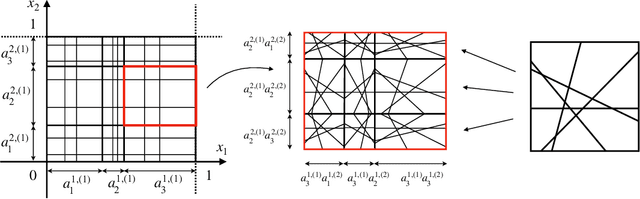
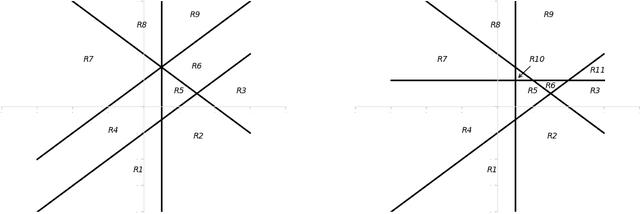
The classical approach to measure the expressive power of deep neural networks with piecewise linear activations is based on counting their maximum number of linear regions. However, when considering the two different models which are the fully connected and the permutation invariant ones, this measure is unable to distinguish them clearly in term of expressivity. To tackle this, we propose a refined definition of deep neural networks complexity. Instead of counting the number of linear regions directly, we first introduce an equivalence relation between the linear functions composing a DNN and then count those functions relatively to that equivalence relation. We continue with a study of our new complexity measure and verify that it has the good expected properties. It is able to distinguish clearly between the two models mentioned above, it is consistent with the classical measure, and it increases exponentially with depth. That last point confirms the high expressive power of deep networks.
Hypergraph Clustering Based on PageRank
Jun 15, 2020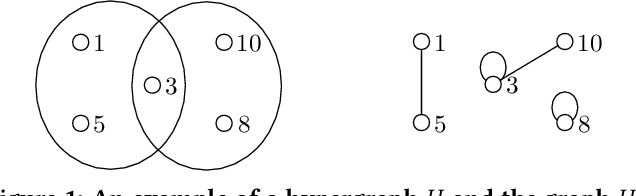
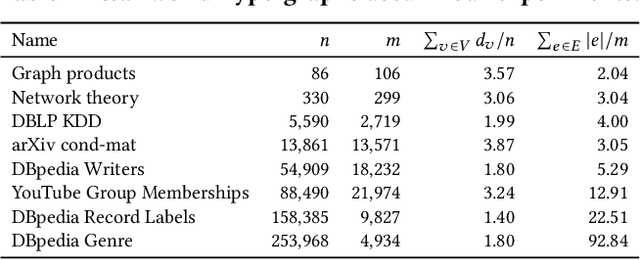
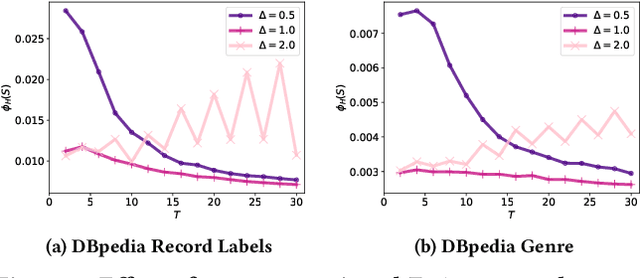
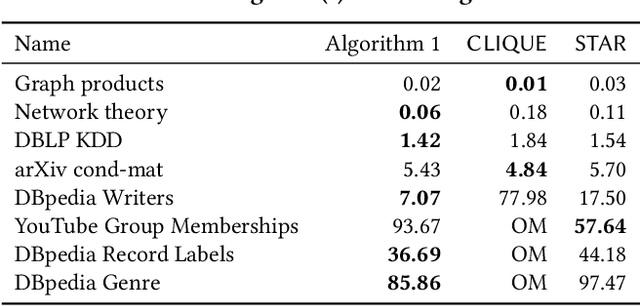
A hypergraph is a useful combinatorial object to model ternary or higher-order relations among entities. Clustering hypergraphs is a fundamental task in network analysis. In this study, we develop two clustering algorithms based on personalized PageRank on hypergraphs. The first one is local in the sense that its goal is to find a tightly connected vertex set with a bounded volume including a specified vertex. The second one is global in the sense that its goal is to find a tightly connected vertex set. For both algorithms, we discuss theoretical guarantees on the conductance of the output vertex set. Also, we experimentally demonstrate that our clustering algorithms outperform existing methods in terms of both the solution quality and running time. To the best of our knowledge, ours are the first practical algorithms for hypergraphs with theoretical guarantees on the conductance of the output set.
Universal approximations of permutation invariant/equivariant functions by deep neural networks
Mar 05, 2019In this paper,we develop a theory of the relationship between permutation ($S_n$-) invariant/equivariant functions and deep neural networks. As a result, we prove an permutation invariant/equivariant version of the universal approximation theorem, i.e $S_n$-invariant/equivariant deep neural networks. The equivariant models are consist of stacking standard single-layer neural networks $Z_i:X \to Y$ for which every $Z_i$ is $S_n$-equivariant with respect to the actions of $S_n$ . The invariant models are consist of stacking equivariant models and standard single-layer neural networks $Z_i:X \to Y$ for which every $Z_i$ is $S_n$-invariant with respect to the actions of $S_n$ . These are universal approximators to $S_n$-invariant/equivariant functions. The above notation is mathematically natural generalization of the models in \cite{deepsets}. We also calculate the number of free parameters appeared in these models. As a result, the number of free parameters appeared in these models is much smaller than the one of the usual models. Hence, we conclude that although the free parameters of the invariant/equivarint models are exponentially fewer than the one of the usual models, the invariant/equivariant models can approximate the invariant/equivariant functions to arbitrary accuracy. This gives us an understanding of why the invariant/equivariant models designed in [Zaheer et al. 2018] work well.